
Wikipedia:Reference desk/Computing: Difference between revisions
| Line 360: | Line 360: | ||
:: Thank you: when you say that "software needs to be [specially] written to take advantage of multiple cores", are you just talking about hyperthreading, meaning that if I were just running a SINGLE processor-intensive application, it needs to be written in that way? Or, are you talking about something more general? Because don't two concurrently running different applications AUTOMATICALLY get put on their own core by the OS? In that sense, my reasoning is informed by the "dual-processor" behavior I had learned of a few years ago. In fact, isn't a dual-core, logically, just 2 processors? Or, is there a substantial difference as seen by applications and the OS between a dual-core processor, and two processors each of which is exactly the same as a single core? (I don't mean difference in whether they access as much separate level-1 and level-2 cache, I mean as seen by the OS and applications). If there is a substantial difference, what is that difference? |
:: Thank you: when you say that "software needs to be [specially] written to take advantage of multiple cores", are you just talking about hyperthreading, meaning that if I were just running a SINGLE processor-intensive application, it needs to be written in that way? Or, are you talking about something more general? Because don't two concurrently running different applications AUTOMATICALLY get put on their own core by the OS? In that sense, my reasoning is informed by the "dual-processor" behavior I had learned of a few years ago. In fact, isn't a dual-core, logically, just 2 processors? Or, is there a substantial difference as seen by applications and the OS between a dual-core processor, and two processors each of which is exactly the same as a single core? (I don't mean difference in whether they access as much separate level-1 and level-2 cache, I mean as seen by the OS and applications). If there is a substantial difference, what is that difference? |
||
I guess my knowledge is not really up to date and what I would really like to know is the difference between multiple CPU's (dual and quad CPU machines) of yesteryear power desktops, and multiple cores of today? Thank you! [[Special:Contributions/84.153.205.142|84.153.205.142]] ([[User talk:84.153.205.142|talk]]) 16:48, 5 November 2010 (UTC) |
:: I guess my knowledge is not really up to date and what I would really like to know is the difference between multiple CPU's (dual and quad CPU machines) of yesteryear power desktops, and multiple cores of today? Thank you! [[Special:Contributions/84.153.205.142|84.153.205.142]] ([[User talk:84.153.205.142|talk]]) 16:48, 5 November 2010 (UTC) |
||
::::There hasn't been any change of definition (one possibly source of confusion is that sometimes a ''processor'' can have two separate ''physical chips'' within it, or one chip with two processors on it - both are as far as end results are concerned - the same...) |
::::There hasn't been any change of definition (one possibly source of confusion is that sometimes a ''processor'' can have two separate ''physical chips'' within it, or one chip with two processors on it - both are as far as end results are concerned - the same...) |
||
::::As per multiple processes on multiple cores or threads - yes you are right - the only time there isn't any advantage is when you run a single (non threaded) program on a multicore machine.[[Special:Contributions/94.72.205.11|94.72.205.11]] ([[User talk:94.72.205.11|talk]]) 16:54, 5 November 2010 (UTC) |
::::As per multiple processes on multiple cores or threads - yes you are right - the only time there isn't any advantage is when you run a single (non threaded) program on a multicore machine.[[Special:Contributions/94.72.205.11|94.72.205.11]] ([[User talk:94.72.205.11|talk]]) 16:54, 5 November 2010 (UTC) |
||
Revision as of 16:56, 5 November 2010
![]()
of the Wikipedia reference desk.
Main page: Help searching Wikipedia
How can I get my question answered?
- Select the section of the desk that best fits the general topic of your question (see the navigation column to the right).
- Post your question to only one section, providing a short header that gives the topic of your question.
- Type '~~~~' (that is, four tilde characters) at the end – this signs and dates your contribution so we know who wrote what and when.
- Don't post personal contact information – it will be removed. Any answers will be provided here.
- Please be as specific as possible, and include all relevant context – the usefulness of answers may depend on the context.
- Note:
- We don't answer (and may remove) questions that require medical diagnosis or legal advice.
- We don't answer requests for opinions, predictions or debate.
- We don't do your homework for you, though we'll help you past the stuck point.
- We don't conduct original research or provide a free source of ideas, but we'll help you find information you need.
How do I answer a question?
Main page: Wikipedia:Reference desk/Guidelines
- The best answers address the question directly, and back up facts with wikilinks and links to sources. Do not edit others' comments and do not give any medical or legal advice.
October 31
Multitasking OS - program memory allocation
(if specific - Windows) In a multitasking OS such as windows there can be numerous processess and programs running (using time division multitasking amongst other things I think) - what I don't understand is how memory is allocated between these processes/programs - specifically in terms of a stack.
eg A program might need a huge stack, but the size of the stack would be unknown before runtime.. My main question is - how are program stacks handled? one shared stack, or one stack per program in program memory space? What about if the stack gets really big? Does the processor have special features to detect stacks going outside a set space? I might need a windows memory organisation 101 lesson first.. where to look? Thanks.77.86.42.103 (talk) 00:02, 31 October 2010 (UTC)
- Windows Internals by Russinovich and Solomon is pretty good. There's one stack per thread (not per process); when a context switch occurs the stack-pointer is among the registers that get saved and restored. Different OSes handle allocation for the stack slightly differently (and I don't know offhand how Windows does it). Ideally a process would allocate so many pages of system memory for the stack; if a thread used more than that (e.g. it did some extensive recursive operation) then it runs off the end of the stack segment, causing a memory violation. The kernel responds by allocation more physical pages to the virtual memory space for the stack, amends its own tables marking the stack segment as having expanded, and returns control to the process. In practice this can go on for a while, but a sensible OS will limit the size to which a stack can grow (otherwise a trivial, defective program can consume all the memory by recursing itself) - a program that goes over its limit will be terminated. -- Finlay McWalter ☻ Talk 00:10, 31 October 2010 (UTC)
- Note that this the case for user space processes (that is, applications and services). How stacks work for kernel level "processes" and things like interrupt handlers is a rather difficult matter. -- Finlay McWalter ☻ Talk 00:25, 31 October 2010 (UTC)
- The Win32 Thread Information Block stores details about the current thread's stack size. Russinovich talks about the TIB several times, and says pages are allocated to it with a 64Kb granularity. -- Finlay McWalter ☻ Talk 00:23, 31 October 2010 (UTC)
- (follow on question to first part, still reading) Thanks that's what I was looking for. Question - "runs off the end of the stack segment, causing a memory violation" - is this detected by the processor? I assume it has to be .. what would be a good search term for the x86 or x64 implementation of this?
- also a minor question .. in Task Manager eg File:System idle process.png - in terms of the above answer - is each "process" shown in that windows program a "thread" or "process" - don't matter if not known - my question has been already mostly answered.77.86.42.103 (talk) 00:27, 31 October 2010 (UTC)
- Yes. The Global Descriptor Table stores Task State Segments which store the addresses of virtual memory blocks allocated to the process. Accessing memory outwith that allocated to you causes a protection fault, which is handled by the kernel. Although users are familiar with protection faults as program-killing errors, OSes which run on CPUs with memory management units also (transparently) use protection faults to implement growable stacks, copy-on-write, and handling of paging data and executables to and from disk/memory. -- Finlay McWalter ☻ Talk 00:34, 31 October 2010 (UTC)
- Regarding Task Manager - each thing it shows is a process, I believe. Some processes have many threads. Microsoft's Process Explorer (which Russinovich wrote) will, I think, show the threads within each process. It's a free download (and safe, given its source); if you're interested in how Windows works, it's a really interesting way to waste the rest of your evening. -- Finlay McWalter ☻ Talk 00:37, 31 October 2010 (UTC)
- Regarding books: apart from Russinovich (who I think will explain this only rather tangentially) it's difficult to recommend a decent book. The underlying technology is covered at length in the Intel Software Developer's Manuals, but those are written from a pretty low-level perspective, for people who already know how conceptually to write a virtual-memory subsystem and task switch handler. Probably the best thing I've read is McKusick's The Design and Implementation of the 4.4 BSD Operating System - really all (mainstream, non embedded, single-computer) operating systems work in much the same way. -- Finlay McWalter ☻ Talk 00:56, 31 October 2010 (UTC)
- Great Global Descriptor Table and Task State Segment almost certainly answer my initial question. I really didn't have a hope of finding it on my own. I agreee McKusicks book is good found it here - one of those works that makes me feel I could start writing an OS today, and probably have it finished in a couple of weeks .. :) 77.86.42.103 (talk) 01:18, 31 October 2010 (UTC)
Wireless modem capabilities
Can wireless modems generally be used to dial "information numbers" (i.e., things like this1) and send and receive text messages to perform an account's administrative tasks (e.g., refill balance, order services, etc.)? 125.163.228.155 (talk) 07:00, 31 October 2010 (UTC)
1) This is just an example. I am not an AT&T customer.
- (answering self) Well, after reading various wireless modems' user manuals, it quickly became apparent to me that most wireless modems are only capable of the following (at least from the modem's user interface, not accounting from writing AT commands directly):
- connecting to the Internet,
- sending and receiving text messages,
- "managing" the SIM/RUIM's inbox, outbox, and other *boxes, and
- "managing" the SIM/RUIM's contact list.
- So, in conclusion, unless I can do an account's maintenance tasks (activating the Internet service, checking account balance, refilling account balance, ordering data packages, etc.) solely through text, it is probably not a good idea to have a wireless modem without having a cell phone. 125.163.226.148 (talk) 00:42, 2 November 2010 (UTC)
Installing Starcraft 2 On Ubuntu Using Wine
My Vista computer completely crashed on me so I decided to install Ubuntu (I downloaded 10.10). I'm not really technically proficient, and all I plan to use my computer for is Internet, Word, Netbeans, and Starcraft 2. However, after installing wine and following the instructions here, when I try to run the installer I get the error message: " No installer data could be found. If this problem persists, please contact Blizzard Technical Support.".
Does anyone have any idea how I can resolve this? Secondly, since I downloaded Ubuntu I figure I should try to use some of this amazing functionality linux should let me have. However I feel kind of overwhelmed learning it. Does anyone have any suggestions on how I should go about learning to use ubuntu?
Thanks --66.133.196.152 (talk) 09:09, 31 October 2010 (UTC)
- Sorry if I sound annoying, but why not just go back to Windows? It should bring up no problems then, as most feature games are designed for Windows.General Rommel (talk) 09:48, 31 October 2010 (UTC)
- You do sound annoying, and this is not a helpful response at all. We've established many times over that "switch to X" is not an appropriate response when someone is asking for help with their current OS. It should frankly be removed.. --Mr.98 (talk) 11:48, 31 October 2010 (UTC)
- It's not half as annoying as when someone takes on the self-appointed role of policeman. 92.15.26.46 (talk) 15:30, 31 October 2010 (UTC)
- There are no policemen here, just other citizens. My right to criticize poor responses is as enshrined as your own. --Mr.98 (talk) 18:42, 31 October 2010 (UTC)
- I agree the response is poor, but one thing I would suggest is if you never actually tried Starcraft on Windows, and presuming you can relatively easily install it, consider a temporary copy. If the problem persists on Windows, you know it's probably not be Linux related and are free to contact Blizzard. Nil Einne (talk) 21:11, 31 October 2010 (UTC)
- And to Mr 98, I apoligize, however I have only been here for only a few times over this year and I believe that we should consider all possibilities, which colud also include going back to Windows. However, if Mr 98 disagrees you may bring it up on my talk page. General Rommel (talk) 21:29, 31 October 2010 (UTC)
- I agree the response is poor, but one thing I would suggest is if you never actually tried Starcraft on Windows, and presuming you can relatively easily install it, consider a temporary copy. If the problem persists on Windows, you know it's probably not be Linux related and are free to contact Blizzard. Nil Einne (talk) 21:11, 31 October 2010 (UTC)
- There are no policemen here, just other citizens. My right to criticize poor responses is as enshrined as your own. --Mr.98 (talk) 18:42, 31 October 2010 (UTC)
- It's not half as annoying as when someone takes on the self-appointed role of policeman. 92.15.26.46 (talk) 15:30, 31 October 2010 (UTC)
- You do sound annoying, and this is not a helpful response at all. We've established many times over that "switch to X" is not an appropriate response when someone is asking for help with their current OS. It should frankly be removed.. --Mr.98 (talk) 11:48, 31 October 2010 (UTC)
- Normally I, too, condemn recommendations of "switch to Windows / Mac OS / Linux" which are almost never helpful — but in this case, the original poster is a Windows user, using Windows Vista, who is not at all familiar with Linux, and is trying to play a Windows game. I think it's a good question why he doesn't reinstall Vista from scratch, under the circumstances. Comet Tuttle (talk) 15:36, 1 November 2010 (UTC)
- Some programs need a bunch of tweaks for Wine for it to play them properly. The Wine forums tend to have quite a bit on them, but that might be daunting for a new user. Instead try installing PlayOnLinux (it's in the package managment system, so you'll get it using Synaptic). It has a specific line item for Starcraft II - Wings of Liberty. In general the Wine Database is showing people are having "Gold" and "Platinum" results playing Starcraft II on Wine - see here. -- Finlay McWalter ☻ Talk 12:02, 31 October 2010 (UTC)
- I should clarify this - PlayOnLinux is a wrapper around Wine, providing a tailored "wine prefix" for an impressively wide range of programs - it's not a replacement for wine at all. -- Finlay McWalter ☻ Talk 12:30, 31 October 2010 (UTC)
- You might also consider Cedega which is a pay-for, closed-source, spin-off of Wine. However, I notice that their database lists the game as "works with issues", which in my experience usually means that the software runs but has some glitches that make playing the game frustratingly impossible. APL (talk) 15:58, 1 November 2010 (UTC)
Font ID

Can anyone help? :) ╟─TreasuryTag►constablewick─╢ 09:46, 31 October 2010 (UTC)
- Identifont has some ideas, but none of them look right to me -- the best matches don't even have an italic version. Paul (Stansifer) 12:24, 31 October 2010 (UTC)
- It looks to me like one of the standard fonts that used to be on Mac Systems 7-9, but the Fonts on Macintosh article doesn't really have on that matches up. It reminds me of Zapf Chancery but it is obviously not that. It has some resemblance to Bookman or Cheltenham, in the sense that both have sort of a "too filled, too big" look to them (to me, anyway) with similar flourishes at the ends of the letters, but neither of those are obviously the same one (they have different italic as, for example). --Mr.98 (talk) 18:40, 31 October 2010 (UTC)
- For what it's worth, I google-image-searched artscroll font and this link is probably from the same source and uses what appears to be the same font. Comet Tuttle (talk) 15:39, 1 November 2010 (UTC)
- I am no typographical expert, but the font really looks like ITC Benguiat® Book Italic. 125.163.226.148 (talk) 02:00, 2 November 2010 (UTC)
Error (?) in unit type article
I think there may be a significant error in our unit type article, but I'm not sure, and I don't think I'd get a response on the talk page, so I'm asking here, with a really long sentence.
According to our article, the unit type is the return type of functions that return no value. But consider the following proposition: "a function which returns no value can be changed to return a value without breaking anything else". Obviously, this should be true. This statement is equivalent to "a function type which has a return type is a subtype of the function type with the same argument types but no return type". Yet, if the unit type is the static return type of functions which return no value, this isn't true. The reason is that function return values are covariant, and whatever the return type of the function is, it's not a subtype of the unit type. The static unit type provides some information (its type), even though the runtime unit type doesn't.
The only type that provides no information whatsoever is the top type. So, to be pedantic correct, it seems like the article should say that the static return type of functions that return no useful information is the top type, and the actual value returned by such functions is (presumably) the unit.
To make this more concrete: functions from void to int cannot be substituted for functions from void to void. However, they can be substituted for functions from void to object.
So... am I right, and the article needs to be changed, or am I just completely off my rocker? Also, are there any actual programming languages with these semantics? « Aaron Rotenberg « Talk « 10:11, 31 October 2010 (UTC)
- I think you're mixing levels of function call. before you call a function (at least in a strictly typed language) you have to set up the receiving variable, which (if I'm understanding correctly) requires a separate 'unit type' function call. That separate function call can only return one value, and so in an 'information-theory' sense it returns no information; it just contextualizes the output of the real function. You can think of this the same way as in standard math. if you have a function like x/r^2 it makes no difference from the perspective of the function whether the unit type of x and r are 'kilograms and meters' or 'pounds and yards', and the unit types themselves don't really add any information that's of use to the function, they merely serve to contextualize the inputs and outputs for those that wish to use the function. The article's a little jargon-ish, but I don't think it's wrong. this is not really my specialty though. --Ludwigs2 18:03, 31 October 2010 (UTC)
- All types are subtypes of the unit type in the sense that there's a natural surjection t → unit for any t. Of course this can be lifted to a natural surjection (u → t) → (u → unit). Possibly what's confusing you (it confuses me) is that there are at least two different kinds of subtyping in programming languages: t ≤ u can mean t ⊆ u or it can mean t ≅ u ⊗ v for some v. What they have in common is a natural mapping from t to u, but it's an injection in one case and a surjection in the other. One could try to argue that the base object type of object-oriented languages counts is really the unit type, but in most real languages instances of that type have individual identity, so it's not a very good correspondence. As for a value of type unit conveying no information, one can say that a value of type t conveys log2 |t| bits of information (at least if |t| is finite), and it's in that sense that a unit return tells you nothing. -- BenRG (talk) 21:19, 31 October 2010 (UTC)
VLC
I want to test VLCs stream playback feature, but I can't find any urls to test. Does anyone know of some streams (free news channels or whatever it doesn't matter) that are video and audio for me to test? Thanks. 82.44.55.25 (talk) 17:33, 31 October 2010 (UTC)
- VLC will stream from YouTube. Just visit a normal YouTube playback page, copy the URL from the browser's location bar, and in VLC do media->openNetworkStream, and paste that URL in there. -- Finlay McWalter ☻ Talk 17:45, 31 October 2010 (UTC)
- You can play back KQED-FM's audio stream by opening http://www.kqed.org/radio/listen/kqedradio.m3u in VLC. -- Finlay McWalter ☻ Talk 17:47, 31 October 2010 (UTC)
- Thanks! 82.44.55.25 (talk) 17:52, 31 October 2010 (UTC)
Orange pop-up rectangles
What exactly is responsible for the orange pop-up rectangles when you move your cursor over things on the TV schedule page of www.radiotimes.com ? Java, Silverlight, what please? Thanks 92.24.186.230 (talk) 22:22, 31 October 2010 (UTC)
- It's JavaScript, similar to the overLIB library. ZX81 talk 22:40, 31 October 2010 (UTC)
- (edit conflict : Same answer) - include a bit of the code
- An example code piece is:
- <a href="/enwiki/ListingsServlet?event=10&channelId=26&programmeId=141455338&jspLocation=/jsp/prog_details_fullpage.jsp" onmouseover="return overlib('TALK SHOW <br /><b>Piers Morgan\'s Life Stories: Rod Stewart</b> <br /><b>ITV1 London</b> <br /> (12:15am - 1:05am)', FGCOLOR, '#ff9922');" onmouseout="return nd();" class="url">Piers Morgan's<br>Life Stories: Ro...</a>
- One of the key bits is the "onmouseover" event which is javascript - when the mouse goes over the thing it does a javascript function called "return overlib" which is described here http://www.bosrup.com/web/overlib/?Documentation
87.102.115.141 (talk) 22:43, 31 October 2010 (UTC)
Using the NoScript extension in Firefox
How do I adjust the options of the NoScript extension in Firefox so that it prevents things which may be intrusive, malicious, or anti-privacy; but which still allows most webpages pages to be run in a normal way? Thanks Edit: re-wording that, how can I adjust NoScript so that most webpages run normally, but inessential potentially unsafe things don't? 92.24.186.230 (talk) 22:28, 31 October 2010 (UTC)
- It is not possible to know what pages have malicious scripts. So, NoScript is designed to make it easy to allow scripts on pages you trust (even if your trust is misplaced). When you visit a site that has blocked scripts, NoScript will show you an alert. Click on the alert and you can select "Allow from xxxxxxx" where xxxxxx is one of the sites supplying scripts for the page. From that point on, you won't have blocked scripts from that source. -- kainaw™ 16:56, 1 November 2010 (UTC)
- It is not possible to know whether a script is malicious because the definition of "malware" is a matter of opinion. For example, I consider Google Analytics "malicious," (it steals my CPU resources to track my behaviors and report my usage statistics to an uninvolved third-party), so I disallow it from running client-side processing. Most people do not share my viewpoints. Malware is entirely subject to individual perceptions - what software do you want to permit to run on your computer? Some people choose to upload personally identifiable information to unknown third parties over unencrypted channels. Some people intentionally send their financial account information to strangers. For these people, automating the procedure with a script is not "malicious." NoScript does not attempt to differentiate amongst scripts based on "malicious intent." Instead, it blocks all scripts by default, and allows the individual to make exceptions. Nimur (talk) 20:43, 1 November 2010 (UTC)
- It's also subjective what constitutes an advertisement, but products like AdBlock exist anyway. I see no reason why a community-maintained Javascript block list for NoScript couldn't exist, but as far as I know it doesn't.
- NoScript can be configured to allow scripts by default instead of forbidding them by default. In that mode it still protects against cross-site scripting and clickjacking better than Firefox alone, or at least so it claims. But this would allow a lot of privacy-compromising scripts to run, so it probably isn't what you want. -- BenRG (talk) 21:22, 1 November 2010 (UTC)
Privacy browser
What browser (using Windows) preserves your privacy most, but which still allows normal internet surfing? Thanks 92.24.186.230 (talk) 22:31, 31 October 2010 (UTC)
- Firefox, with flashblock and cookieculler extensions, and saved form data and saved passwords disabled in prefs. I forget if HTML5 offline data is in play yet. ¦ Reisio (talk) 00:05, 1 November 2010 (UTC)
November 1
Unallocated space
Hi, I have an asus n61j series (n61jv-x2) computer with the following disk partitions. What is the unallocated space for? Any ideas? Am I supposed to leave it as it is? Thank you in advance. Kushal (talk) 02:45, 1 November 2010 (UTC)
- I can't think of any reason why you couldn't create/resize partitions to use that space. There are partition types that NT won't recognize (e.g. Linux ext3), but they wouldn't show up as "unallocated". -- BenRG (talk) 04:16, 1 November 2010 (UTC)
- Well, this computer has Geforce GT 325M and optimus won't work on Linux apparently. But that's for another day I guess. Kushal (talk) 14:09, 1 November 2010 (UTC)
- One current fashion (of manufacturers) is to split a hard disk into 2, one part for os and general, and the other half for a file archive. ie two drives on one disk - this looks like something similar - except it's been forgotten to actually create the archive drive..? 87.102.115.141 (talk) 09:10, 1 November 2010 (UTC)
- I would understand the scheme better if it was one partition for os and one for user data but what's the point of backing up on not just the same computer but on the same disk? I must be missing something... Maybe that's where the system restore data should go?
- No you're not missing much - it's not a particularily intelligent scheme.. they do do it though (the manufacturers) - I suppose if people back up somewhere it's better than nothing. (I think the computers come installed with an 'own brand' backup your directorys tool as well - to help) - the flaws are obvious, obviously.Sf5xeplus (talk) 10:08, 2 November 2010 (UTC)
- Many computers these days have an extra, hidden partition for system recovery, but that wouldn't show up as unallocated space (unless it had been deleted, in which case you might as well reuse the space). Also it wouldn't be 100+ GB, it would be 10 GB tops. -- BenRG (talk) 21:06, 1 November 2010 (UTC)
- That's what the recovery partition in the Alienware looks like. I am having networking trouble on the Asus and the computer did not come with a recovery disk (and apparently a recovery partition either). :/ Sad times Kushal (talk) 22:00, 2 November 2010 (UTC)
- I would understand the scheme better if it was one partition for os and one for user data but what's the point of backing up on not just the same computer but on the same disk? I must be missing something... Maybe that's where the system restore data should go?
- Is this a second-hand computer? Volumes encrypted with tools such as TrueCrypt may show up as unallocated space in disk management. (In that case, you might as well treat it as such, unless you can get the previous owner to reveal the password).
decltype(talk) 09:15, 1 November 2010 (UTC)- It is from warehouse deals fulfilled by amazon.com. :/ It was supposed to be in "used - mint" condition. I feel cheated. I hope the windows license sticker on the bottom of the computer will still work if I have to reinstall. Kushal (talk) 13:30, 1 November 2010 (UTC)
- From the disc management screenshot you gave, it looks like you should simply be able to extend the C: partition into the unallocated space. Right click on the C: partition and click "Extend Volume" (or something to that effect), and have it fill the remaining space.206.131.39.6 (talk) 15:24, 1 November 2010 (UTC)
- Note that, if memory serves, you actually have to right-click the letters "C:" and you can't right-click any of the fields off to its right (even on the same line). Comet Tuttle (talk) 15:41, 1 November 2010 (UTC)
- From the disc management screenshot you gave, it looks like you should simply be able to extend the C: partition into the unallocated space. Right click on the C: partition and click "Extend Volume" (or something to that effect), and have it fill the remaining space.206.131.39.6 (talk) 15:24, 1 November 2010 (UTC)
- It is from warehouse deals fulfilled by amazon.com. :/ It was supposed to be in "used - mint" condition. I feel cheated. I hope the windows license sticker on the bottom of the computer will still work if I have to reinstall. Kushal (talk) 13:30, 1 November 2010 (UTC)
- A partition encrypted with TrueCrypt would show up as an unrecognized filesystem, not as unallocated space. TrueCrypt does support encrypting an entire volume, not just a partition, but in that case the whole volume would show up as unformatted and unpartitioned. It's theoretically possible to "disguise" an encrypted partition as unallocated space, but TrueCrypt doesn't support that and I don't know of a product that does. It strikes me as a bad idea. I would reinstall Windows in any case, because who knows what spyware the previous user left on there. You may want to backup and restore the installed Windows license instead of using the one on the bottom of the machine, to avoid phone activation, as described here for example. -- BenRG (talk) 21:06, 1 November 2010 (UTC)
- Ordinarily, I would not consider going through the trouble of clean installing windows, but for the last two days, I am having networking trouble so I might have to... :/ I guess I need to start a new question for that one... Kushal (talk) 20:08, 2 November 2010 (UTC)
Software
What's the best software to edit sound. I'm a transcriber n sometimes i get really bad audios that i need to remove the background noise on them or they may be mono sound. I don't need a complex software just a really good reliable software. thanks. P.s Don't tell me to Google. —Preceding unsigned comment added by 196.201.218.247 (talk) 14:46, 1 November 2010 (UTC)
- The standard answer here: Audacity. Is free. Is good. --jjron (talk) 15:01, 1 November 2010 (UTC)
- He asked for the best, which is Pro Tools. Not free, better than good. Comet Tuttle (talk) 15:27, 1 November 2010 (UTC)
- Why don't you Google it? (Sorry... couldn't resist.) Kingsfold (Quack quack!) 16:59, 2 November 2010 (UTC)
- He asked for the best, which is Pro Tools. Not free, better than good. Comet Tuttle (talk) 15:27, 1 November 2010 (UTC)
What is the significance of the RIAA no longer suing infringers?
Does this mean that there are no (practical) legal consequences to illegal filesharing? Does anybody know of statistics of statistics showing an increase of illegal filesharing after the announcment was made? AGradman / talk / how the subject page looked when I made this edit 16:22, 1 November 2010 (UTC)
- For the record, that first paragraph said they're "set to drop" their lawsuit strategy; it doesn't say they have dropped it. Comet Tuttle (talk) 16:42, 1 November 2010 (UTC)
- Ramifications are described in detail in the article. Instead of going through a lengthy lawsuit, they have reached agreements with many major ISPs to simply have the user's internet connection cut off. In the end, it is cheaper and probably more effective than lawsuits. -- kainaw™ 16:50, 1 November 2010 (UTC)
computer troubles
Who or what is this 'Crawler' and how has it taken over my computer? I have managed to set my homepage back to normal, but how do I get my old search engine back?
Also, how do I get the old Microsoft Works icons back, these new ones look terrible?
And, properties of my Open Office Document: Created 31/10/2010 23:56:40, last modified 01/11/2010 00:39:11, total editing time 02:11:08. How does that work? —Preceding unsigned comment added by 148.197.121.205 (talk) 16:58, 1 November 2010 (UTC)
148.197.121.205 (talk) 16:53, 1 November 2010 (UTC)
- It appears that "Crawler" is a toolbar for Internet Explorer that is considered malware. It changes your default IE page, and redirects your web searches. Many editors here have recommended Malwarebytes, which is an anti-malware program that should remove it.
- Microsoft Works icons: What sorts of files have the new icons? What do they look like now? Can you upload a screenshot to Flickr or the like, for us to examine?
- For those properties of your document: Could you explain what exactly is your question? I think, but am not sure, that you may be getting confused because "01/11/2010" means "1st of November 2010" and not "January 11 2010"? Comet Tuttle (talk) 17:49, 1 November 2010 (UTC)
- Couldn't I just reset my old search engine somehow?
- All the Microsoft works word processor files do, they're really low resolution pictures, with a blue square at the top, and a stripey box in the middle.
- the problem is that I only had it open less than an hour and have apparently done more than two hours work in that time, I was wondering how it worked that out. 148.197.121.205 (talk) 17:57, 1 November 2010 (UTC)
- Resetting your old search engine: I don't know anything about Crawler, so you would have to ask the author(s) of the software how to change the search engine. Probably not, I will guess; because someone is probably paying them to force your search engine to be something else. If you don't know what Crawler is gaining you, I would remove it, personally.
- Works icons: When you double-click a Works document that has one of these weird icons, does it still open Works, or something else? What version of Windows are you running?
- The 2-hour thing: I see. This might be a bug in OpenOffice, possibly related to this bug (which I also noticed on a non-computer clock of mine at home) in which some clocks and software believed that a daylight savings time 1-hour shift occurred recently. Comet Tuttle (talk) 18:12, 1 November 2010 (UTC)
- How do I get rid of it though?
- They do open properly, it seems, just with annoyingly ugly icons.
- There was a change recently, but it was the night before that. 148.197.121.205 (talk) 18:17, 1 November 2010 (UTC)
- Malwarebytes is supposed to be one anti-malware solution that will get rid of it. Comet Tuttle (talk) 21:36, 1 November 2010 (UTC)
- I've tried that, it doesn't seem to have done anything. What have I done wrong? 148.197.121.205 (talk) 21:43, 1 November 2010 (UTC)
- Malwarebytes is supposed to be one anti-malware solution that will get rid of it. Comet Tuttle (talk) 21:36, 1 November 2010 (UTC)
- Hm. Sorry, I don't have a ton of insight into this because I've never installed it — have you gone to the Control Panel and chosen "Add/Remove Programs" (called slightly different things in Vista and Windows 7) and seen if Crawler is present, and removed it from there? Comet Tuttle (talk) 20:38, 3 November 2010 (UTC)
- The dates make sense if your computer thinks it's in the UK. There was a change in time in the UK from BST to GMT, but that was during the night of the 30/31st November. 92.24.185.90 (talk) 20:59, 1 November 2010 (UTC)
- Other good free anti-malware scanners you could try include Superantispyware and Spybot – Search & Destroy. Best to run them after using Ccleaner, and you may be able to use it to stop "Crawler" running at start-up. A dedicated computer forum may have more expertise and be willing to provide more detailed guidance. You must have an anti-virus and firewall installed. Avast! is a good free anti-virus, there are others. 92.15.10.141 (talk) 12:34, 5 November 2010 (UTC)
Need .exe file to close three processes on Windows XP
I need an .exe file that could close three processes given their names listed in a .txt file in the same directory. The system is Windows XP. It is not possible to run .exe file with parameters in command line. Everything should be completely automated. In fact, the executable will be auto-run from a disk-on-key with U3 inserted into USB slot of a computer without monitor, keyboard or mouse. If you do not know an existing program that could cope with this task, please suggest some piece of code to achieve this. I am not a programmer but know enough to compile it if it is complete. 79.181.28.155 (talk) 16:55, 1 November 2010 (UTC)
- Try this 82.44.55.25 (talk) 17:04, 1 November 2010 (UTC)
- No, unfortunately it does not solve my problem. As I have said, I cannot run it from command line and PsKill requires just that - with parameters. There is a U3 USB disk-on-key with an .exe file that executes automatically (in fact, U3 thinks it's FireFox browser) - you can substitute the browser .exe with any other by changing its name to FireFox-something. So it runs by itself and that's it. I can see no way to add the command line options. 79.181.28.155 (talk) 17:32, 1 November 2010 (UTC)
- Your claim "I cannot run it from command line" doesn't make much sense as you can place all the commands you like in a batch file and run the batch file as an executable. Can you further define the limitations of why batch files cannot be run? -- kainaw™ 17:36, 1 November 2010 (UTC)
- There's a computer with neither monitor nor keyboard doing something. I want to be able to kill three certain processes on this computer just by inserting a U3 disk-on-key into its USB slot. My idea is to substitute auto-run FireFox executable with any "killing" .exe file (renaming it to FireFox.exe or whatever it is called). It actually works - U3 happily runs any .exe I want automatically. The only part of the plan I still did't figure out is how this can be used to kill three certain processes I intend to kill. U3 doesn't run .bat files, only .exe it thinks is a FireFox browser. 79.181.28.155 (talk) 17:53, 1 November 2010 (UTC)
- You could convert a batch file to .exe with something like this 82.44.55.25 (talk) 17:51, 1 November 2010 (UTC)
- Your idea of converting .bat into .exe is a good one, but I am afraid to run obscure converters written by unknown persons (as opposed to PsKill and Rousinovich whom I trust). Could you please suggest C++ code that runs a .bat file, or better still, kills Process1.exe, Process2.exe, Process.exe running on XP system? I am not a programmer, but I can compile 79.181.28.155 (talk) 18:08, 1 November 2010 (UTC)
- You could convert a batch file to .exe with something like this 82.44.55.25 (talk) 17:51, 1 November 2010 (UTC)
- There's a computer with neither monitor nor keyboard doing something. I want to be able to kill three certain processes on this computer just by inserting a U3 disk-on-key into its USB slot. My idea is to substitute auto-run FireFox executable with any "killing" .exe file (renaming it to FireFox.exe or whatever it is called). It actually works - U3 happily runs any .exe I want automatically. The only part of the plan I still did't figure out is how this can be used to kill three certain processes I intend to kill. U3 doesn't run .bat files, only .exe it thinks is a FireFox browser. 79.181.28.155 (talk) 17:53, 1 November 2010 (UTC)
- Your claim "I cannot run it from command line" doesn't make much sense as you can place all the commands you like in a batch file and run the batch file as an executable. Can you further define the limitations of why batch files cannot be run? -- kainaw™ 17:36, 1 November 2010 (UTC)
- Unless I've misunderstood, what you're trying to do is swap something in place of the (U3) firefox.exe so that it'll autorun when you plug it into another computer. Why not just use Shortcut Creator 4U3 which would allow you to add your own applications to the U3 menu (including making them autorun if you wanted) and then you can call whatever you want (either an application with command line parameters or a batch file). I've used this software myself many times to add "non-U3" apps to the menu and it sounds exactly like what you want. ZX81 talk 18:01, 1 November 2010 (UTC)
- Right, but he doesn't even state his name... No way I'll run anything written by Mr. Unknown Hacker on a sensitive system. —Preceding unsigned comment added by 79.181.28.155 (talk) 18:12, 1 November 2010 (UTC)
- Well you could always download the source code for version 2 (which isn't vastly different and will do the same job) from that same page and compile it yourself. However, you don't run the shortcut creator on the targetmachine, you run it on any machine (be it real or virtual) as all it's doing is adding an icon to the U3 menu. If you're familiar with the U3 filesystem/menu structure you can verify for yourself that it hasn't done anything other than added the shortcut as you've asked and then you plug it into the remote system. ZX81 talk 18:42, 1 November 2010 (UTC)
- Right, but he doesn't even state his name... No way I'll run anything written by Mr. Unknown Hacker on a sensitive system. —Preceding unsigned comment added by 79.181.28.155 (talk) 18:12, 1 November 2010 (UTC)
- Try this:
#include <stdlib.h>
int main(void) {
system("pskill process1");
system("pskill process2");
system("pskill process3");
return 0;
}
- -- BenRG (talk) 22:24, 1 November 2010 (UTC)
- Thank you, BenRG! I have modified your code using tskill instead, and it worked like charm. 79.181.28.155 (talk) 22:04, 2 November 2010 (UTC)
- Or use the WinAPI functions: EnumProcesses() to list all processes, and select the one you care about; then call TerminateProcess() to terminate it (if your program has permission to do so). See MSDN's Process and Thread reference for more. Nimur (talk) 00:44, 2 November 2010 (UTC)
How do I close one of my windows on a laptop?
I tried to save a page and it's blocked the window. I can't get the window to close. What do I do apart from turning my PC off? Thank you.--Jeanne Boleyn (talk) 17:14, 1 November 2010 (UTC)
- That description is not clear at all:
- What's your operating system? Microsoft Windows, I suppose?
- What kind of page were you trying to save? A web page?
- What program did you try to save it with? Your web browser? (Internet Explorer, Firefox, Opera, ...?)
- Why can't you close the window? Is the closing button not visible on the screen? Or is it visible but doesn't react?
- In general, under Windows you can press control-alt-delete to get a list of applications as well as some other options. You can use this to end a stubborn application (losing any unsaved data). A more radical option is to log out and log in again. That's more or less equivalent to a reboot, but faster. Hans Adler 17:22, 1 November 2010 (UTC)
- Hold down the Alt key, then while doing so tap the Tab key. This will let you switch between applications. Comet Tuttle (talk) 17:32, 1 November 2010 (UTC)
- This is the answer that Hans Adler gave, but perhaps stated more clearly: On any Windows system, the way to kill a frozen and unresponsive program is (1) Press Control-Alt-Delete to bring up Task Manager, (2) Find the offending program in the list and select it, (3) Press the "end process" button. Looie496 (talk) 17:52, 1 November 2010 (UTC)
- Where do I find the delete key on an Italian Windows Vista laptop?--Jeanne Boleyn (talk) 18:28, 1 November 2010 (UTC)
- My son figured it out and it worked! Thanks for your helpful answers.--Jeanne Boleyn (talk) 19:15, 1 November 2010 (UTC)
- Where do I find the delete key on an Italian Windows Vista laptop?--Jeanne Boleyn (talk) 18:28, 1 November 2010 (UTC)
- This is the answer that Hans Adler gave, but perhaps stated more clearly: On any Windows system, the way to kill a frozen and unresponsive program is (1) Press Control-Alt-Delete to bring up Task Manager, (2) Find the offending program in the list and select it, (3) Press the "end process" button. Looie496 (talk) 17:52, 1 November 2010 (UTC)
- Hold down the Alt key, then while doing so tap the Tab key. This will let you switch between applications. Comet Tuttle (talk) 17:32, 1 November 2010 (UTC)
php
In php, how could you list all files in a directory by their modified date, newest first? 82.44.55.25 (talk) 18:26, 1 November 2010 (UTC)
- The following should do it. It's probably not the easiest way, but as I started learning php 28 minutes ago, it's the best I can do for now:
#!/usr/bin/php5
<?php
$store = array();
$dir = opendir(".");
while ($file = readdir($dir)){
$stat_data = stat($file);
$store[$stat_data['mtime']] = $file;
}
krsort($store);
foreach ($store as $foo){
echo $foo . "\n";
}
?>
- The modified time is fetched with "filemtime($file)". Using "stat($file)" returns an array - most of which you don't want. Also, more than one file can have the same modified time. So, you need a unique index for each file. You can concatenate the filename (which must be unique) to the modified time like:
// see above...
while($file = readdir(dir)){
$mtime = filemtime($file);
$store[$mtime.$file] = $file;
}
// see above...
- Then, even if two files have the same mtime, the index in $store will be unique. -- kainaw™ 20:23, 1 November 2010 (UTC)
- In the pathological case where new files are being added to a directory asynchronously (by another process), the while( ) loop risks entering an infinite loop. Instead, use scandir() to scan the directory exactly one time, and loop over its results:
// see above ...
$file_list = scandir($dir);
for ($i=0; $i < count($file_list); $i++) {
$file = $file_list[$i] ;
$mtime = filemtime($file);
$store[$mtime.$file] = $file;
}
- This is a safer way to scan a directory. Depending on your needs, you might have actually intended to re-scan the directory inside the loop to check for new updates - but I think you should handle that more properly with a separate check for updates. Nimur (talk) 20:35, 1 November 2010 (UTC)
- I don't understand what you mean. Looking at the source for PHP's readdir, it's essentially a wrapper around the POSIX dirent readdir(3) call; it functions pretty much like a generator, and it doesn't reopen and rescan the directory each time you call it. So I don't see why scandir is any safer. PHP either uses the native POSIX scandir (glibc source) or its own implementation (which works pretty much the same) - both say in essence while ((entry=readdir(direntPtr))!=NULL) ... which is essentially identical to the readdir loop, above, just in C rather than PHP. So, bar timing differences, the PHP readdir loop should work just the same as the C loop inside scandir. And they have, surely, the same pathological (mis)behaviours. -- Finlay McWalter ☻ Talk 23:19, 1 November 2010 (UTC)
- Hm. That seems pathological. I was under the impression that PHP scandir would guarantee a termination time, but on further inspection, I can see that the scandir documentation does not specify any such safety. I'm disinclined to dive into PHP source, but I'm in agreement with Finlay that it probably directly wraps glibc. So - followup questions - is this issue a well-known race condition? If you have a program (say, a logger) constantly writing new files into the directory, and if the timing coincides with any program that is scandir`ing that directory, doesn't this yield an infinite loop? What can be done about it? Shouldn't directory-listing be wrapped in a mutex`ed ownership of the directory? Does this vary from file-system to file-system (say, ext4 vs. NTFS)? Nimur (talk) 23:49, 1 November 2010 (UTC)
- In retrospect, I think my error is assuming file-I/O operations should be "safe" - i.e. to have a guaranteed response time; but few/no direct I/O operations are ever guaranteed to have finite return times. In my scenario above, a program is writing new files to the directory... and if there are an arbitrary number of additional files being added to the directory, it makes sense that listing the directory-contents should take an arbitrarily long time. Programmers who need to guarantee response-time would need to use a timeout on any I/O operation. I'm going to hide this discussion because it may confuse the OP, and is entirely based on my earlier misconception. Nimur (talk) 00:05, 2 November 2010 (UTC)
- Hm. That seems pathological. I was under the impression that PHP scandir would guarantee a termination time, but on further inspection, I can see that the scandir documentation does not specify any such safety. I'm disinclined to dive into PHP source, but I'm in agreement with Finlay that it probably directly wraps glibc. So - followup questions - is this issue a well-known race condition? If you have a program (say, a logger) constantly writing new files into the directory, and if the timing coincides with any program that is scandir`ing that directory, doesn't this yield an infinite loop? What can be done about it? Shouldn't directory-listing be wrapped in a mutex`ed ownership of the directory? Does this vary from file-system to file-system (say, ext4 vs. NTFS)? Nimur (talk) 23:49, 1 November 2010 (UTC)
- I don't understand what you mean. Looking at the source for PHP's readdir, it's essentially a wrapper around the POSIX dirent readdir(3) call; it functions pretty much like a generator, and it doesn't reopen and rescan the directory each time you call it. So I don't see why scandir is any safer. PHP either uses the native POSIX scandir (glibc source) or its own implementation (which works pretty much the same) - both say in essence while ((entry=readdir(direntPtr))!=NULL) ... which is essentially identical to the readdir loop, above, just in C rather than PHP. So, bar timing differences, the PHP readdir loop should work just the same as the C loop inside scandir. And they have, surely, the same pathological (mis)behaviours. -- Finlay McWalter ☻ Talk 23:19, 1 November 2010 (UTC)
Thanks, that works. Two things; how could I display the modified date of each file next to it? And I'm seeing "." and ".." listed in addition to the files, is there a way to get rid of that? 82.44.55.25 (talk) 14:53, 2 November 2010 (UTC)
- The changes are very minor. I'll skip all filenames beginning with "." for you - those are hidden files.
$store = array();
$dir = opendir(".");
while ($file = readdir($dir)){
if($file{0}=='.') continue; // Skip filenames beginning with .
$mtime = filemtime($file);
$store[$mtime.$file] = $file;
}
krsort($store);
foreach ($store as $time=>$foo){ // The index has the time
echo intval($time)."\t".$foo."\n"; // Need intval since the filename is concatenated to the time.
}
- That should work. -- kainaw™ 16:50, 2 November 2010 (UTC)
- I just thought that if you want an actual date, you can use date("Y-m-d", intval($time)) instead of just intval($time). -- kainaw™ 16:57, 2 November 2010 (UTC)
- Awesome! Thanks 82.44.55.25 (talk) 18:14, 2 November 2010 (UTC)
November 2
e-mail listserve
whats a e-mail listserve — Preceding unsigned comment added by Kj650 (talk • contribs)
- LISTSERV was a specific software for electronic mailing list management. Its name was catchy, so "list serve" now is a genericized name for any email list management tool. Nimur (talk) 01:45, 2 November 2010 (UTC)
Can someone explain how this works to me? When I learned networking in school (2003-04), we learned that packets were filtered out by NIC's on the hardware level, and as such it was impossible for software to sniff packets from other users unless one specifically purchased a NIC with built-in promiscuous mode, which our teachers told us was rare. However, everything I've been reading about this software makes it sound like this is not rare. Can someone explain this? Magog the Ogre (talk) 04:00, 2 November 2010 (UTC)
- Every network card I've seen, even the old cheap Realtek ones, offered a promiscuous mode. As you suspect, it's not rare at all. I even wonder if network cards without promiscuous mode exist at all, as the online FAQs of some capturing product (libpcap, Wireshark) don't seem to mention this as a possible failure cause. Unilynx (talk) 05:02, 2 November 2010 (UTC)
- Promiscuous network card mode is not rare - it's just rarely enabled by software drivers. Almost all hardware supports this mode. Installing a network monitor like Wireshark is the easiest way to experiment with enabling promiscuous mode. Strictly speaking, Firesheep does not have a packet sniffer; you must install pcap, a well-known software packet sniffer (that functions by replacing your network interface driver with its own driver). (See Firesheep installation procedure). Firesheep then provides a user-friendly interface, not unlike Wireshark, except that Firesheep is tuned specifically to filter for Facebook login traffic and similar sorts of things, and then display that information in an impressive way. The real meat-and-potatoes of the software is pcap - which has been around for ages and has always been capable of these sorts of data interceptions. Firesheep is just a "pretty-printer" for packet-sniffers. Nimur (talk) 05:08, 2 November 2010 (UTC)
- Agree with the previous comments, promiscuous mode is not rare but normally set off because it is normally thought to be not useful. Regards, SunCreator (talk) 15:38, 2 November 2010 (UTC)
- Magog the Ogre, you may be interested in Wikipedia:Wikipedia Signpost/2010-11-01/Technology report#Browsing securely.
- —Wavelength (talk) 16:51, 2 November 2010 (UTC)
How do you run the add on if you add it? 84.203.243.10 (talk) 10:46, 3 November 2010 (UTC)
- You might want to start a new section, or frankly, just google it. Magog the Ogre (talk) 23:09, 3 November 2010 (UTC)
- I can certainly believe professors saying it was rare in 2003, but by 2003 it was hardly rare. Check out Orinoco cards if you're interested (one of the most talked about wireless chipsets around that time), but even Intel was getting in on its Centrino related cards back then, all of which supported promiscuous mode even in Windows. It was hardly rare back then. It may have been rare before then, but I'll leave that to somebody older than me. Shadowjams (talk) 09:37, 4 November 2010 (UTC)
Video games
If a human and a computer were to play a game of Starcraft, with neither receiving any advantages or handicaps, who would win? How about in other video games, like Counterstrike, Rise of Nations, or Civilization 4? Is there any well-known real-time strategy game in which the AI has ultra-superhuman capabilities (i.e. it can easily beat the best human player)? --99.237.232.254 (talk) 04:08, 2 November 2010 (UTC)
- Edit: let me change Starcraft to Starcraft II, since the former was made at a time when artificial intelligence was in its infancy. --99.237.232.254 (talk) 04:11, 2 November 2010 (UTC)
- Historical note: The artificial intelligence seen in computer games isn't representative of the state of the art of AI research. See AI Winter for a historical overview of the rise and fall of AI research. Paul (Stansifer) 12:32, 2 November 2010 (UTC)
- With RTS games it's usually down to APM (actions per minute)... the best players in the world can get (incredibly) over 300 APM if memory serves me correctly about some Starcraft 1 Pro Korean players. Actions comprise keystrokes and mouse movements and clicks. I think there was a documentary where their brain functions were monitored, and the casual gamer would get up to about 60 APM and be cognitively aware of every action, whereas the pro would get up to 300 APM and have an instinctive awareness of the whole map... different areas of the brain lit up in the monitoring. However, given your question, you would allow the computer to have as high an APM as possible for its CPU (and the computer player's APM is limited even on the toughest level)... so in my opinion any human would not stand a chance, unless the computer AI is terribly flawed or the human exploits a bug. There was a time when a computer would not have been able to beat the best humans (compare chess and the progress of computer ELO ratings) but the modern computer is way too powerful in terms of raw computational speed. Now turn-based - like Civ - that's another argument altogether... I think a top human player ( or a forum based game) would be able to beat a computer player simply because it's incredibly difficult to write AI for Civ (the highest levels in Civ employ resource cheating). For FPS I think a godlike computer player would own a human (the computer is fast enough to dodge anything at close range for example)- but I've seen humans do some incredible things in those games (hide, snipe, etc.) so I don't know. Sandman30s (talk) 11:09, 2 November 2010 (UTC)
- I agree with Sandman30s, mostly. Suppose a series of games is made, each of which has one primary test that the user is continuously competing against. On one extreme the test is reflexes with no strategy (perhaps electronic whack-a-mole) and on the other extreme the test is strategy with no reflexes (perhaps chess or go). The closer you get to the "reflexes" side of this spectrum, the more obvious it is that the computer will beat any human. As you get closer to the "strategy" side, it becomes less obvious — a run-of-the-mill chess program will beat your average human chess player 99% of the time, but that's not true for go. An RTS I would place somewhere about halfway between reflexes and strategy, and one way to analyze the probable outcome is to say that the computer will completely beat the human on the reflexes component, and it's less obvious on the strategy component. Personally I think the strategy element of RTS games is pretty elementary and so it's going to be the computer in a landslide, if the developer has spent a decent amount of time writing good AI — but everything does hinge on that. Comet Tuttle (talk) 16:27, 2 November 2010 (UTC)
- Here's a story that was linked by Slashdot today discussing using genetic algorithms to optimize build orders for the Zerg. Comet Tuttle (talk) 17:13, 2 November 2010 (UTC)
- Specifically, it's about optimizing a zerg rush. --Carnildo (talk) 22:47, 3 November 2010 (UTC)
- The strategy component in most RTS's, including Starcraft, is by no means simple. A simple Google search would reveal lots of webpages, and even entire books, devoted to exploring the best strategies in Starcraft--and very few of these require a high APM. These strategies are very difficult for a human to think up or defend against, so I don't think it would be easy for a computer. --99.237.232.254 (talk) 05:40, 3 November 2010 (UTC)
- I would go with what a multiple world champion Korean pro does, rather than what a random internet guide says. However, if the human and computer knew exactly the same strategies, it would come down to APM and no human can be remotely close when it comes to raw computation. Sandman30s (talk) 08:57, 3 November 2010 (UTC)
Difficulty in choosing username
Pretty much every website on the internet requires a username these days if you intend to participate. I have extreme difficulty in choosing username; I have few defining interests or hobbies to base a username on, I don't want to include any part of my real identity, I don't want to divulge my gender. I thought about just using random numbers or something, but almost every site requires a combination of letters and numbers, and some block random usernames as "confusing". Any suggestions? —Preceding unsigned comment added by 114.37.143.221 (talk) 11:07, 2 November 2010 (UTC)
- How about something obvious you can see around you - eg "22inchsonytv" or "nextdoorsfordcar" ? Sf5xeplus (talk) 13:14, 2 November 2010 (UTC)
- This topic comes up once every few months here. Here is a thread from last December containing some suggestions. Personally I like choosing two random nouns in a row. Comet Tuttle (talk) 16:18, 2 November 2010 (UTC)
- Just be sure to avoid this issue... ;-) -- 78.43.71.155 (talk) 21:53, 2 November 2010 (UTC)
- Try one of these. I haven't used them so not sure what they give you. Mo ainm~Talk 16:25, 2 November 2010 (UTC)
- There's an obvious security problem with asking some website to decide your username and password for other websites. Comet Tuttle (talk) 16:31, 2 November 2010 (UTC)
- Password yes and I would never suggest anyone used one, but a username is different. Mo ainm~Talk 16:37, 2 November 2010 (UTC)
- There's an obvious security problem with asking some website to decide your username and password for other websites. Comet Tuttle (talk) 16:31, 2 November 2010 (UTC)
- Here is a page that just picks random adjectives and pairs them with random nouns. Click it a few times until you see something you find enjoyable. Of the ones I got, I liked "BourgeoisBasement" and "EverydaySubstitute" the most, personally. --Mr.98 (talk) 16:56, 2 November 2010 (UTC)
something that's quite simple is: tke your initials, and stick a random number, or a number that actually means something to you, say for example you like seven, then you could square that and add that to your initials, eg. gyd49 or take a character you like and stick your birth year behind it 70.241.22.82 (talk) 17:41, 2 November 2010 (UTC)
- See Check Username Availability at Multiple Social Networking Sites.
- —Wavelength (talk) 18:21, 2 November 2010 (UTC)
Translate your real name into some other language and use that. Jean Aigle 22:04, 2 November 2010 (UTC)
Chinese ?

Anyone seeing chinese characters in their watchlists or contribution listings (on wikipedia), or is it just me? ok it's stopped now - but explain this (see right) I suppose I should ask what the character is too (chinese for 'you've been hacked' no doubt) ?!! Sf5xeplus (talk) 13:14, 2 November 2010 (UTC)
- Request - whomever does identify the character (maybe somebody more skilled in the use of a Chinese IME), could they paste it in plain-text as well? I have a sneaking suspicion it's going to be a character encoding glitch - most likely "-1" in one of the unicode code-pages or something. Nimur (talk) 14:34, 2 November 2010 (UTC)
- It is a character encoding glitch. It is, for some reason, using unicode when it shouldn't. The character is 楷, meaning "good". -- kainaw™ 14:38, 2 November 2010 (UTC)
- Would you elaborate how can an HTML page (especially one encoded in UTF-8) not use Unicode?—Emil J. 14:46, 2 November 2010 (UTC)
- It is using a code that it shouldn't be using - if you want to be painfully pedantic. -- kainaw™ 16:45, 2 November 2010 (UTC)
- It's marked all my edits as good - that's a feature not a bug :)
- I suppose a bug report is pointless, as I can't reproduce it.Sf5xeplus (talk) 16:46, 2 November 2010 (UTC)
- It is using a code that it shouldn't be using - if you want to be painfully pedantic. -- kainaw™ 16:45, 2 November 2010 (UTC)
Simple email forwarding
For a club I'm a member of, I'd like to be able to set up an email address that will forward messages to a (small) specified list of recipients, with no, or minimal, action required by the recipients themselves. The purpose its to allow members of the group to send a message to all other members by emailing to a single address. We're currently using Yahoo Groups, but are finding that rather cumbersome to use, and we don't need all the facilities it provides. Can anyone recommend a suitable way of achieving this? (Preferably free, of course, or at least very cheap.) AndrewWTaylor (talk) 15:23, 2 November 2010 (UTC)
- A distribution/mailing list? Not too savvy about it myself, but this page might be worth a look: http://email.about.com/od/outlooktips/qt/Distribution_List_Outlook.htm - as might the google search I got it from http://www.google.co.uk/search?hl=en&biw=1260&bih=810&q=outlook+mailing+list&aq=f&aqi=g1g-c4g1g-c1g1g-c1g1&aql=&oq=&gs_rfai= Darigan (talk) 16:24, 2 November 2010 (UTC)
- Do you want this to be hosted by some other web service, as Yahoo Groups is; or do you control a web server yourself so you can install some software? If the latter, see LISTSERV or Electronic mailing list and follow the links from there for various solutions you can set up on your server. Comet Tuttle (talk) 16:30, 2 November 2010 (UTC)
- Thanks both. @Darigan: it needs to be independent of the email client and usable by e.g. Hotmail users. @Comet Tuttle: Ideally I want it externally hosted - there isn't a server I can use; we do have a couple of Internet domains, but the company they are registered with (FreeParking) only allows forwarding to a single email address (as far as I can tell). AndrewWTaylor (talk) 17:26, 2 November 2010 (UTC)
Upgrading my HP ATi Mobility Radeon 4530
I was trying to run a program that didn't work on my Hewlett Packard laptop. Talking with someone on the net I was told that my ATi Mobility Radeon 4530 driver was outdated. I needed to upgrade in order to run the program, and i followed a link given to me to download it :
http://www.nvidia.com/Download/index.aspx?lang=en-us
on this site I chose option 2, to let the site determine what upgrades i needed so I followed that and ended u pwith this site:
I downloaded the files and installed the program. But at the end of installation a message told me it was finished and that I already had these upgrades, and that i was now only upgrading atop upgrades I already had. So i figured ok, then it must be in order and I have the necessary upgrades. But, another program called "Driver Mender" which I also downloaded from the links i got to check the computer's system and let me easily upgrade my computer with the newest stuff tells me that I still have ATi Mobility Radeon 4530 and that it is in need of upgrade. And I don't understand why this is happening when i downloaded HP ATi Mobility Radeon HD 4530/4650 Driver upgrade from this link :
So i'm confused since everytime i try install it again it still says I already have the upgrades, but then the Driver mender says the opposite. Where on my computer can I go to check my system information, including of course what version of the ATi Radeon driver i have?
Any advice on what to do, or what sites to go to to get the latest upgrades? Free of course, like this one was.
As for the program I was supposed to run in the first place, nevermind that, because I'm not running that program now after all (Don't ask) but i still want my computer to be upgraded as good as possible when i have the chance.
Any clever computer minds out there? :) Krikkert7 (talk) 18:14, 2 November 2010 (UTC)
- For an ATI driver (not an NVidia, for which your first link is, which isn't going to work) either go to ATI's own website or to HP's website and pick the appropriate driver for your model of laptop. I can't think of any reason you'd get it from anywhere else. -- Finlay McWalter ☻ Talk 19:57, 2 November 2010 (UTC)
Yes i know, the nvidia page only helped me determine what upgrades I needed, and i didn't download anything from that site but found my way to the other link i showed and downloaded from there. —Preceding unsigned comment added by Krikkert7 (talk • contribs) 01:29, 3 November 2010 (UTC)
base64_decode
I came across a footer.php file that looks like it is encrypted as it just contains random letters and digits, base64_decode is the only part that makes any sense so I assume encryption was used on it. Is there any way to decode this page. Mo ainm~Talk 19:51, 2 November 2010 (UTC)
- That sounds like it's base 64 encoded; you really shouldn't see that (the browser should automatically decode it), but you can manually decode it. You can do that on your own computer (using one of the many base64 libraries) or with an online thing like this. -- Finlay McWalter ☻ Talk 19:55, 2 November 2010 (UTC)
- Thats great thanks I'll have a look at that. Mo ainm~Talk 19:59, 2 November 2010 (UTC)
Weird networking trouble
I wrote a few days ago for advice about my computer (http://en.wikipedia.org/wiki/Wikipedia:Reference_desk/Computing#Unallocated_space). However, I have a bigger problem starting yesterday. Basically, this computer (Dell Alienware) connects fine to the port in the wall but my computer (Asus n61jv-x2) does not. To confound the problem, the wireless router stopped working* the same time as the ASUS did and I have been scratching my head since. Both systems are running Windows 7 and as far as I know, the same wired networking hardware (Atheros AR8132 on the Alienware and AR8131 on the Asus) too. I am at a loss to what to do. Any ideas please? I don't know how much IT can help as the port is clearly functional (right?). Thank you! You guys are my hero. Kushal (talk) 20:16, 2 November 2010 (UTC)
*To clarify, we were both using the wireless router Netgear WGR614v7 but now that it is not working, I have the Alienware hooked up to the wall. The router seems to be pretty much alive but the logo i on the router stays a blinking yellow. Resetting the router did not help. Kushal (talk) 20:20, 2 November 2010 (UTC)
- Just to clarify, did you try unhooking the Alienware machine from the router so you could make sure to use exactly the same plug on the router when attempting to hook up your computer to the router? What exactly happens when your computer is hooked up to the router and you restart your computer? What happens when you ping the router's IP address from the command line? Comet Tuttle (talk) 20:45, 2 November 2010 (UTC)
- Comet, Thanks for answering. Yes. I tried various things. When I hook up the Alienware to the wall, everything is fine. When I hook up the Asus to the wall, there is no connection. When I hook up either machine to the Netgear, I am connected to the router but there is no Internet. Because I was able to get into the router's management system at routerlogin.com , I did not think about pinging the router. I mean, the connection between the router and the computer seems fine. It is just the router to the wall part that's messing me. Kushal (talk) 21:54, 2 November 2010 (UTC)
- Hold up, that's not clear enough - when you hook up the Asus to the router, you are able to ping it and connect to its management web page? I had started to suspect that, against the odds, you had experienced a simultaneous hardware failure of both the router and the Ethernet circuitry on the Asus, so the solution was to get a new router and also get a new Ethernet adapter for the Asus (like a PC card or maybe a USB Ethernet adapter). But if the Asus is able to communicate with the router, then you may be able to fix this by just replacing the router and twiddling with the Asus's network settings. Comet Tuttle (talk) 00:07, 3 November 2010 (UTC)
- Any ideas on what tweaks I could do to it? I am new to Windows 7. Kushal (talk) 15:50, 3 November 2010 (UTC)
- OK, I have more details. I can connect via ethernet at another place. In my room, whenever I connect by ethernet, I see multiple connections called Network 2 and Network 3 (or something) simultaneously connected. Is that a problem? The place I connected successfully at only shows one active connection. Help? Kushal (talk) 16:02, 3 November 2010 (UTC)
- (Is that plugged straight into the wall in your room, or through the router?) This is good news; your laptop's network circuitry seems fine. It is unusual that you would see both of those connections. I will take a guess that your machine is connecting via the Ethernet cable on one of them, and via a wireless connection on the other. From the "Network" Control Panel, take a look at each of the two connections, and right-click and disconnect whichever one isn't the wired Ethernet connection. Right-click the other and choose to repair the connection and see if that automagically fixes your connection? Comet Tuttle (talk) 18:28, 3 November 2010 (UTC)
- Yes, I have pretty much ruled out any hardware faults. Got in touch with IT. Could not get the issue resolved so we did a workaround. We made the computer believe I have a static IP address (and knowing the DHCP server won't issue those IP addresses in the foreseeable future), we are good to go, for now. I did try to disable and repair connections but there is something with dhcp and the 192.168 servers that just don't fit. In other news, I gave the wireless router a very similar IP address and it is running now too! I am on wireless on the Asus now. The only thing is that the whole thing has left me feeling strange. I think I need to wipe the computer and reinstall Windows as per the discussion above. The only problem is that there is so much software I have installed and it is such a chore to reinstall them. :?
- Thank you so much for your help. Did anything in what I said ring a bell with you? Please let me know if you think there's a solution to this. Thanks Kushal (talk) 21:59, 3 November 2010 (UTC)
- Hey, if you got it working, you got it working; don't wipe the system needlessly; you might have to just do the same kludge again to get networking working again even after a wipe and reinstall. Enjoy your networking! Glad you had access to an IT person who was able to come up with a workaround. Comet Tuttle (talk) 22:46, 3 November 2010 (UTC)
As you say. The guy actually told me that this was not a solution but just a workaround and I would need to get it fixed. I would hate to have to reinstall all applications one at a time. :/ Kushal (talk) 19:44, 4 November 2010 (UTC)
MacBook Pro
Hi. I have a Macbook Pro that is now about four and a half years old. I'm not sure what state it should be in by this stage but it seems to have slowed down remarkably in the last few weeks, since giving it a lot more use after a few months of respite. I've never done anything to 'clean up' my hard drive or anything technical like that, I've just used it normally over the years but I've not put so much on it to warrant it taking up to ten minutes to load a web page and constantly tell me programs are not responding. Does anyone have any ideas on what I could do to speed it up? 128.232.247.49 (talk) 21:59, 2 November 2010 (UTC)
- Are you running low on disk space? It is preferable to have at least a few gigabytes of free disk space on your computer. Kushal (talk) 23:05, 2 November 2010 (UTC)
- Do you live near an Apple Store? Going to a Genius Bar would probably be an easy way to get a quick diagnosis (which wouldn't cost anything). Otherwise it is pretty hard to tell what the issue is from the description you've given. When something is acting up funny on mine, I try to figure out what is going on from the Activity Monitor (Utilities > Activity Monitor; then go to Window > Activity Monitor to make sure the main screen is displaying). Sort the processes by CPU — what's at the top? Is there something hogging up the processor? Sort by "Real Mem" — is something unusual hogging all the RAM? Look at the "System Memory" tab — are you consistently out of RAM? Look at Disk Activity when you are doing something that might take a long time — does it seem to lock up at all? Paying attention to these kinds of indicators can let you know if the problem is, say, rooted in a hardware issue (e.g. not enough RAM or a buggy hard drive) rather than a software issue. Also, what OS are you using? I found that my MacBook running 10.4.11 got very slow for awhile and that many of my programs were just not very efficient about its usage of memory, and a lot of that was fixed when I upgraded to 10.6 (which was fairly cheap and easy, in the end). --Mr.98 (talk) 23:14, 2 November 2010 (UTC)
- The disk is about the only part that can slow down, either if files are fragmented heavily, or if bad blocks are being mapped out and the replacement blocks are non-local. If you want to keep the computer going, try reformatting and reinstalling, or buy a replacement drive. --Stephan Schulz (talk) 23:32, 2 November 2010 (UTC)
Disk defragmenting might be useful for this... 70.241.22.82 (talk) 16:35, 3 November 2010 (UTC)
- Disk fragmentation is not an issue on OS X - never worry about it. run Disk Utility (or Disk Warrior, if you own it) on the hard drive to see if its failing, try reseating the ram sticks (bad or loose ram can confuse the system); add more ram if you have a Gb or less, check to see if some background app is hogging a lot of CPU (usual culprits are the Finder and mdworker - both of those should settle out over time), if all else fails, download Yasu (or equivalent) and clear all the caches, system swap files, update the prebindings, etc. (sometimes corrupt font or system caches can cause a bit of a tizzy). --Ludwigs2 16:42, 3 November 2010 (UTC)
November 3
help for connecting to server
i installed this game ..london law on my ubuntu 10.10...thye ask for a host to connect to ...how do i find it out and how do i find out the port number..thanksMetallicmania (talk) 03:15, 3 November 2010 (UTC)
- Was it blocked by Windows firewall? It may prevent the program from accessing the internet. General Rommel (talk) 21:03, 3 November 2010 (UTC)
Slash in the IP address
What does it mean when there is a slash in the IP address, such as 192.168.0.0/24 ? 220.253.253.75 (talk) 06:58, 3 November 2010 (UTC)
- The concept is explained in our article on CIDR notation. Regards,
decltype(talk) 07:02, 3 November 2010 (UTC)
It's an ip range. In that example, it means everything in the range "192.168.0.0" to "192.168.0.255" 82.44.55.25 (talk) 09:49, 3 November 2010 (UTC)
In other words, it is the number of 1s in the subnet mask. So /24 is equivalent to the subnet mask of 11111111111111111111111100000000 or 11111111.11111111.11111111.00000000 or 255.255.255.0 - WikiCheng | Talk 12:19, 3 November 2010 (UTC)
IT milestones in 2007
Hi, Can you direct me to a website / article which lists the major milestones of Information Technology in 2007 ? - WikiCheng | Talk 08:21, 3 November 2010 (UTC)
- Where on there does it list the specifically IT milestones? --Mr.98 (talk) 12:03, 3 November 2010 (UTC)
- I don't think it does. The closest I could find is Timeline of computing 2000–2009. Although by that, it doesn't look like 2007 was a very busy year. Indeterminate (talk) 15:08, 3 November 2010 (UTC)
- Where on there does it list the specifically IT milestones? --Mr.98 (talk) 12:03, 3 November 2010 (UTC)
Thank you ! In case you find some other websites (other than Wikipedia), I will be interested. Nonetheless, this has been helpful - WikiCheng | Talk 07:50, 4 November 2010 (UTC)
Items with multiple attributes
I want to re-write a simple book-keeping program that labels, categorises, and group-totals the enteries in my bank statements, as supplied in CSV format. The earlier version written in old Basic used an array to represent the various parts of each line: date, amount, description, category, etc.
In more modern languages, is there any way of representing this kind of multi-attribute data that is better than an array? Or should I just stick with arrays? Is there any language, especially a basic-like language, that makes things such as totaling a column in an array easy to do? I do not want to use a spreadsheet. Thanks 92.15.0.194 (talk) 14:33, 3 November 2010 (UTC)
- I would suggest you could represent the items as a struct or a class. Then you would have item.date, item.amount, etc. You would then have an array (or, in many languages a list) of items, and could quickly iterate over them to produce the sums. C# will certainly do this, and I would stronlgy expect VB.net to be the same. No doubt there are other alternatives. --Phil Holmes (talk) 14:40, 3 November 2010 (UTC)
- (edit conflict)If the set of attributes is fixed, you'd mostly represent each entry as a tuple (aka a struct in C or an object in Java), where each element of the tuple had a type appropriate for the kind of data that attribute would store. If, on the other hand, attributes could be entirely arbitrary, you'd probably use a hashtable to store each of the attribute-name:attribute-value pairs. Then you'd probably have an array of entries (other data structures might be appropriate depending on how you'd be accessing them). Pretty much any modern programming language can do all this very simply. I try not to specifically evangelise, but certainly doing this in Python would be straightforward. -- Finlay McWalter ☻ Talk 14:46, 3 November 2010 (UTC)
- Was just wondering why you say "I do not want to use a spreadsheet", and how hard and fast that restriction is. Sorting line items by category and sub-totalling within categories (plus a whole lot more) is exactly what pivot tables in MS Excel do for you. If you want the fun and challenge of rolling your own code then that is fine - just as long as you realise that you are doing a 5 mile run when you could take a taxi instead. Gandalf61 (talk) 15:12, 3 November 2010 (UTC)
- Exaggeration. Totaling a column in an array takes a line of code. 92.24.178.95 (talk) 17:33, 3 November 2010 (UTC)
- That depends entirely on the programming language and functions previously written. Given enough functions written, I could do this entire project is "one line of code" with: do_all_the_work();. -- kainaw™ 18:24, 3 November 2010 (UTC)
- It takes one line of code in Basic. 92.24.178.95 (talk) 18:27, 3 November 2010 (UTC)
- Sure, totalling values in an array is easy. But how does the user get the data into the array in the first place ? And how are the results presented back to the user ? And how and where is the data in the array stored when the program is not in use ? And how does the user change the data in the array ? Or what if they change their mind about how they want to analyse the data, or want to change the structure of the data ? Your "one line" program can't do any of that, whereas it all comes for free in a spreadsheet. Your are telling the guy running the marathon "it's easy - you just have to put one foot in front of the other". Gandalf61 (talk) 13:49, 4 November 2010 (UTC)
- Some of your questions are answered by reading the original question. The rest of them are simple programming. 92.28.250.172 (talk) 14:12, 4 November 2010 (UTC)
- Obviously all those problems can be solved - eventually - by "simple programming", otherwise spreadsheets would not exist. My point was that your facile "one line of code" response ignored all of the issues that make writing useful programs that will be used by real people in real-life situations incredibly challenging (or deeply frustrating, depending on your point of view). From your responses I get the impression that you have little or no experience of doing that. Gandalf61 (talk) 14:07, 5 November 2010 (UTC)
- Some of your questions are answered by reading the original question. The rest of them are simple programming. 92.28.250.172 (talk) 14:12, 4 November 2010 (UTC)
- Sure, totalling values in an array is easy. But how does the user get the data into the array in the first place ? And how are the results presented back to the user ? And how and where is the data in the array stored when the program is not in use ? And how does the user change the data in the array ? Or what if they change their mind about how they want to analyse the data, or want to change the structure of the data ? Your "one line" program can't do any of that, whereas it all comes for free in a spreadsheet. Your are telling the guy running the marathon "it's easy - you just have to put one foot in front of the other". Gandalf61 (talk) 13:49, 4 November 2010 (UTC)
- It takes one line of code in Basic. 92.24.178.95 (talk) 18:27, 3 November 2010 (UTC)
- That depends entirely on the programming language and functions previously written. Given enough functions written, I could do this entire project is "one line of code" with: do_all_the_work();. -- kainaw™ 18:24, 3 November 2010 (UTC)
- Exaggeration. Totaling a column in an array takes a line of code. 92.24.178.95 (talk) 17:33, 3 November 2010 (UTC)
- Is there a need to change? at best you would be replacing array[n][5] (when the 5th element is price or whatever) with array[n].price , (and using a for next loop over n), even something old like pascal (eg freepascal) can do this using 'records'. eg http://www.hkbu.edu.hk/~bba_ism/ISM2110/pas048.htm (full object orientated languages can do more, but in the example you gave that would probably be of little use)
- freebasic can do the same type of thing .. there will be other examples of languages not far removed from the basic you're using. It's not really any simpler, and you have to learn the new syntax etc. So...Sf5xeplus (talk) 19:53, 3 November 2010 (UTC)
Exactly what I was thinking Sf5xeplus; the struct or class things seem difficult and unless there is a function for adding them all up, not any easier. 92.28.241.78 (talk) 20:21, 3 November 2010 (UTC)
link The article I forgot to link is Record (computer science) - just about every language has a version, including newer BASICs, in general they're of good use when you've got strings, and numbers associated with the same item. Easier to read (in principle) but not necessarily simpler or easier when only writing small programs. Sf5xeplus (talk) 22:25, 3 November 2010 (UTC)
Story Management software
Im looking for some software to manage stories (for a load of short stories)
so for example, if i make a story with the title Example i cant make another one with the same title as its already taken (getting rid of duplicates)
can be either offline (on my computer) or online (a bit like a wiki) and for txt and/or doc and/or PDF, i dont mind which
thanks in advance :D
Sophie (Talk) 16:34, 3 November 2010 (UTC)
- I looked up "story management software" on Google and this is freeware that got a favourable review: http://www.spacejock.com/yWriter5.html I don't know if its what you are looking for. Otherwise, have you considered saving Example followed in the title by the date or time, eg "Example 1 1 10"? 92.24.178.95 (talk) 18:25, 3 November 2010 (UTC)
- nice idea for the date, but say it goes like this
- * Title: Hello there 1/nov/10. Content: Hello and welcome to Wikiedia...
- * Title: My userpage 2/nov/10. Content: This is my user page...
- * Title: Hello there 3/nov/10. Content: Hello and welcome to Wikiedia...
- title 1 and 3 are the same :(
- the software is cool :) but its more for long stories rather than loads of small ones
- still good though :) Sophie (Talk) 19:46, 3 November 2010 (UTC)
- Online Google Docs lets you have files of the same name, it stores them by date (last modified)..
- Offline I don't know of an example.Sf5xeplus (talk) 19:37, 3 November 2010 (UTC)
- thanks ill take a look :) Sophie (Talk) 19:46, 3 November 2010 (UTC)
- I'm very confused. Do you want a document management system, or a word processor? You can save files with any filename you want; and you can use a document management system (or even just a Word Document with hyperlinks) to reference each document by title. For example, you can create a "Table of Contents" document in Word, and insert hyperlinks to each other story file. The text ("title") can be anything you want - you can use the same title for two different links to different story files. Nimur (talk) 19:55, 3 November 2010 (UTC)
- i know its hard to explain :( so lets say its a wiki. I create the page Example and put the story there so now, i can no longer make another page with the title example because its already there. so its more like a doc management system. does that make a bit more sence? Sophie (Talk) 20:16, 3 November 2010 (UTC)
- I'm unclear: do you want something that a) prevents you from having more than one file with the same title, or b) allows you to have more than one file with the same title, or c) deletes files that have the same content? If it is c), then the freeware Duplicate Cleaner would do that. 92.28.241.78 (talk) 20:36, 3 November 2010 (UTC)
- I also think that Sophie is unnecessarily equating "title" with "filename." Filenames must be unique (a different file name is required for each file). But you can have the same title for as many files as you like: the question is, how do you definea title? Well, that depends on your file-type. A plain text file can have a line that says Title: _____; or a Word Document actually can save a title as metadata. If you want an index of documents by title (instead of by file name), Windows Explorer can do this, or other file managers; or you can use a hyperlink to point to each file. Nimur (talk) 21:20, 3 November 2010 (UTC)
- I'm unclear: do you want something that a) prevents you from having more than one file with the same title, or b) allows you to have more than one file with the same title, or c) deletes files that have the same content? If it is c), then the freeware Duplicate Cleaner would do that. 92.28.241.78 (talk) 20:36, 3 November 2010 (UTC)
- i know its hard to explain :( so lets say its a wiki. I create the page Example and put the story there so now, i can no longer make another page with the title example because its already there. so its more like a doc management system. does that make a bit more sence? Sophie (Talk) 20:16, 3 November 2010 (UTC)
- Sophie could also choose to save many files named Example if he or she placed each of them in a differently named directory. Comet Tuttle (talk) 22:44, 3 November 2010 (UTC)
@92.28.241.78 - a combo between A and C - Sophie (Talk) 18:21, 4 November 2010 (UTC)
- Any text editor or wordprocessor would do a) by default as far as I am aware. For c), get Duplicate Cleaner to scan the directory your files are in. 92.15.10.141 (talk) 12:49, 5 November 2010 (UTC)
question
How could I automatically archive web pages I visit —Preceding unsigned comment added by 140.121.130.67 (talk) 18:04, 3 November 2010 (UTC)
- on wikipedia? you could add them to your watch list. For web broswing, they are in your history but im not sure about whole pages. sorry. Sophie (Talk) 19:39, 3 November 2010 (UTC)
- You might find the Internet Wayback Machine useful for looking at older versions of websites - that has archives going back to the early 1990s in some cases. Chevymontecarlo 21:21, 3 November 2010 (UTC)
- some pages might not be avilable because if someone has robots.txt in the root page - Sophie (Talk) 18:23, 4 November 2010 (UTC)
- You might find the Internet Wayback Machine useful for looking at older versions of websites - that has archives going back to the early 1990s in some cases. Chevymontecarlo 21:21, 3 November 2010 (UTC)
- The Scrapbook plug-in for Firefox will allow you to archive web pages locally with about as much effort as it takes to bookmark them, but it is not strictly automatic. --Mr.98 (talk) 21:36, 3 November 2010 (UTC)
Subnetting
The network 131.217.0.0 has been split into subnets using the subnet mask 255.255.255.192.
Find the number of bits that have been borrowed from the host field, the number of usable subnets, and the number of usable addresses per subnet.
Hence, show the range of usable IP addresses by stating the first and last usable host addresses for the first and last subnets.
My conclusion is that this is a class B network and hence the number of bits borrowed in 10. The number of usable subnets is therefore 1022 and the number of usable addresses per subnet is 62. How do you do the last part of the question? 115.178.29.142 (talk) 23:10, 3 November 2010 (UTC)
- The last two numbers of the IP address are 0.0. That is what can be split up. The network mask on the last two numbers is 255.192, or 11111111.11000000. So, 10 bits are for the subnet and 6 bits are for the host. For the first subnet, the 10 binary digits will be 0000000000. For the last subnet, the 10 binary digits will be 1111111111. For the first host, the 6 binary digits will be 000000. For the last host, the 6 binary digits will be 111111. So, for the first subnet, you have 131.217.00000000.00000000 to 131.217.00000000.00111111 (yes, I mixed decimal and binary). In all decimal, that is 131.217.0.0 to 131.217.0.63. The last subnet will replace the 10 zeros for the subnet with 10 ones. -- kainaw™ 23:44, 3 November 2010 (UTC)
- You need to consider, though, that the subnet broadcast address is not usable as a host's IP. PleaseStand (talk) 23:51, 3 November 2010 (UTC)
Here's a visual. In binary, 131.217.0.0 is (converting each octet into binary, putting them together in order, and breaking it up into "bitfields"):
10000011110110010000000000000000
|--------------||--------||----|
original subnet # host
For the first address, you want to set the subnet and host bitfields to binary one (assuming that subnet zero is not usable in this problem). For the last address, you want to set the subnet and host bitfields to all ones except the last bit in each, which should be a zero (the last address in a subnet is the broadcast address and is not available for assignment). Converting back to standard IP address notation will give you your final answer. PleaseStand (talk) 23:51, 3 November 2010 (UTC)
- And for the last address in the first subnet and the first address in the last subnet, it should be then clear enough what to do. PleaseStand (talk) 23:56, 3 November 2010 (UTC)
- I was purposely ignoring IP rules to avoid confusion, but I now see that the question specifically states "usable IP addresses". -- kainaw™ 23:55, 3 November 2010 (UTC)
Unless this is a class on computer history, you (and your teacher) should probably know that the question is horribly out of date. Classful_networks were used on the internet from 1981 to 1993. These days terms such as "Class B network" only have meaning in a historical context. 130.188.8.12 (talk) 13:37, 4 November 2010 (UTC)
- Yes, using network "classes" was a big waste of IP addresses that should have been ended much sooner. In the current CIDR notation, your original network is 131.217.0.0/16 and the subnets you have broken it into are /26 networks (there are twenty-six bits before the host number part). PleaseStand (talk) 21:06, 4 November 2010 (UTC)
November 4
Newsgroup / computer newbie type question
Having recently joined a couple of newsgroups (one is alt.usage.english) I have been happily posting. I type in MS Word, and then paste it into the newsgroup. What I would like to do is set up a blank MSWord document template so that it has exactly the proper margins, left and right, so I know that WISIWIG. That is, I know that my MSWord writing will appear just like that in the newsgroup, so I can make it look perfect. I don’t know where else to ask for help, as Google have discontinued their help desk forum. Any idea on how to do that?
Also while I’m here, I’m told that Google does not have the capacity for a sig file on newsgroup contributions. I don’t know why not, but I would like one on my posts. Any idea on how that could be done? Myles325a (talk) 04:23, 4 November 2010 (UTC)
- Unless there has been a mighty change in how usenet works, newsgroups do not have any of the formatting you are concerned about. It is plain text. Google performs formatting based on common trends in newsgroups. For example, if I type _this_, Google will make it look like this. Margins do not exist. You are just seeing the text in the width that your browser allows. But, ignoring that this is based on a misconception... you want a document template. Open Word. Get the page set up just like you like. Save it as a template. In the save window, you will see types of files to save. Choose template. Then, next time you want to work, open the template and it will have all your formatting in place. -- kainaw™ 12:05, 4 November 2010 (UTC)
- You can send encoded text, e.g. HTML. However it's considered very bad form in the vast majority of newsgroups (well I don't know any that allow it but I always say it's a bad idea to use absolutes). Nil Einne (talk) 20:08, 4 November 2010 (UTC)
Building a Storage Area Network Head - Operating System
Hello Everyone,
I am exploring the option of building my own SAN head. I'm aware that a SAN head consists of a motherboard, processor(s), memory, a RAID controller, and a load of HDDs; but I want to know what software a SAN head runs on. I assume that it must have an operating-system which operates the management and assignment of LUNs to multiple hosts, and I want to know what software provides these functions (and whether there are any open-source SAN operating-systems available)?
Thanks as always. Rocketshiporion♫ 05:43, 4 November 2010 (UTC)
- You can make a network accessible file system using Linux and NFS, FUSE/SSH, or SAMBA. Technically, that is a file server. Network-attached storage, storage area network, and file server differ in the "layer" that they provide. You'll have a hard time building a SAN out of commodity hardware and free software; and you probably won't reap the cost/performance benefits unless you are scaling to truly enormous enterprise sizes. As CPU costs decrease and performance becomes trivial, file servers are probably your best bet - let the remote system handle the file system details and provide the attached storage space at a high-level, as a network drive. Regarding specific software: you can run a NAS or file server using any Linux; BSD is popular; and FreeNAS is basically a pre-configured FreeBSD installation with fewer general-purpose features. The best choice ultimately depends on your needs. Nimur (talk) 06:12, 4 November 2010 (UTC)
- You can build an open source SAN using technologies such as Logical Volume Manager (Linux) (to create and manage the LUNs) and a block device exporter (eg vblade or an iSCSI-target). Googling 'linux san' will give you various guides and distributions on how to set such things up. Whether you would want a SAN (exporting block devices) or a NAS (exporting file systems) depends a lot on your requirements. Unilynx (talk) 06:48, 4 November 2010 (UTC)
The specific purpose is for four diskless computers to each be connected via iSCSI to its boot volume. AFAIK, it's not possible for computers to boot from a NAS or file server. The four diskless computers will also be clustered, and be connected to a shared LUN (which is also to be stored on the SAN). As for cost, all I really need (other than the operating-system) in terms of commodity hardware are; a motherboard, a processor, some RAM, a quad-port Ethernet card and a few SATA HDDs; which I estimate can be obtained for under $2,000. Rocketshiporion♫ 13:05, 4 November 2010 (UTC)
BitTorrent
I was reading the article on it, including the part where it mentions that computers on the network that have full versions of the file are called seeders. That there's a special name for computers that have full versions implies that there are other computers that have pieces which would seem to be useless to them. Is having a bunch of pieces which are of no use to you (in addition to whatever full files for which you are a seeder) just the cost of being a reputable member of a swarm? 20.137.18.50 (talk) 13:35, 4 November 2010 (UTC)
- A computer with only some pieces of the file can share those pieces with others, and vice versa. So even if there are no seeders at all, the various pieces across the swarm can account for the entire file and thus the entire file can still be downloaded. This is good because it means seeders aren't the only source for the file 82.44.55.25 (talk) 13:53, 4 November 2010 (UTC)
- A main benefit of bittorrent is that while you are downloading a file, you can share the parts of the file you already downloaded with other people who are downloading it. Often, more people are downloading a file than there are seeders. So, most people only have parts of the file. As a courtesy, it is common to keep connected after you download a file, becoming a seeder. You no longer need any parts of the file, but you share what you've got for a while just to help others. -- kainaw™ 13:56, 4 November 2010 (UTC)
- Nobody has files which are "useless" to them, because they are, presumably, interested in eventually downloading the entire file. So just because I have the last 25% of the file in question and not the first 25%, doesn't mean that the last 25% is useless to me (even if I can't "use" it for anything at this point), because presumably I'm hoping to get the entire file, and the last 25% puts me that much closer to that goal. Remember that people aren't just hosting because they are being generous — the entire point of a torrent is to distribute the file on all of the computers participating, including those who are participating in distributing it.
- Seeders are special because they have the entire file yet are still distributing — thus they are being somewhat altruistic, because at that point, there is no personal gain to distributing the file (because the only "gain" in distributing is that you get a copy of it yourself). They aren't required but it greatly helps make sure there are redundant copies of the entire file on the network, which speeds things up (because maybe otherwise the only fellow who has on part has a very slow internet connection, thus introducing a bottleneck until others get that part... without seeders, it is not uncommon to see torrents "stuck" at 99%, never quite able to find that last 1%). --Mr.98 (talk) 14:06, 4 November 2010 (UTC)
- I think there's a basic misunderstanding here, but I'm not sure where. When you join a swarm you have none of the file. While you're downloading you'll be accumulating pieces of the file. The pieces are not, on their own, useful to you because you want the entire file, but you can redistribute those pieces to people who don't have them yet. (Everyone downloads the pieces in a different order, so even if you've only downloaded one piece, you can still help people who are halfway finished.) Eventually, if you keep downloading, you'll have the entire, complete file. (You'll have all the pieces.) You are now a "seeder", and ideally you'll continue distributing pieces to people that need them, though that's not strictly necessary.
- Unless there's a glitch, at no point will you download a 'piece' that you don't personally need to complete a file that you personally are trying to download. APL (talk) 15:17, 4 November 2010 (UTC)
does exist any c syntax that is forbidden in c++?
t.i.a. --217.194.34.103 (talk) 14:19, 4 November 2010 (UTC)
int new = 0;and many others. --Stephan Schulz (talk) 14:22, 4 November 2010 (UTC)- To clarify, C++ reserves some extra keywords. In C they would be valid as variable names or function names, but in C++ they are reserved for the use of the language. Here's a list of C++ keywords not reserved in C :
asm dynamic_cast namespace reinterpret_cast try bool explicit new static_cast typeid catch false operator template typename class friend private this using const_cast inline public throw virtual delete mutable protected true wchar_t
- APL (talk) 15:09, 4 November 2010 (UTC)
- And this is valid C89, but not C++
- APL (talk) 15:09, 4 November 2010 (UTC)
int test()
{
int i;
i=1 //**/1;
return i;
}
- The code requires // not to be a comment marker, which is true for C89/C90 and older. However, the code is formatted for C99, which will reject it.
- Also, in C,
- The return type can be unspecified (defaults to int), must be specified in C++
- The parameter-list can be 'void', must be empty if no params in C++ (which can mean K&R param passing in C)
- K&R param passing is allowed (but discouraged)
- The parameters to main can be what every you want - in C++ main must be on of
- int main()
- int main(int, char**)
- int main(int, char**, /* any other params */)
- In C void* can be implicitly cast to any pointer type; C++ needs an explicate cast. —Preceding unsigned comment added by Csmiller (talk • contribs) 15:27, 4 November 2010 (UTC)
- CS Miller (talk) 15:24, 4 November 2010 (UTC)
- See Constructs valid in C but not C++. --Sean 18:12, 4 November 2010 (UTC)
- The article linked to by Sean is a very, very good starting point. For more differences, see Annex C of the C++ standard (ISO/IEC 14882:2003). For example, . Regards,
int main(void) { return main(); /* valid (but useless) C, invalid C++ */ }
decltype(talk) 05:20, 5 November 2010 (UTC)
hard drive
Can I leave my external hard drive on 24/7, or should I turn it off when not in use? My computers internal drive is on 24/7, is there a difference between internal and external ? —Preceding unsigned comment added by 91.193.69.210 (talk) 14:51, 4 November 2010 (UTC)
- Most computers will put a drive to sleep if it is inactive for a period of time, so leaving the drive powered up is not itself a problem. Any drive will wear out over time (so always make backups) but for the most part drives will outlast computers, unless you keep your computer a long time or make heavy, heavy use of the drive (constant read-write action). --Ludwigs2 15:25, 4 November 2010 (UTC)
- [citation needed] on the claim that "for the most part drives will outlast computers". Comet Tuttle (talk) 16:28, 4 November 2010 (UTC)
- I'd read this as "computers get replaced before hard drives fail", not as "usually other components fail before the hard drive". But yes, a source for either interpretation would be nice. --Stephan Schulz (talk) 16:32, 4 November 2010 (UTC)
- [citation needed] on the claim that "for the most part drives will outlast computers". Comet Tuttle (talk) 16:28, 4 November 2010 (UTC)
- Depending on how you look at it, the MTBF of a hard disk (and all the other components) is less than the average time a computer is in primary use thanks to the software lifecycle. Greenpeace quotes a figure of 2 years for the average PC lifespan in developed countries, but this is not cited. Regardless, it's obvious by the tonnage of computers that show up in the landfill and the number that fly off shelves to replace them that the used life isn't that long. I would be shocked if it were more than 5 years in the US; most HDD warranties are as long. --Jmeden2000 (talk) 17:56, 4 November 2010 (UTC)
- Again, please provide citations. This is a reference desk. Simply discussing warranties and the MTBF claims (which are notoriously exaggerated by the manufacturers) isn't evidence of anything. Comet Tuttle (talk) 18:48, 4 November 2010 (UTC)
- But ah, we are not writing a scholarly article we are trying to come up with a useful answer to the question at hand. No offense, but his question is no closer to being answered as a result of putting [citation needed] next to every response. --Jmeden2000 (talk) 13:40, 5 November 2010 (UTC)
- Again, please provide citations. This is a reference desk. Simply discussing warranties and the MTBF claims (which are notoriously exaggerated by the manufacturers) isn't evidence of anything. Comet Tuttle (talk) 18:48, 4 November 2010 (UTC)
- CT, relax. the point is that a hard disk is not going to unduly suffer by being powered on continuously, unless it is also subjected to extreme conditions (high levels of disk read/writes, excessive temperatures, etc). A hard disk is obviously more likely to fail than the computer itself (by virtue of moving parts), but hard disks are constantly increasing their lifespan through technological improvement, and the average consumer replaces his computer at regular intervals. The OP should not worry about it beyond the normal caution to maintain regular backups. --Ludwigs2 21:50, 4 November 2010 (UTC)
- "but hard disks are constantly increasing their lifespan" - well, that's arguable. We have a batch in a large recording system over here where 20% per year are failing...big-brand, heavy duty server class drives at that. Hard drives are optimized for capacity, speed, price, and reliability, and I would expect priorities to be roughly in that order. --Stephan Schulz (talk) 21:59, 4 November 2010 (UTC)
- CT, relax. the point is that a hard disk is not going to unduly suffer by being powered on continuously, unless it is also subjected to extreme conditions (high levels of disk read/writes, excessive temperatures, etc). A hard disk is obviously more likely to fail than the computer itself (by virtue of moving parts), but hard disks are constantly increasing their lifespan through technological improvement, and the average consumer replaces his computer at regular intervals. The OP should not worry about it beyond the normal caution to maintain regular backups. --Ludwigs2 21:50, 4 November 2010 (UTC)
- All of the computers that I've had fail on me (2 of them) have been failed hard drives (well, I had a CD drive fail, but I still used the computer for a bit). There have been many more computers that I've gotten rid of before anything fails, but I would say that a hard drive, with mechanical moving parts, is one of the most likely things to fail on a computer. Interestingly this site says that power supply issues are the number one way to fry your computer. I've yet to have a power supply problem. Buddy431 (talk) 01:22, 5 November 2010 (UTC)
- Here's a highly non-scientific poll of failing parts; storage drives have the plurality. Buddy431 (talk) 01:24, 5 November 2010 (UTC)
polynomial shift
I have the coefficients of a polynomial of one variable. I want the coefficients of the equivalent polynomial in terms of another variable (u=t+constant); in other words, the function that defines the same curve with a shifted origin. Before I reinvent the square wheel, is there a more efficient way than expanding and adding up the results? (Or better yet a numpy library function?) I'd search but I don't know the appropriate keyword. —Tamfang (talk) 17:11, 4 November 2010 (UTC)

{kind=link}
{kind=link}
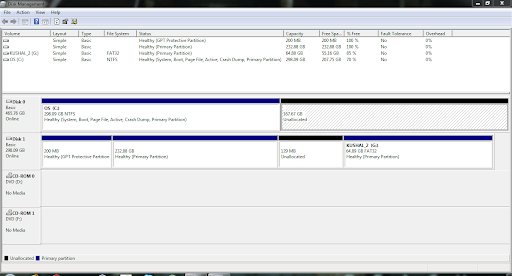{kind=link}
- You've got a function
f(x)=a0+a1x+a2x2+a3x3+ etc etc
- and you want to know the b's in
f(x)=b0+b1(x-c)+b2(x-c)2+b3(x-c)3+ etc etc
- then Taylor series will work (in many cases, in particular for polynomials) and gives you bn's fairly trivially, since
bn=(1/n!) x dn[f(x)]/dxn evaluated at x=c
- Is that what you want - it's easier to implement (and quicker I think) than the expansion (especially when it's a long polynomial) , ask if you want pseudocode
- (apologies if that isn't what you are asking, I'm a bit sleepy). I've given you two functions that give the same value for a given x? (on second thoughts it may not be any better than the binomial expansion, maybe, maybe not) 94.72.205.11 (talk) 20:35, 4 November 2010 (UTC)
- Treating it as a Taylor series makes eminent sense; it may not be speediest, but it's easy on the programmer. Thanks. —Tamfang (talk) 05:59, 5 November 2010 (UTC)
Windows command prompt FOR loop
First, I am really sorry for clearing all previous information by accident. I don't know how it happened. Second, Does anybody have a solution for this problem? If I use the FOR loop under windows command prompt as in this example:
for /l %i in (1,1,10) do (@set x=%i
@echo %x% , %i)
The result is:
)
10 , 1
C:\>(
)
10 , 2
.
.
.
)
10 , 10
Why does x always take the value of 10 rather than i?--Email4mobile (talk) 17:54, 4 November 2010 (UTC)
- See this page for the solution. -- BenRG (talk) 04:46, 5 November 2010 (UTC)
- So all I had to do was just set the local variable at the beginning as in this line:
setlocal ENABLEDELAYEDEXPANSION
- Thank you very much.--Email4mobile (talk) 09:03, 5 November 2010 (UTC)
How has this image been generated?

How has this image been generated? I understand that the "crisp" version on the left is simply a screen grab, but I'm asking about the "blurry" version on the right. The "blur" is, after all, only present in the real, analog world, and the computer's memory is completely oblivious to it. So therefore a screen grab would produce an identical copy of the version on the left side, regardless of what the image was viewed on. Grabbing it via the real world instead of straight from the computer's memory, in other words by photographing it, would very likely not produce such a pixel-perfect copy with only the "blur" effect, because various real-world details would induce minute differences. Is the "blur" effect merely a simulation added afterwards, or what magic has been used? JIP | Talk 18:56, 4 November 2010 (UTC)
- I think you'd have to ask the person who made it to know for sure. I guess if someone took the left image, made the 3 colour layers into 3 separate layers (e.g. in gimp) and then moved one colour a pixel right, and another a pixel left) you'd get something like this. -- Finlay McWalter ☻ Talk 19:05, 4 November 2010 (UTC)
- No, it's a more complex effort. I verified it with xmag, and it's not as simple as shifting one RGB channel left and another right. I've asked the original creator, User:NewRisingSun, about it. Let's see if he responds. JIP | Talk 19:49, 4 November 2010 (UTC)
- The source code used to generate the image is on the image page. Does that help at all? --Tagishsimon (talk) 20:05, 4 November 2010 (UTC)
- No. The source code is only usable for direct screen grabs. It has no effect whatsoever on the image quality, because after all, the program itself is a mathematical abstraction, and as far as it is concerned, the image quality is always 100% perfect. JIP | Talk 20:27, 4 November 2010 (UTC)
- The source code used to generate the image is on the image page. Does that help at all? --Tagishsimon (talk) 20:05, 4 November 2010 (UTC)
- No, it's a more complex effort. I verified it with xmag, and it's not as simple as shifting one RGB channel left and another right. I've asked the original creator, User:NewRisingSun, about it. Let's see if he responds. JIP | Talk 19:49, 4 November 2010 (UTC)
- This is almost certainly a variant of what Finlay has suggested. Definitely generated by taking 3 slightly shifted (+/- 2 pixels) copies of the original image, possibly modifying them and superimposing them in some manner. So an attempt to digitally reverse engineer the imperfections of the analog world. 213.160.108.26 (talk) 23:34, 4 November 2010 (UTC)
- The image was probably generated with an emulator like DOSBox or MESS, or a program that uses similar algorithms to emulate CGA composite artifacts. Read on for a little bit about how such an algorithm might be created.
- To put the image in context for other responders here, it illustrates the color artifacts seen when the CGA adaptor is connected to an NTSC composite monitor, see Color Graphics Adapter - Special effects on composite color monitors. I myself was fascinated by the palette images shown a little lower in that section, and wondered how the patterns generated colors on the composite monitor.
- Edit: Just to clarify, in the image shown above, the screen on the left is what you'd see on an RGB monitor. The screen on the right is what you'd see on an NTSC monitor. The CGA adaptor sends different signals for an RGB montor than an NTSC monitor, so it's slightly incorrect to think of them as a "perfect" screen shot and a "blurry" real-world simulation of the same image. The CGA adaptor is using the same video memory pixels to generate both signals, but the RGB signal is able to represent the color of each individual pixel, whereas the NTSC signal must use a color wave that ends up being four pixels wide. —Preceding unsigned comment added by Bavi H (talk • contribs) 02:06, 5 November 2010 (UTC)
- Part of the answer requires you to know about how the NTSC composite signal works, especially the color burst and color encoding. I can't find a good description of the NTSC signal to link to yet. You can find information about how the NTSC signal works online, but you might have to read several different documents to get a good understanding of it.
- The other part of the answer is knowing what signals the CGA adaptor sends on its composite output. Go to CRTC emulation for MESS and scroll down to the section "Composite output" for details about that.
- Basically, for each CGA color, the CGA adaptor composite output generates a square wave shifted by a certain amount with respect to the color burst. In the 640×200 mode, the color wave is four pixels wide, so you can actually use groups of four black-or-white pixels to make your own color wave. If you shift the pattern by one pixel, you'll get a different hue. Here's an example I made with QBASIC running in DOSBox to help understand the order to the black and white patterns: cga-composite.png
{kind=link}
- In the 320×200 modes the color wave is two pixels wide, because the pixels are twice as wide. By carefully calculating where the CGA composite output color wave for each color is sliced and combined, then decoding the wave as an NTSC color signal, you can predict the resulting color on the composite monitor screen.
- After studying this, I began to see how the colors are predicted, but didn't go far enough into the math to understand it all. (For example, I don't yet understand how a square wave is "seen" as a sinusoidal wave of NTSC color signal. Edit: Or how partial or irregular color waves become color fringes like those in the text-mode image above.)
- While researching this I also found Colour Graphics Adapter Notes - Color Composite Mode which has a zip file with images captured from an actual CGA adaptor (captured using a TV card with an NTSC composite video input). It includes image captures of the same palettes simulated in the CGA article above. In also includes image captures of Flight Simulator, which is interesting to compare to the Flight Simulator images on the MESS video emulation page linked above. --Bavi H (talk) 01:18, 5 November 2010 (UTC)
who's got money? How do I find an investor with vision?
I want to find an investor with vision, so that if I explain to them in a few words what I would like their money for, they will see that (or whether) it works. I don't want to waste my breath on people who wouldn't understand anyway! How do I find these people? If anyone here knows, they can also leave some contact information and I can ask them personally. Thank you! 84.153.205.142 (talk) 20:42, 4 November 2010 (UTC)
- It depends entirely on the quantity of money you seek and what you plan to do with it. You can start by investigating bank loans and credit card advances. These organizations will happily lend you large sums of money, at market interest-rates, for you to use for almost any purpose. Nimur (talk) 21:47, 4 November 2010 (UTC)
- Unfortunately, your request is unlikely to be handed to you like this, because human communication is more difficult than anyone thinks, and everyone has their own opinions about things like risk and how likely your idea is to succeed. Business owners' ability to raise money is a core requirement of being a business owner, for most businesses; and usually they have to pitch their idea and plan many, many times before an investor says "yes". Our article Angel investor has some links in the References section that may help you. Comet Tuttle (talk) 22:24, 4 November 2010 (UTC)
- With the exception of people who already have a track record of building successful businesses, most inventors and entrepreneurs have great difficulty getting an angel investor even to speak to them. If they do, they mostly want to see a working prototype or a business that's generating revenue (Dragon's Den, for all its faults, isn't a bad indication of what angel investors are looking for). Tony Fernandes, who started Air Asia after seeing an Easyjet ad, mortgaged his house to pay for it. No-one was interested in James Dyson's ballbarrow, despite his having many working prototypes, so he mortgaged his house too. It took Ron Hickman, inventor of the Black and Decker Workmate years, and apparently about 100 prototypes, before he persuaded someone to market it; and Hickman had an impeccable record of design and engineering management, as the chief engineer of Lotus Cars he had already designed the Lotus Elan and Lotus Europa. Paul Graham (whose investment company Y Combinator is roughly an angel investor) has a bunch of what he/they look for when investing in new enterprises here. Several VC books I've read come to roughly the same conclusions: they invest in people (that is, people who have a proven track record of making stuff and getting things done) and in working product; some are pretty blunt in thinking that if you're still working at BigCo and haven't quit to work on the project yourself, to your own obvious cost and risk, then you don't believe enough in the thing, so why would they. -- Finlay McWalter ☻ Talk 23:09, 4 November 2010 (UTC)
- Nice overview, Finlay McWalter! Almost the first question any investor will ask (or research) is "What do you have in it?" And the answer should include great amounts (by your personal standard) of time, money and experience. Bielle (talk) 23:21, 4 November 2010 (UTC)
- The people I know who can drum up quick cash for projects use angel investors (as opposed to venture capitalists — the difference is the amount of money and control, angels being less in both, thus a bit easier to work with, they say). There are lots of sites that come up if you google "finding angel investors"; I've no experience in it (other than chats with friends who have made good on such things), so I can't tell what's good advice or not. I would note that exemplars (like those Findlay names) are not necessarily "normal" models — they are notable because they are rare cases for one reason or another. --Mr.98 (talk) 00:55, 5 November 2010 (UTC)
November 5
Problem after installing new video driver
Hi Reference Desk, I recently installed the ATI Catalyst 10.10 drivers for my ATI Mobility Radeon HD 5450 on Win7 64 bit. Now, it seems to be limiting the number of display colours, and when things with colour gradients are visible, for example the background of Microsoft Word, it looks like a compressed JPEG screenshot and there are very visible steps between the colours. I've recalibrated the display, reinstalled the driver, reset to factory settings, fiddled with Windows colour settings, all to no avail. I was wondering if this was a known issue, and/or if anyone had a clue how to fix it?
Thanks 110.175.208.144 (talk) 06:30, 5 November 2010 (UTC)
- At a rough guess, you might have been reset to basic colour. Press F1 for help, type Aero and open the Aero troubleshooter and follow the prompts to get Aero back... this might also fix your colour problems and get the 24/32 bit colour gradients back. The troubleshooters in Win7 are surprisingly good and can make some low-level changes when they have to. Worst case scenario - you can go into device driver and rollback the drivers. Sandman30s (talk) 09:12, 5 November 2010 (UTC)
Automatic form filling application required
Job applications and other bureaucratic documents take too long to fill in neatly. Is there any application (preferably free, with source code in VB6 of VC++6) that I could either use directly or modify to (1) recognise the various rows, columns and common questions that need filling in, by both text and graphics recognition, with a manual mail merge type option if this fails, and (2) using a database, fill in the form in all the right places. Unlike mail merge in MS Word, it would have to fill in lots of separate sections instead of just one (the address) and of course the size would be standard A4-I can't get this size using MS Word, or at least my version, which is a few years old. —Preceding unsigned comment added by 80.1.80.5 (talk) 13:19, 5 November 2010 (UTC)
- No. The field labels in forms are often ambiguous. So, a computer will need to understand the purpose of the form to attempt to understand the meaning of the field label. Since computers cannot think, they cannot fill out forms. At best, a computer can assume "Name" means your full name and "DOB" means your date of birth. But, it wouldn't understand what to do if "Name" was the name of your dog or "DOB" is the date on the back of your passport. In the end, you (the human) must read every label and decide what to put in every field. -- kainaw™ 14:22, 5 November 2010 (UTC)
"number of cores" on 15" Macbook Pros?
Hi,
It is not clear to me, there are three configurations of Macbook Pro:
1) 2.4 Ghz i5 2) 2.53 Ghz i5 3) 2.66 Ghz i7 (with 2.28 Ghz)
What is the real performance difference? Are the first two both dual-core? Only the third one says "which features two processor cores on a single chip"??
Plus, as an added point of confusion, i7 has hyperthreading enabled, doesn't it? So, is it the case that option 1 and 2 are two cores shown to the OS as such whereas option 3 is two cores shown as four cores to the OS?
Or, is it exactly half of what I just said? Thanks! 84.153.205.142 (talk) 15:01, 5 November 2010 (UTC)
- based on the Intel page the i5 processors are either 2 or 4 core processors (depending on model - the Apple specs are not precise, though the 'features' page at Apple says dual core).
- cores are cores, they are not 'shown to the OS'. software needs to be written to take advantage of multiple cores, but for those apps that are you will see moderate increases in performance with the higher-end chips. This will be noticeable in casual use (apps opening slightly faster, long processes finishing slightly sooner), very noticeable in processor intensive tasks, and may increase the practical longevity of the machine itself (in the sense that future improvements in hardware, and the consequent revisions to software, won't leave the machine in the dust quite as soon). --Ludwigs2 15:35, 5 November 2010 (UTC)
- Wandering around the apple website confirms that all three chips are dual core. However this http://www.macworld.com/article/150589/2010/04/corei5i7_mbp.html gives the chip part no.s : i5 520M , i5 540M , and i7 620M , assuming that wasn't speculative and is true then all three have two cores, with hyperthreading, meaning a total of 4
coresthreads (or "4 virtual cores"). Finding out more info on these chips is trivial - just use search and the first result probably takes you to the intel page eg http://ark.intel.com/Product.aspx?id=47341 . The article MacBook Pro has the same info. - The second i5 is (as far as I can tell) just a faster clock. The differences between the i7 and i5 include a larger cache in the i7, but I wouldn't be suprised if there are other architectural differences. actually looking at generic benchmarks between these, seems to suggest that the i7 part is no different from an i5 with bigger cache, and higher clock, but that's speculation.94.72.205.11 (talk) 16:36, 5 November 2010 (UTC)
- probably not my place to say but looking at UK prices [1] it really looks like the additional costs of the better processored 15"s is way way way beyond either the base processor price different, and on the borderline or above of what is worth paying for. - the base model is easily good enough for 90+% of people. You can easily find 'real world' comparisons searching for "apple macbook pro benchmarks i5 i7" .94.72.205.11 (talk) 16:50, 5 November 2010 (UTC)
- Thank you: when you say that "software needs to be [specially] written to take advantage of multiple cores", are you just talking about hyperthreading, meaning that if I were just running a SINGLE processor-intensive application, it needs to be written in that way? Or, are you talking about something more general? Because don't two concurrently running different applications AUTOMATICALLY get put on their own core by the OS? In that sense, my reasoning is informed by the "dual-processor" behavior I had learned of a few years ago. In fact, isn't a dual-core, logically, just 2 processors? Or, is there a substantial difference as seen by applications and the OS between a dual-core processor, and two processors each of which is exactly the same as a single core? (I don't mean difference in whether they access as much separate level-1 and level-2 cache, I mean as seen by the OS and applications). If there is a substantial difference, what is that difference?
- I guess my knowledge is not really up to date and what I would really like to know is the difference between multiple CPU's (dual and quad CPU machines) of yesteryear power desktops, and multiple cores of today? Thank you! 84.153.205.142 (talk) 16:48, 5 November 2010 (UTC)
- There hasn't been any change of definition (one possibly source of confusion is that sometimes a processor can have two separate physical chips within it, or one chip with two processors on it - both are as far as end results are concerned - the same...)
- As per multiple processes on multiple cores or threads - yes you are right - the only time there isn't any advantage is when you run a single (non threaded) program on a multicore machine.94.72.205.11 (talk) 16:54, 5 November 2010 (UTC)
display size
Sorry folks. I know I asked this question a while back and got a great answer. problem is: I can't find the answer. I tried searching the archives but no luck. So, I will ask the question again (and save the answer!).
I am using Vista on an LCD monitor. When I go to the net, the size is 100% but this is too small. I set it at 125% but can't get the settings to stay there and have to adjust them each time. Can someone help me (again)? 99.250.117.26 (talk) 15:54, 5 November 2010 (UTC)
- It's Wikipedia:Reference_desk/Archives/Computing/2010 May 5#125% screen size.—Emil J. 16:00, 5 November 2010 (UTC)
Hmmm. That answer came in just under two minutes . . . Wikipedia is getting slow! lol. Thanks a lot. 99.250.117.26 (talk)