
User talk:Dsimic
| ↓ | Skip to bottom of the page | ↓ |
| Please place new discussions at the bottom of the talk page. |
| This is Dsimic's talk page, where you can send him messages and comments. |
Article policies
|
| Archives: 1, 2 |
 | In a few words, I prefer to keep discussions unfragmented. Thus, if you leave a comment for me here, I will most likely respond to it on this same page—my talk page—as an effort to keep the entire conversation in one place. Similarly, if I leave a comment on your talk page, please respond to it there. As a reminder, we can use our watchlists to keep track of when responses are made. At the same time, please feel free to send an alert to me on this page about a comment you have left elsewhere, or simply use the built-in notifications by mentioning my username while posting comments in other places. |

| This is a Wikipedia user talk page. This is not an encyclopedia article or the talk page for an encyclopedia article. If you find this page on any site other than Wikipedia, you are viewing a mirror site. Be aware that the page may be outdated and that the user whom this page is about may have no personal affiliation with any site other than Wikipedia. The original talk page is located at https://en.wikipedia.org/wiki/User_talk:Dsimic. |
| Manual of Style (MoS) |
|---|
Bit rot
Don't you hate it when that happens? ;) --168.215.131.150 (talk) 21:21, 19 September 2013 (UTC)
- Yeah, I really don't get it... There's something wrong with the crash / tabs recovery within Firefox – hm, it would be nice to trace it down and at least submit a reproducible bug report to Firefox developers. -- Dsimic (talk) 21:26, 19 September 2013 (UTC)
Replaceable fair use File:SATA Express host plug.png

Thanks for uploading File:SATA Express host plug.png. I noticed that this file is being used under a claim of fair use. However, I think that the way it is being used fails the first non-free content criterion. This criterion states that files used under claims of fair use may have no free equivalent; in other words, if the file could be adequately covered by a freely-licensed file or by text alone, then it may not be used on Wikipedia. If you believe this file is not replaceable, please:
{kind=link}
- Go to the file description page and add the text
{{di-replaceable fair use disputed|<your reason>}}below the original replaceable fair use template, replacing<your reason>with a short explanation of why the file is not replaceable. - On the file discussion page, write a full explanation of why you believe the file is not replaceable.
{kind=link}
Alternatively, you can also choose to replace this non-free media item by finding freely licensed media of the same subject, requesting that the copyright holder release this (or similar) media under a free license, or by creating new media yourself (for example, by taking your own photograph of the subject).
If you have uploaded other non-free media, consider checking that you have specified how these media fully satisfy our non-free content criteria. You can find a list of description pages you have edited by clicking on this link. Note that even if you follow steps 1 and 2 above, non-free media which could be replaced by freely licensed alternatives will be deleted 2 days after this notification (7 days if uploaded before 13 July 2006), per the non-free content policy. If you have any questions, please ask them at the Media copyright questions page. Thank you. Fut.Perf. ☼ 07:59, 3 October 2013 (UTC)
{kind=link}
SATA images
I have removed them from the article due to non-compliance with WP:NFC. Do not re-add them. Our policies on non-free media is very restrictive, and those are replaceable, and thus not acceptable. Werieth (talk) 20:04, 4 October 2013 (UTC)
- Ok, will re-tag the pictures as orphaned. -- Dsimic (talk) 20:07, 4 October 2013 (UTC)
Uop Cache
Dude whats your problem with my aricle that was revelant information. You yourself make blog if you want to.Oranjelo100 (talk) 10:11, 7 October 2013 (UTC)
- Please excuse me, but can't you see how did you write your sentence above? It has a few misspelled words, and it's such a simple sentence. Also, for those two sentences above you needed four commits, what makes little to no sense – if you agree.
- All I wanted to say is that you need to practice more before contributing to Wikipedia.
- Also, do you think I was born with the knowledge of English? No, and English isn't my native language. But, I've spent many years working hard on it, and I still don't consider it to be as good as I'd really want it to be – so I still keep learning it. Learning and practicing is the key – but only when performed in appropriate places. When people learn and practice for their drivers licenses, do they go straight to highways doing 100 mph? Please consider Wikipedia to be some kind of a highway.
- How about placing your edits into sandboxes, so other people can have a look at them first? -- Dsimic (talk) 12:12, 7 October 2013 (UTC)
- Just noticed that you also selected a wrong section title level for your addition to my talk page, so I fixed it. :) Can't you really see your own mistakes, and learn from them? Is there anything more I can do in order to make noticing your own mistakes easier for you?
- Please note that the contributions are good, but not in case fixing them requires more effort than the actual contribution would require by itself. Also, each system has its own rules, and that applies to Wikipedia too. -- Dsimic (talk) 12:25, 7 October 2013 (UTC)
- Maybe stop arrogantly patronizing me, and you still didn't respond why you deleted relevant information from uop cache.
- You're probably right, as I'm obviously wasting my time trying to provide some suggestions to you on how you should improve yourself. That actually makes me a bigger fool.
- Back to your question, I've deleted some of the stuff you added there because it was (a) written in very bad English; and (b) contained hardly verifiable platform-specific information that actually doesn't help explaining the micro-op cache to the people who will be reading the article.
- Hope that answers your question. -- Dsimic (talk) 15:38, 7 October 2013 (UTC)
- Btw, please sign your posts on talk pages. That's one of the rules here. -- Dsimic (talk) 15:42, 7 October 2013 (UTC)
- You are full of yourself instead of acting high and mighty explain what you mean by very bad english and hardly verifiable platform-specific information .L1 cache is commonly used term and you deleted relevant technical information about uop cache inner workings.
- I'm really sorry about your true inability to see your own mistakes. Every single article you touched, ended up looking like a real mess. You are unable even to properly space words, or to use periods and commas properly. It's all the same to you, those little dots on the screen seem to be irrelevant. Are you using some kind of an automated translation engine to produce such "Me Tarzan, you Jane" English? -- Dsimic (talk) 19:41, 7 October 2013 (UTC)
Texting: The choice of a new, illiterate, generation... Thanks for the laugh, Dsimic! Props to you for trying. PaulMEdwards (talk) 10:52, 11 April 2014 (UTC)
- @PaulMEdwards: Hello there! You're welcome, and I'm glad that someone actually reads the stuff I'm putting into Wikipedia. :) Though, I'm asking myself quite often whether all that makes sense? Wikipedia is a great thing, no doubt about that, but who cares about all the effort so many people are putting into it? — Dsimic (talk | contribs) 01:54, 12 April 2014 (UTC)
- @Dsimic: Well, you and I, and certainly a few others, do care... Isn't that enough? Hopefully future generations will look back upon us as akin to the scholars who founded the Library of Alexandria. We stewards of information must remain vigilant and diligently curate this valuable resource. — PaulMEdwards (talk | contribs) 20:25, 25 April 2014 (UTC)
- When looked from that side, it makes sense. Though, do you really think that new generations and "modern people" care about the Library of Alexandria, or about the older (or more complicated) stuff available on Wikipedia and elsewhere?
- A few days ago I watched a motherboard unboxing video on YouTube, and the presenter (a young guy) wasn't sure what's actually provided by the expansion slot bracket that came bundled with the motherboard – and it was a serial port. He was like "is it a VGA port? not sure, but don't need it anyway", what really struck me. Also, he just tossed away the manual, which is for that particular motherboard full of extremely valuable information and simply a must-read. Though, all that guy cares about is to stick two graphics cards into it, click ten times to get a running installation of Windows, and spend countless hours with W, A, S and D keys.
- Library of Alexandria? C'mon. :) — Dsimic (talk | contribs) 02:58, 26 April 2014 (UTC)
SATA Express wiki page
Hi Dsimic,
Thanks for the explanation after you reverted some of our edits back to their original form. All makes sense.
However, with that said, we would like to request a few edits to the Serial ATA Express (SATA Express) wiki page: https://en.wikipedia.org/wiki/Serial_ATA_Express
- Would you change the title of this page to SATA Express (as opposed to Serial ATA Express)? This is how the specification is usually referenced in papers and publications.
- SFF-8639 connector is referenced as the device connector. Although it can be used that way, this connector is not part of the SATA Express spec. Is there anyway you could edit this to make it clearer to readers?
Let me know if you have any questions or concerns to the requests above.
Many thanks,
Jbalich (talk) 19:30, 11 October 2013 (UTC)
- Hello there!
- I'm glad you're Ok with the edits I performed. Thank you very much for your suggestions, especially regarding usage of the SFF-8639 connector — that's something I haven't described well enough within the article. Already went ahead and edited the SATA Express article so it properly describes used connectors, please check it out.
- Also, I agree about the renaming, it's going to be shorter and better that way — and that's how all the papers are referring to the interface itself. I'll ask the admins tomorrow to perform the article renaming, can't do that myself as the SATA Express article already exists in form of a redirect (and copy&paste is not an option as commits history gets trashed that way).
- -- Dsimic (talk) 05:46, 12 October 2013 (UTC)
- Renaming of the article is done. :) -- Dsimic (talk) 02:25, 13 October 2013 (UTC)
- Looks great, thanks for your edits to the connector section! Also, I appreciate your help in renaming the page! On another note, are you able to add an image to the SATA Express page? I found a simple yet informative image of hosts and drives from the SATA Express page on sata-io.org, found here: https://www.sata-io.org/sata-express — Preceding unsigned comment added by Jbalich (talk • contribs) 15:54, 14 October 2013 (UTC)
- You're welcome. :) I'm glad you like it, and I'm really hoping that the whole article will help anyone in understanding better what's SATA Express about, as it can be quite confusing at the beginning.
- Regarding adding images, Wikipedia is very, very strict about disallowing non-free images. I've already uploaded images of all five types of connectors used for SATA Express, in form of plain black-and-white sketches borrowed from a SATA-IO paper, and they were quickly deleted as disallowed. Well, it took me at least 45 minutes to crop, export and upload those wasted pictures. :) It's all about preventing any copyright issues down the road... Basically, unless it's a picture of a building that's been taken down, or a picture of no longer alive person — only the pictures you've taken yourself (or graphs created from an empty canvas) are allowed here.
- -- Dsimic (talk) 16:09, 14 October 2013 (UTC)
- I see, thanks for the clarification. If I had permission from SATA-IO (the owner of the above mentioned image) to post this image, how would I go about getting it up on the page? Once again, thanks for your help! Jbalich (talk) 16:43, 14 October 2013 (UTC)
- You'd have to obtain a "free to use" license from SATA-IO for the particular image, in form of a page on their site explicitly stating such a license. With that available, you should provide URL of that page while uploading the image using the Wikipedia's File Upload Wizard (Toolbox --> Upload file on the left side of Wikipedia's standard layout). That would be basically it, together with adding image to the article itself.
- Quite frankly, I'd say you'd be much better re-creating the illustration yourself, than chasing the SATA-IO for a license. You'd save yourself from a lot of pain. :) -- Dsimic (talk) 17:16, 14 October 2013 (UTC)
- Got it, thanks again! Jbalich (talk) 17:29, 14 October 2013 (UTC)
- You're welcome. -- Dsimic (talk) 17:35, 14 October 2013 (UTC)
Hi Dsimic,
I'd like to break out U.2 as a separate page for the connector formerly known as SFF-8639[1]. There is a draft available now (https://en.wikipedia.org/wiki/Draft:U.2_(SFF-8639))
Thanks! Jmhands (talk) June 9, 2015 (UTC)
- Hello! If I'm not mistaken, the draft you've linked above doesn't exist, and I've even tried one or two alterations of the draft name with no success. Any chances, please, for a working link to the draft you're referring to? — Dsimic (talk | contribs) 21:24, 9 June 2015 (UTC)
- There was an extra parenthesis at the end. Please try: https://en.wikipedia.org/wiki/Draft:U.2_(SFF-8639) — Preceding unsigned comment added by 192.55.54.40 (talk) 21:07, 11 June 2015 (UTC)
- Ugh, thanks – my bad, somehow managed to totally overlook that erroneous parenthesis. Had a look at the draft, it would require quite a lot of further work to qualify as an article. Jmhands, would you be Ok if I'd take your draft as a basis for the final version of the U.2 article? Of course, you'd receive appropriate attribution. — Dsimic (talk | contribs) 05:51, 12 June 2015 (UTC)
- Of course - feel free to continue adding to the article to make it more clear. — Preceding unsigned comment added by 192.55.54.36 (talk) 14:24, 8 July 2015 (UTC)
- Thanks, please also see my comments in the § Enlist your help to make U.2 (SFF-8639) page great! section below. By the way, I presume that an expression such as
192.55.54.0/24 == Jmhandsholds true as those IP addresses belong to an address block assigned to Intel? :) — Dsimic (talk | contribs) 14:39, 8 July 2015 (UTC)
- Thanks, please also see my comments in the § Enlist your help to make U.2 (SFF-8639) page great! section below. By the way, I presume that an expression such as
References
- ^ "2015technology | SFFWG Renames PCIe SSD SFF-8639 Connector To U.2". http://www.2015technology.com. Retrieved 9 June 2015.
{{cite web}}: External link in|website=
M.2 (NGFF) page
Can we change the title of the "Next Generation Form Factor" wiki page to "M.2"? NGFF is its former name and I feel that the page should reflect that change as it is listed on many other pages by its proper name "M.2". Thanks! Jbalich (talk) 18:54, 29 October 2013 (UTC)
- Hello there! That's a good proposal, things changed in the meantime and it should improve the clarity. I've placed a request for admins to perform the rename, as the M.2 article already exists as a redirect page. -- Dsimic (talk) 19:51, 29 October 2013 (UTC)
- Thanks much! Jbalich (talk) 20:29, 29 October 2013 (UTC)
- You're welcome. -- Dsimic (talk) 20:32, 29 October 2013 (UTC)
We don't need to revert other people's edits in order to modify additions for flow, structure or readability. A simple cut/paste/edit would suffice and also permit others to see what was done. Nobody owns a wikipedia page. Blouis79 (talk) 21:32, 29 April 2015 (UTC)
- Hello, Blouis79! I'm slightly confused, which edit(s) do you refer to? These two back from November 2013, if I'm not mistaken? Those two edits were followed by three more edits made by an IP address, which unfortunately introduced next to no improvements so they were reverted. Together with that, I've also incorporated (they haven't been reverted) your edits into the article, by converting the external link you've added into a reference, and by deduplicating the wording so we don't repeat what has been pretty much already explained in the article (support for different interfaces on the same M.2 connector and associated connector keying).
- Moreover, the article has been further expanded in subsequent edits, inspired primarily by your two edits, what's for example visible in this edit. At the same time, there was no need to note that Tyco says something about the M.2 connector, as Tyco is only one of the manufacturers that make the connector; it's perfectly fine to use manufacturer's papers as references, but there's no need to mention a non-exclusive manufacturer.
- I've even left a message on your talk page that "I've reverted and then reworked your edits to the M.2 article, so they now fit better into the previously present content", and we could have discussed it further. Please don't get me wrong, but the whole thing isn't called owning an article, that's in fact a process known as peer review with making articles better as the only goal. Hope you agree. — Dsimic (talk | contribs) 04:30, 30 April 2015 (UTC)
Regarding move request on Talk:Linux Gaming
Just a note, I went ahead and merged the two move requests on Talk:Linux Gaming. Having two separate move requests happening at once on the same talk page can be a bit confusing to readers, and it makes it so that consensus has to be form only once. Steel1943 (talk) 04:13, 1 November 2013 (UTC)
- Hello there! Looking great to me, less cluttered and a lot easier to discuss. Thank you for merging the move requests. -- Dsimic (talk) 13:02, 1 November 2013 (UTC)
Form factor
I'm more than happy to discuss anything - however; just because something's 'accepted' does NOT mean or make or correct. Wikipædia IS an encyclopedic work. If we follow your logic, then it's almost certain the (so-called) 'bastions' of American journalism would sink - dramatically in quality. However, they ALL have guides to proper language use. All of them. Regardless if their writers' personal idiosyncrasies, they write in a UNIFORM style.
Additionally, I was speaking to the head editor of PCWorld the other day (sheer coincidence) and HE brought up his displeasure with it's use by 'readers.' Another point; on ourpise, I forgot the gentleman's name, but, he 'writes' for an inline 'journal,' & he used INCORRECT grammar. When I pontes it out, he responded: 'rules are meant to b broken.' He must think he's Shakespeare - he's not.
Just 'because' is NOT an answer. We ALL need to uphold things. No - it's not 'the end if the world,' but it's WRONG to encourage continued MISuse. Finally. As I'm NOT changing the arrocle's structure, I fail to see HOW it has to be removed - by ... you. Of ALL people, it's people LIKE you who should ENCOURAGE PROPER use of words & speech. Why not just LEAVE it - if - IF - theirs an 'outcry,' THEN 'correct' it (lol).
But, in fact, all I did was WRITE it CORECTLY. — Preceding unsigned comment added by UNOwenNYC (talk • contribs) 23:46, 5 November 2013 (UTC)
- Hello there! I apologize for the confusion, please allow me to explain.
- Basically, "form factor" is something I've seen used in many places so far. There are even some definitions around, like this one, or this one. It's also used in other areas, for example while describing electric motors. That's why I was against editing it out, and also "configuration" isn't such a great general replacement word. It would be better to use "footprint" instead, though saying "hard disk footprint" would be quite awkward, if you agree. :)
- Please don't get me wrong, I'm all in for improving things whenever and wherever possible, and for not allowing "everybody does it that way" approaches to creep in. Many people are doing wrong things, and that isn't making wrong things right.
- Any chances, please, for describing in more detail why the "form factor" is actually wrong? Any examples, definitions etc.?
- -- Dsimic (talk) 00:14, 6 November 2013 (UTC)
Reviewer

Hello, following a review of your contributions, I have enabled reviewer rights on your account. This gives you the ability to:
- Accept changes on pages undergoing pending changes,
- Have your changes automatically accepted on pending changes level 2 protected pages, and
- Administrate article feedback.
Please remember that this user right:
- Can be removed at any time for misuse, and
- Does not grant you any special status above other editors.
- You should probably also read WP:PROTECT, since this user privilege deals largely with page protection. As the requirements for this privilege are still in a state of flux, I would encourage you to keep up to date on the WP:REVIEWER page. Feel free to ask me if you have any questions! Happy editing! Reaper Eternal (talk) 12:22, 16 November 2013 (UTC)
Thank you very much! I'll make sure to use this privilege only with the best intentions, and according to the Wikipedia rules. -- Dsimic (talk) 13:45, 16 November 2013 (UTC)
Re: Android 4.4 screenshot
The Android 4.4 "launcher" is exclusive to the Nexus 5, and is technically part of the Google Search app, it is not a stock component of Android, and requires the non-free Google apps in order to function (thus, I cannot consider it to be a stock screenshot of Android). All other builds of 4.4 (even from Google itself, ironically) use the stock launcher from 4.3. ViperSnake151 Talk 17:33, 19 November 2013 (UTC)
- You're totally correct there, and it might be some kind of a new product launch strategy for Google (so they somehow differentiate the Nexus 5 from other devices running 4.4), who knows. I've just edited the Android version history article so it states that pictured launcher is currently exclusive to the Nexus 5, please check it out. Hope you'll find that acceptable. -- Dsimic (talk) 18:14, 19 November 2013 (UTC)
- I still object because, despite how Google has promoted it, it is not a new feature of Android 4.4, and we are giving false expectations to readers. ViperSnake151 Talk 18:11, 19 November 2013 (UTC)
- I agree there, it's a launcher feature. Is it better after this edit to the article? -- Dsimic (talk) 18:23, 19 November 2013 (UTC)
- The launcher is part of the Google Search app. Updates to Google apps are not considered to be part of Android for the purposes of the version history article, because they are distributed through Play Store and not technically part of the stock Android system. And as you can see there, this launcher is "not" exclusive to 4.4, so its not a feature of 4.4 either (my Galaxy Nexus proudly uses it just fine, thank you very much) ViperSnake151 Talk 18:27, 19 November 2013 (UTC)
- Ok, makes sense. I can live with that. :) -- Dsimic (talk) 18:33, 19 November 2013 (UTC)
Speedy deletion nomination of File:RouterBoard R52n-M.jpg
{kind=link}

A tag has been placed on File:RouterBoard R52n-M.jpg requesting that it be speedily deleted from Wikipedia. This has been done under section F1 of the criteria for speedy deletion, because the image is an unused redundant copy (all pixels the same or scaled down) of an image in the same file format, which is on Wikipedia (not on Commons), and all inward links have been updated.
If you think this page should not be deleted for this reason, you may contest the nomination by visiting the page and clicking the button labelled "Click here to contest this speedy deletion". This will give you the opportunity to explain why you believe the page should not be deleted. However, be aware that once a page is tagged for speedy deletion, it may be removed without delay. Please do not remove the speedy deletion tag from the page yourself, but do not hesitate to add information in line with Wikipedia's policies and guidelines. Eeekster (talk) 20:50, 19 November 2013 (UTC)
{kind=link}
Number of edits (Oranjelo100)
It's none of your business how many edits J made.--Oranjelo100 (talk) 14:34, 20 November 2013 (UTC)
- It is my business to make Wikipedia better, and unfortunately your edits aren't helping in that. So, I need to point out what's wrong, so we can make it better together. Also, there are rules on Wikipedia we all need to obey, as we've already discussed. -- Dsimic (talk) 14:41, 20 November 2013 (UTC)
- J will use whatever references J will like J am not your servant. Do it yourself without deleting without deleting relevant information if you have problem and my edits help make Wikipedia better like them or not. You feel you are important when you talk about rules. — Preceding unsigned comment added by Oranjelo100 (talk • contribs)
- I don't want to sound important or whatever, and I don't want anyone to serve me. We're all here to play by the rules established by Wikipedia. All those rules are reasonable, and targeted at improving quality of the content provided through articles.
- On the other hand, you sound like a totally ignorant and unreasonable person, unable to see your own mistakes. For example, can't you see that you're using letter "J" instead of "I" when referring to yourself – and four times in a row above? Can't you see that? Also, why are you writing "gb" instead of "GB", for example? That's not a rule imposed by Wikipedia, that's something from the elementary school.
- Please, understand that you need to follow the rules, and to apply some common sense while editing. Otherwise, please get yourself a blog, and do whatever you want there. -- Dsimic (talk) 15:27, 20 November 2013 (UTC)
- My bad with J, English is not my native language but will make edits in whatever way I like and I will not make blog just to appease you don't you have anything better to do then stalking my edits and nitpicking everything. — Preceding unsigned comment added by Oranjelo100 (talk • contribs)
- English isn't my native language either, but I've spent many years learning it. Sorry, but I see no point in spending more time and words towards trying to educate you. You just don't want to accept anything, or at least take it into consideration. -- Dsimic (talk) 15:51, 20 November 2013 (UTC)
- And stop trying to discourage others from editing Wikipedia for example me. — Preceding unsigned comment added by Oranjelo100 (talk • contribs)
- Please excuse me, but I'm feeling sorry for your obvious lack of intelligence. -- Dsimic (talk) 16:23, 20 November 2013 (UTC)
- I feel sorry for you because you have to try make yourself feel superior by trying to put down others. — Preceding unsigned comment added by Oranjelo100 (talk • contribs)
- I'm trying to make you better, but you don't seem to understand that. Btw, please sign your posts. -- Dsimic (talk) 17:27, 20 November 2013 (UTC)
you will make me feel better when you will stop stalking and harrasing me. — Preceding unsigned comment added by Oranjelo100 (talk • contribs)
- You're taking all suggestions as if they were against you, but they're not. I'm telling all that so you can improve yourself, but that seems to be pointless as you simply don't understand.
- Once again, please sign your posts. -- Dsimic (talk) 18:29, 20 November 2013 (UTC)
- I don't need your help in improving myself like I said stop stalking my edits and making mocking messages on my talk page or any other messages for that matter I dont want to talk with you. Another issue is that you broke Wikipedia rules by making personal attacks against me. — Preceding unsigned comment added by Oranjelo100 (talk • contribs)
- Dude, you're ridiculous. I'll stop talking to you, as it's a totally pointless waste of my time. -- Dsimic (talk) 21:58, 20 November 2013 (UTC)
About your Third Opinion request: I am a regular volunteer at the Third Opinion project. Your request for an opinion has been removed because this is primarily a conduct dispute. 3O does not handle disputes which are primarily conduct disputes, which are handled through RFC/U, ANI, or ARBCOM. Regards, TransporterMan (TALK) 22:46, 20 November 2013 (UTC) PS: @Oranjelo100: While I express no opinion about any of the rest, you do need to sign your posts with four tildes. Failing to sign them makes following a conversation very difficult. Regards, TransporterMan (TALK) 22:49, 20 November 2013 (UTC)
Your request for rollback

Hi Dsimic. After reviewing your request for rollback, I have enabled rollback on your account. Keep in mind these things when going to use rollback:
- Getting rollback is no more momentous than installing Twinkle.
- Rollback should be used to revert clear cases of vandalism only, and not good faith edits.
- Rollback should never be used to edit war.
- If abused, rollback rights can be revoked.
- Use common sense.
If you no longer want rollback, contact me and I'll remove it. Also, for some more information on how to use rollback, see Wikipedia:New admin school/Rollback (even though you're not an admin). I'm sure you'll do great with rollback, but feel free to leave me a message on my talk page if you run into troubles or have any questions about appropriate/inappropriate use of rollback. Thank you for helping to reduce vandalism. Happy editing! – Juliancolton | Talk 04:38, 27 November 2013 (UTC)
Thank you very much! I'll make sure to use this privilege only with the best intentions, and according to the Wikipedia rules. — Dsimic (talk) 14:18, 27 November 2013 (UTC)
Sandy Bridge and FinFET
Hi there,
The idea was to link to the page and section: https://en.wikipedia.org/wiki/Multigate_device#FinFET
So a user who clicks the "FinFET" link will be directed to a section specifically about FinFETs, rather than a more general article about various multigate devices. Is that not the correct thing to do? Or is there another issue I'm not seeing?
InternetMeme (talk) 15:17, 28 November 2013 (UTC)
- Hello there! It's just a small confusion, please allow me to explain...
- FinFET is a redirect page, and that redirect was basically broken until a few hours ago, when I got it fixed. Previously, FinFET was redirecting to a section title anchor (and that section was renamed at some point in time) within the Multigate device article, and I edited both pages so an explicit anchor is now placed and used. That corrected the FinFET redirect, and it's also preventing such issues with renamed section in the future. Please check out the FinFET redirect, and these two edits: edit #1, edit #2.
- Hope it makes sense, please let me know if further explanation is required. — Dsimic (talk) 15:37, 28 November 2013 (UTC)
Desktop Enviroment
Whack! You've been whacked with a wet trout. Don't take this too seriously. Someone just wants to let you know that you did something silly. |
You have been trouted for: Under Microsoft windows Do not used "Windows" Xp" / "Windows 7" Used Lana and Areo okay?
- Thank you for pointing that out! I knew about Aero, but had no idea about Luna... What do I know, my migration to Linux took place back in 1998 or so. :) — Dsimic (talk) 04:09, 30 November 2013 (UTC)
A barnstar for you!

|
The Original Barnstar |
Under Microsoft windows Do not used "Windows" Xp" / "Windows 7" Used Lana and Areo okay?
Mathsquare (talk) 03:43, 30 November 2013 (UTC) |
- Thank you! It's somewhat funny I got a barnstar for something related to MS Windows, but that at least shows I'm not biased. :) — Dsimic (talk) 04:11, 30 November 2013 (UTC)
BLAST protocol edits
Dear Dsimic, please see the "talk" section of the BLAST (protocol) article for my response to your much appreciated attention to said article.Synchronist (talk) 01:54, 2 December 2013 (UTC)
- Hello there! I'm glad you're fine with my edits to the BLAST (protocol) article. :) Right now I'm reading you comments and further edits, and will be replying shortly. — Dsimic (talk) 13:33, 2 December 2013 (UTC)
Android 4.4.1 revision
I saw that you reverted my update. Thanks for catching the layout issue. It didn't seem to show up for me under preview or even after I saved the changes until I collapsed and then expanded the Android 4.4 subsection. It should be good now. I have also added some sources. --Jimv1983 (talk) 02:51, 6 December 2013 (UTC)
- Hello there, and you're welcome. :) It's looking good now, with the inline references backing new 4.4.1 content. I've touched it up a bit, please check it out. — Dsimic (talk) 03:12, 6 December 2013 (UTC)
Google Experience Launcher
Take a look at this. Cheers. --uKER (talk) 14:33, 6 December 2013 (UTC)
- Thanks for a heads-up! I'm already looking at it. :) — Dsimic (talk) 14:35, 6 December 2013 (UTC)
Thanks
Thank you for this; I hadn't noticed so thanks for updating it. In addition, while I'm sure it was implied via my use of the "thanks" feature, thanks for all your work on the Nexus 5 article. :) Best. Acalamari 23:52, 7 December 2013 (UTC)
- You're welcome. :) Exactly, I went to see who thanked me for my edits on the Nexus 5 article, and spotted an outdated external link. :)
- While we're there, would it be possible to provide better integration of various external tools into Wikipedia? Or is it all up to the actual Wikimedia software? Some of the tools (for example, page views stats) are confusing and burried so deeply, that I doubt many people are actually using them — while their value and actual usability is undoubtful. Any insights, please? — Dsimic (talk) 00:03, 8 December 2013 (UTC)
- Hmm...I actually have no idea what processes are used to integrate the external tools! I'd recommend asking Cyberpower678 about this; from my experience, he's fairly knowledgable about technical matters such as this one. Acalamari 09:36, 8 December 2013 (UTC)
- In order to integrate them, the devs of this site need to get off of their butts and start doing something. :D. Actually, these tools are used a lot. I recorded that Page History Statistics tool was used over 88,000 times last month. That's quite a lot.—cyberpower OnlineMerry Christmas 12:37, 8 December 2013 (UTC)
- Thank you both for the insights! Ah, as always, elbow grease is required for new features and improvements. :) — Dsimic (talk) 15:10, 8 December 2013 (UTC)
Improved quotation style in article on BLAST protocool
Yes, Dsimic, it does look better! Synchronist (talk) 02:34, 13 December 2013 (UTC)
- I'm glad you like it. :) — Dsimic (talk) 02:38, 13 December 2013 (UTC)
Speedy deletion nomination of Laravel (Framework)

If this is the first article that you have created, you may want to read the guide to writing your first article.
You may want to consider using the Article Wizard to help you create articles.
A tag has been placed on Laravel (Framework) requesting that it be speedily deleted from Wikipedia. This has been done under section G12 of the criteria for speedy deletion, because the article or image appears to be a clear copyright infringement. This article or image appears to be a direct copy from https://teamtreehouse.com/forum/php-frameworks-2. For legal reasons, we cannot accept copyrighted text or images borrowed from other web sites or printed material, and as a consequence, your addition will most likely be deleted. You may use external websites as a source of information, but not as a source of sentences. This part is crucial: say it in your own words. Wikipedia takes copyright violations very seriously and persistent violators will be blocked from editing.
If the external website or image belongs to you, and you want to allow Wikipedia to use the text or image — which means allowing other people to modify it — then you must verify that externally by one of the processes explained at Wikipedia:Donating copyrighted materials. If you are not the owner of the external website or image but have permission from that owner, see Wikipedia:Requesting copyright permission. You might want to look at Wikipedia's policies and guidelines for more details, or ask a question here.
If you think this page should not be deleted for this reason, you may contest the nomination by visiting the page and clicking the button labelled "Click here to contest this speedy deletion". This will give you the opportunity to explain why you believe the page should not be deleted. However, be aware that once a page is tagged for speedy deletion, it may be removed without delay. Please do not remove the speedy deletion tag from the page yourself, but do not hesitate to add information in line with Wikipedia's policies and guidelines. - MrX 20:35, 15 December 2013 (UTC)
- @MrX: Hm, what's going on? It wasn't me writing this article, I've just renamed it so the second word in its title isn't capitalized. — Dsimic (talk) 20:41, 15 December 2013 (UTC)
- Just as a note, quoted from the article's talk page:
- You created the redirect at the (almost) same time as I nominated the article for speedy deletion. You can ignore the notification. - MrX 20:48, 15 December 2013 (UTC)
- — Dsimic (talk) 20:56, 15 December 2013 (UTC)
- Just as a note, quoted from the article's talk page:
History nicely fixed :-) https://en.wikipedia.org/enwiki/w/index.php?title=Laravel_%28framework%29&action=history Ronhjones (Talk) 20:31, 18 December 2013 (UTC)
- Looking good, thank you very much! — Dsimic (talk) 20:48, 18 December 2013 (UTC)
FYI: FlexRAID at AfD
Didn't seem notable to me. Someone should look the promo contribs of Special:Contributions/Wikidevb (and other SPAs which wrote that FlexRAID piece) in other articles. Someone not using his real name (talk) 18:05, 20 December 2013 (UTC)
- Thank you for a heads-up! — Dsimic (talk) 18:29, 20 December 2013 (UTC)
@Dsimic: That section isn't about FlexRAID. An article on FlexRAID is being prepared separately. The section was about RAID over File System as a general RAID approach. Refer to prior discussion on the entry here. — Preceding unsigned comment added by Spectwiki (talk • contribs) 17:41, July 30, 2014 (UTC)
- Hello there! Well, Ok, it doesn't hurt to keep it if you insist. — Dsimic (talk | contribs) 05:19, 31 July 2014 (UTC)
Nexus 4 Modification Rejected - no reason given?
Dsimic hi, I don't normally edit articles so perhaps I've got the wrong end of the stick. The material in the Nexus 4 page was waffle at the very best and that is what I removed. Is it that I have not correctly followed a procedure (there seem to be a lot) or just that you don't agree, and as a prominent editor/contributor you therefor felt justified in removing my edit with no reasoning? Just so I know what I should do in future. I contribute financially to Wikipedia and hate to see it dumbed-down with junk text. Nick (ozy1ozy) Ozy1ozy (talk) 21:42, 21 December 2013 (UTC)
- Hello there, and sorry for my delayed response! I apologize for not providing an edit summary while reverting your edit, so please allow me to explain now... In a few words, your edit deleted majority of the article's content, without a clear link with the deleted content being "bloat-text or advertising adding no useful information", especially as that content already went through multiple rounds of reviewing, debating and consenting. Of course, Wikipedia has clear rules against advertising, WP:Spam etc,. and the whole content has been already verified against them numerous times. Basically, your edit was bordering with blanking as a form of WP:Vandalism, and in such cases it's acceptable to perform the reverting while providing no edit summaries.
- Hope it makes sense. If required, I'm more than happy to discuss it further! — Dsimic (talk) 22:37, 21 December 2013 (UTC)
Editing OpenStack page
Hi Dsimic,
I'm very interested in your decision to pull the list of notable people in the cloud computing industry that drive the globally significant OpenStack project? Wikipedia has no problems with low rate movies having lists of actors and such, so why should the cloud computing industry and it's currently most significant project OpenStack not be able to list the leaders of the project? it's a larger than usual "key people" list, but that's the way the governance model is structured, so it's justified to declare that. I will be putting more information up about the unique and innovative OpenStack governance model in the coming days.
Thanks DHOTOU — Preceding unsigned comment added by Drhopontopofus (talk • contribs) 11:51, 21 December 2013 (UTC)
- Hello there, and sorry for my delayed response! On second thought, and especially with your intention of adding more details about the OpenStack's governance model, that list makes more sense. Having such a long list isn't that useful per se, as there are hundreds (and probably even thousands) of other people also playing important roles in OpenStack's development, but if we add more details about the structure, inner workings etc., that list will become more useful... Looking forward to your edits!
- Also, just as a note, seeing the word "committee" is always bringing me a bitter taste. :) — Dsimic (talk) 22:14, 21 December 2013 (UTC)
- @Drhopontopofus: Any updates, please? :) — Dsimic (talk) 15:11, 2 January 2014 (UTC)
- Hi Dsimic, I have been a bit snowed this month. I'll get onto this as soon as I can. I'm going to enlist one of the docs guys to help me. — Preceding unsigned comment added by Drhopontopofus (talk • contribs) 04:30, 3 February 2014 (UTC)
- Just take your time, there's absolutely no hurry. :) — Dsimic (talk | contribs) 04:35, 3 February 2014 (UTC)
It has been a pleasure
Hey Dsimic, I've really enjoyed collaborating with you on Replicant (operating system). I think we have made some significant improvements. If you ever need help on a project in the future, I'll be glad to assist. --WikiTryHardDieHard (talk) 00:00, 3 January 2014 (UTC)
- Hello there! Thank you very much – I'm glad you enjoyed it, and I'd say that the pleasure was all mine. :) Sure thing, we've made clearly visible improvements, and that's probably going to make Replicant more understandable to a broader audience, while preserving the knowledge and facts for the future. In the end, that's the goal, if you agree. :)
- Speaking about bigger projects, there's one I've been putting aside for a long time. :) It's the Logical Volume Manager (Linux) article, which is currently a totally outdated mess. It's such an important part of Linux, and a quite confusing part to many people at the same time; thus, having a good article would have multiple benefits.
- Would you like us to go into that as a kind of joint venture? :) — Dsimic (talk) 00:38, 3 January 2014 (UTC)
- I'd be happy to help with the LVM article. --WikiTryHardDieHard (talk) 01:27, 3 January 2014 (UTC)
- Sounds great, thank you! I'll try to provide some kind of a "new layout proposal" for the LVM article in the next few days, and we can start from there, if you agree? — Dsimic (talk) 01:31, 3 January 2014 (UTC)
- That sounds like a plan. --WikiTryHardDieHard (talk) 02:01, 3 January 2014 (UTC)
- Sorry for the delay, I've been sidetracked... Hopefully I'll be able to present the "new layout proposal" in the next few days. — Dsimic (talk) 18:02, 9 January 2014 (UTC)
Talk before you revert
I believe you are in violation of Wiki consensus in your constant reversion without explanation. I carefully explained my reasons in the Talk section for reverting your original edit. You ignored the talk and went ahead and reverted or reinserted without responding, twice. Please see Wikipedia:BOLD, revert, discuss cycle. While this is not a policy, your continued reversion without discussion is close to an edit war. Tom94022 (talk) 00:46, 3 January 2014 (UTC)
- Hello there! Please, let's take it easy, there's no need for running too fast. I do agree that I should've provided feedback first, but I was at the end of writing my quite long reply on the Talk:Data corruption, when you reverted my two edits. While I totally agree (and stand corrected) that it wasn't the best behavior from my side, you should've also waited for my response before deleting my edits (and you just reverted it once again before talking first).
- However, let's move forward; I'll stop doing anything before we reach a consenus. Looking forward to discussing it further! — Dsimic (talk) 01:33, 3 January 2014 (UTC)
C algorithm for Damerau–Levenshtein distance
I've read your discussion and I understand your reason, on one hand you're right when you say that wikipedia is not a source code repository on the other when I googled Damerau–Levenshtein distance, I was interested into knowing what that was, its applications an so on but, on the other hand, I also needed to implement it in one of my programs, so it would have been very useful to have a runnable (and possibly well written) source code on hand rather than googling again and reinventing the wheel taking pieces of sources here and there (I built the algoritmh i published from various questions on Stack Overflow). So this is my proposal: I publish the source on one website like rosettacode.org or github and then I publish the link into the "External Link", section. I've just noticed that there is already a link to a C implementation on github that I skipped yesterday, but I've looked at it now and it seems way too complicated yto be useful (for example I don't understand why a function returning a distance between 2 char vectors never uses the char or char* datatype, I'm sure that a deeper reading will unveil all the mechanism that probably threats char vector as vector of unsigned integers and that in the end it will definitely work, but my implementation, taking simply the two char vector as an input seems to me much easier and clear)Alinoli (talk) 12:24, 3 January 2014 (UTC)
- Hello there! Totally agreed on your "External links" proposal, please go for it, and there should be no rules against such inclusions here on Wikipedia. It might be bordering with the WP:HOWTO rules forbidding HOWTO's as external links, but an algorithm implementation could hardly be treated as a HOWTO, and there's already a bunch of such external links in the Damerau–Levenshtein distance article.
- Regarding the already linked C implementation and no usage of
char, they do useunsigned intinstead (possibly for an extended alphabet), there's even a comment on top of the source file stating that: Note we use character ints, not chars. At the same, that implementation looks a bit inefficient, as they use a linked list for deduping and storing stuff, what involves linear searches every time. — Dsimic (talk) 16:25, 3 January 2014 (UTC)
- I also agree -- posting source code to some source code repository, and then editing the relevant Wikipedia article to add a link to that source code, is a great idea.
- I am unaware of any "rules forbidding HOWTO's as external links", although I often discover new rules I was previously unaware of.
- Please give me a link to any Wikipedia policy, guideline, or essay that includes any such rule. Thank you. --DavidCary (talk) 16:50, 4 January 2014 (UTC)
- Hm, unfortunately I seem to be unable to find that policy again; the best I can come up with at the moment are WP:LINKSTOAVOID (which doesn't explicitly forbid HOWTOs as external links), and WP:NOTHOWTO (which says that content of articles isn't to be in form of a HOWTO). Maybe I just got it wrong back at the time?
- Ah, I know how confusing all those rules, guidelines and policies can be sometimes... There are even a few studies stating that Wikipedia is pretty much no longer growing in terms of getting a lot of quality new content, as not everyone wants to learn all those dozens of rules scattered all around. — Dsimic (talk) 17:21, 4 January 2014 (UTC)
Android 4.4 image revert
Hi, I thought from the https://en.wikipedia.org/wiki/Talk:Android_version_history#AOSP_vs_Android talk that one should not make any distictions between Android/AOSP, thus not distinguish between open and closed sourced software. Threrefore, Android as the end used know it is what is provided by Google, thus making screenshots of the GEL appropriate to represent the Android home screen. Looking at Android.com, images of the GEL is displayed. — Preceding unsigned comment added by Pandabear123 (talk • contribs) 21:47, 4 January 2014 (UTC)
- Hello there! This thread on the Talk:Android version history talk page hasn't received any feedback yet, though I partially agree with the proposal itself. Though, there was another discussion before (scattered around), concluding that we shouldn't be including screenshots of the Google Home (also known as Google Experience Launcher), as that's basically a closed-source application which can be running on any version of Android, not only on the "AOSP-like" variants. On the other hand, not providing those Google Home screenshots probably brings in a lot of confusion, as the readers are actually expecting to see them.
- In a few words, that's still an open question, and I'd suggest we try first to gain some more attention on the talk page; I'll post a comment there shortly. In my opinion, the solution might also be to include two screenshots ("AOSP" and Google Home), but I'm unsure whether that would actually be a good solution. — Dsimic (talk) 22:07, 4 January 2014 (UTC)
Delay in responding about Data Corruption
Hi Dsimic: I've been down with a bad cold since Jan 2 so haven't responded, but will in the next day or so. Thanks for being patient. You can delete this after u read it. Tom94022 (talk) 21:56, 6 January 2014 (UTC)
- Hello there! No worries, thank you for the notice, and there's no hurry... I hope you're feeling better now? Looking forward to making Data corruption article better! :) — Dsimic (talk) 22:18, 6 January 2014 (UTC)
Concerning your revision on the Android kernel
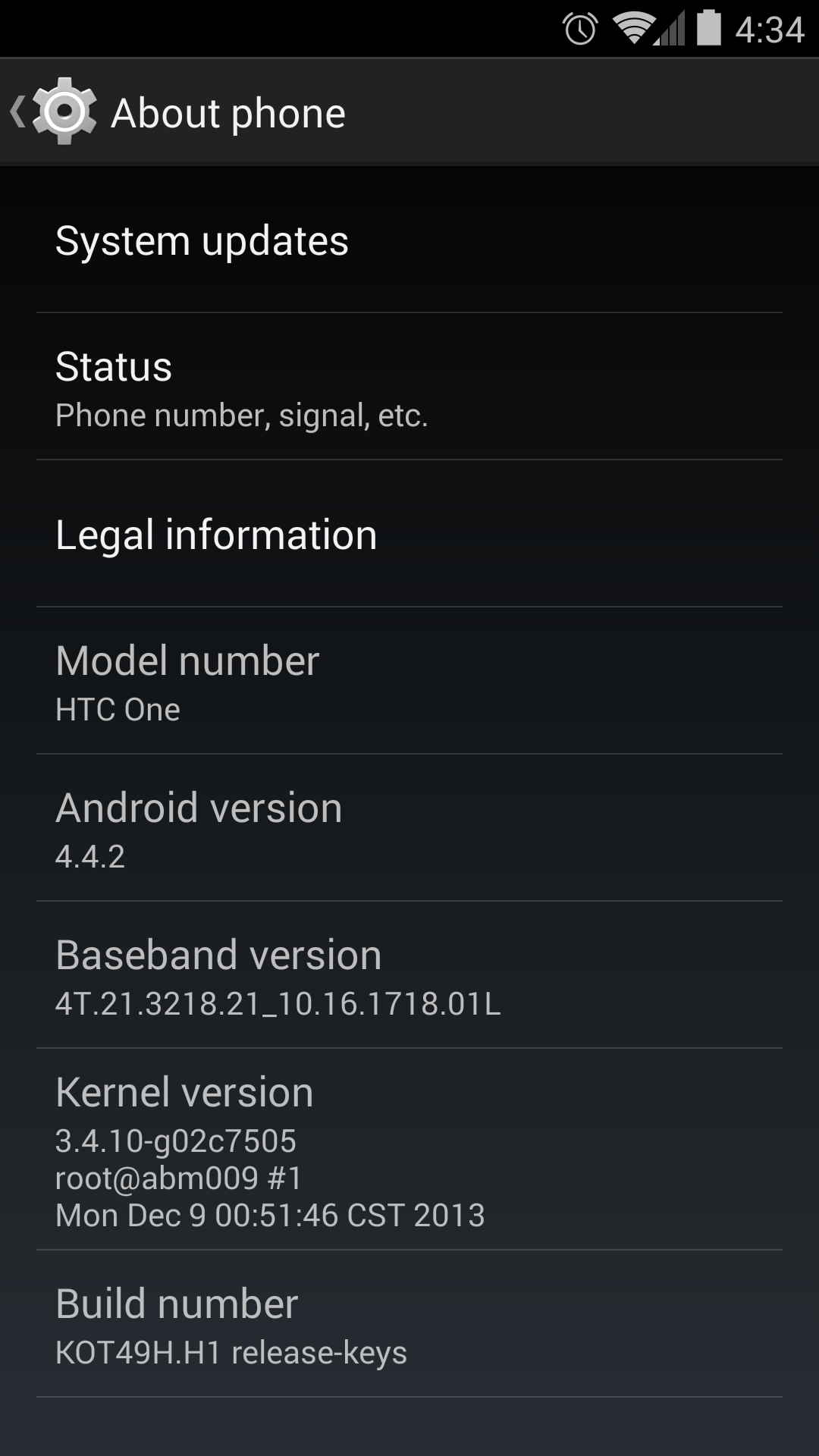
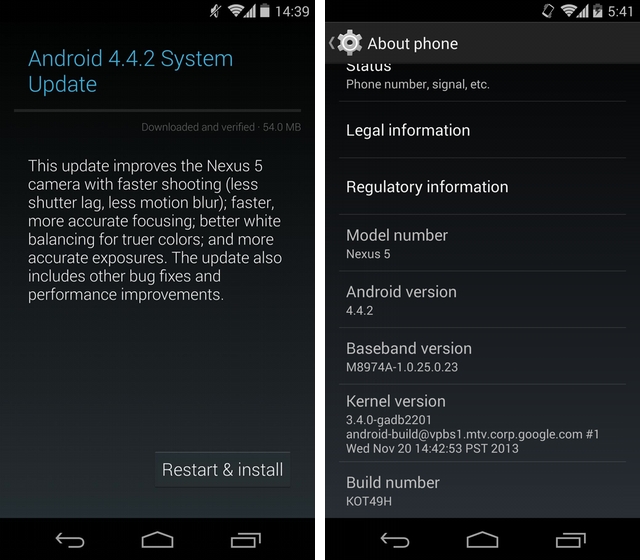
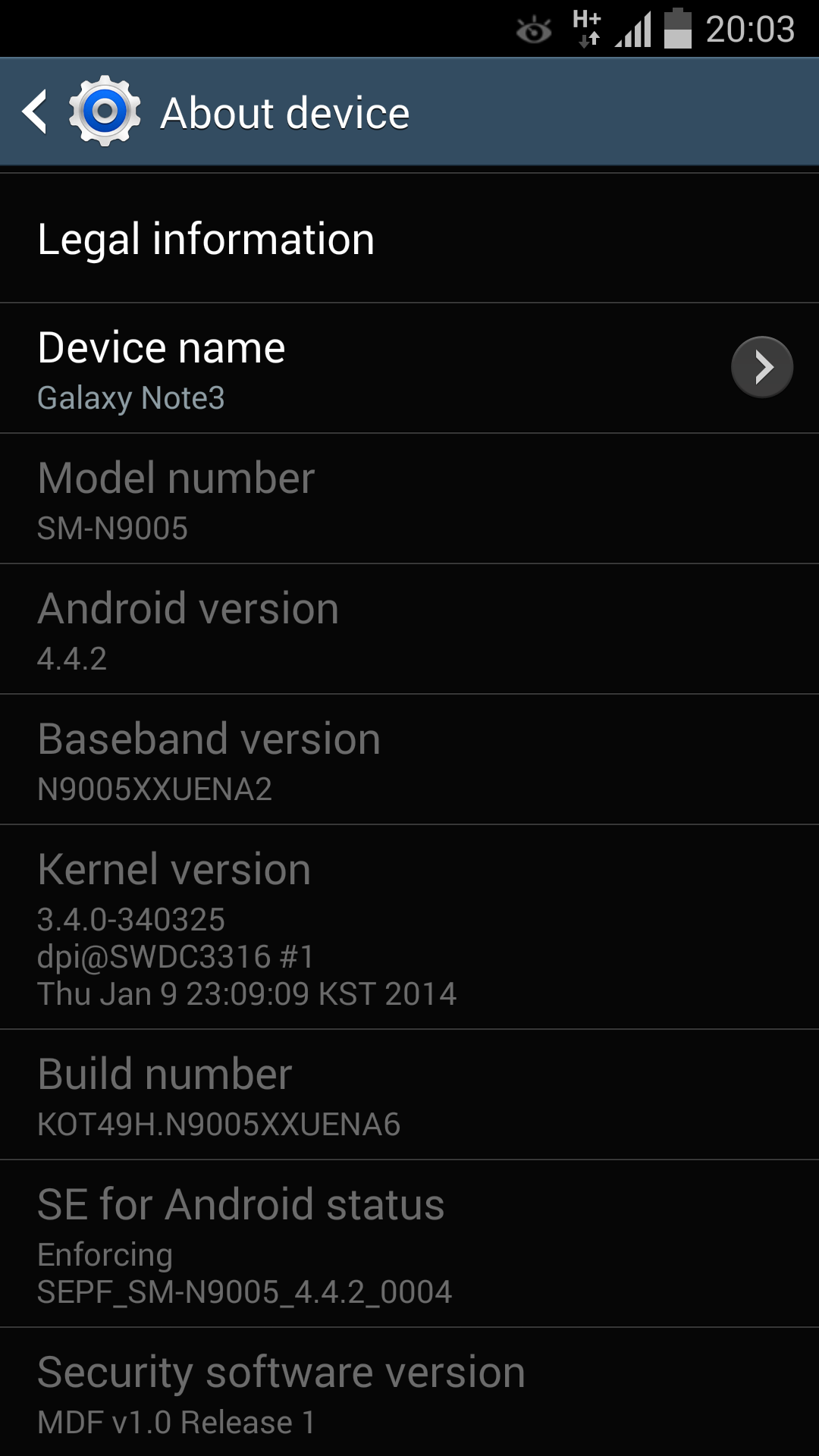
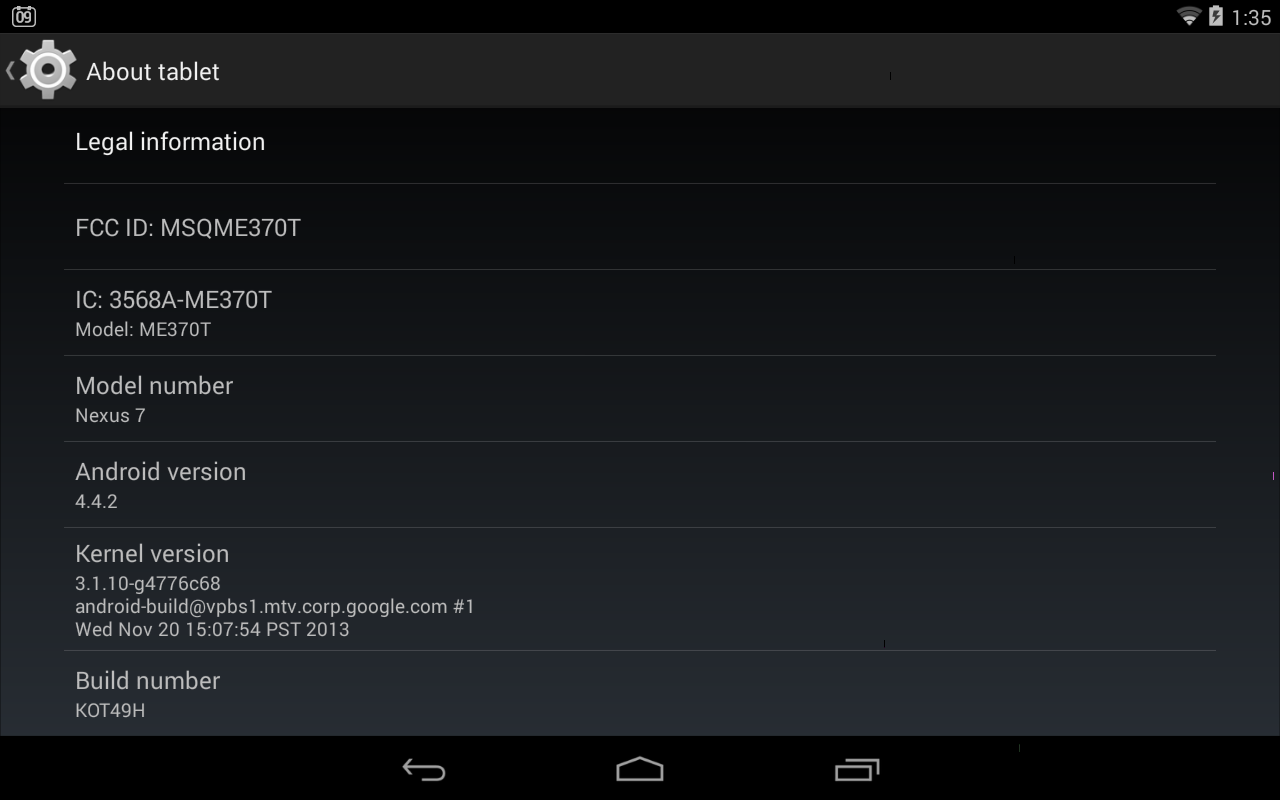
Android can technically be built upon any Linux kernel and was never limited to 3.4.10. In fact that version with the citation in the article is wrong. It's the kernel version for the HTC One ONLY. The Nexus 5 for instance uses 3.4.0. The Snap 800 note 3 also uses 3.4.0 with a slightly different revision. Older kernel versions are also used on KitKat, the second Nexus 7 has 3.1.10.
Some devices are able to use kernel 3.12 with proper sources. Even my i9001 runs 3.4.77. There is simply no standard/generic kernel version for Android, it all depends on the SoC, device and sources.
Sources:
- http://cdn.androidpolice.com/wp-content/uploads/2013/12/nexusae0_one_kot49h.png
- http://mobilesyrup.com/wp-content/uploads/2013/12/android442nexus5.jpg
- http://www.sammobile.com/wp-content/uploads/2014/01/Screenshot_2014-01-12-20-03-13.png
- http://www.droid-life.com/wp-content/uploads/2013/12/Screenshot_2013-12-09-13-35-43.png
- http://forum.xda-developers.com/showthread.php?t=1617219
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Yowanvista (talk) 11:45, 19 January 2014 (UTC)
- Hello there! Sorry if my edits sounded like me being lazy or something similar, it was only about the need for providing references while changing articles in such ways. I knew things were the way you edited the Android article, but Wikipedia is an encyclopedia where everything is about verifiability of the provided content.
- Sure thing that Linux kernel versions are depending on the actual device, and pretty much any (recent) kernel version could be made to fit – it's all about what each manufacturer sticks with, and whether it wants to invest more time (and money) into porting whatever in-house kernel changes they've made, onto a newer version. Remember those infamous (from the security standpoint) changes Samsung had done to the Linux kernel, in order to support cameras on some of its cellphones? Not to mention the main differences introduced by Android's "fork" of the Linux kernel. As we know, once manufacturers do the required "hacks" just to make a device work with a specific Linux kernel version, they're reluctant to invest more resources into further upgrades, as all those different versions seem to be the same ish to their upper-level management. :)
- — Dsimic (talk) 02:15, 20 January 2014 (UTC)
Replicant
What does the non-breaking space do? --WikiTryHardDieHard (talk) 02:08, 25 January 2014 (UTC)
- In this case, improves the way content of table cells is wrapped, by keeping together compounds that include a space. In case you'd like to see more details about the inner workings, {{nbsp}} is a good starting point. — Dsimic (talk) 02:15, 25 January 2014 (UTC)
- Interesting --WikiTryHardDieHard (talk) 02:39, 25 January 2014 (UTC)
- Right, and it all comes from the standard
HTML element. — Dsimic (talk) 02:43, 25 January 2014 (UTC)
- Right, and it all comes from the standard
Ooops sorry I don't know what happened, your link work, but when I did the change my browser (firefox) was jumping to the bottom of the page. --Dadu (talk) 09:44, 29 January 2014 (UTC)
- Hello there! No worries; you're right about the redirects to anchors not working properly sometimes, regarding the vertical scrolling of pages upon such redirects. I've seen that myself too on various redirects to the Android version history article, as well as on some other articles.
- As far as I can tell, that's up to the anchors positioning being performed by using JavaScript code, not through plain anchors in URLs – and probably something becomes messed up with the vertical positioning because of those collapsed sections in the Android version history article. I'm not a JavaScript expert, but that could be debugged quite quickly using Firebug by placing a few breakpoints into the JavaScript code and tracing what's happening there. Maybe it would be good to post a MediaWiki bug report?
- Also, please have a look at the discussion provided within the section which is now linked as see also above – in its second half, that discussion provides a further insight into the inner workings of MediaWiki redirects. — Dsimic (talk | contribs) 00:42, 30 January 2014 (UTC)
About sue from Nikon
Nikon sue only for the style, but IMO Nikon worry about Android OS, Nikon worry if something happen as mobile phone and mainly smartphone made compact camera sold only 40 percent than 2 years before, while 2013 DSLR sold is also declining. Thank you.Gsarwa (talk) 04:29, 2 February 2014 (UTC)
- Hello there! That sounds as a good possible further addition to the Android (operating system) article; are there any references providing such a description of the lawsuit? If there are such sources, Android (operating system) § Cameras section could be expanded further. — Dsimic (talk | contribs) 04:40, 2 February 2014 (UTC)
Help request
If you are looking for a new article to edit, I just created Ark OS. It's pretty minimal right now, and could seriously benefit from that magic Dsimic touch. --WikiTryHardDieHard (talk) 00:38, 4 February 2014 (UTC)
- Thanks for noticing, I'll have a look. By the way, I'm not a magician (wished I was one), but just a guy spending too much time at his computer screens. :) Also, regarding the previously mentioned Logical Volume Manager (Linux) article, that's somewhat on ice for now, but we'll get to its rewrite eventually. — Dsimic (talk | contribs) 00:45, 4 February 2014 (UTC)
Column formatting
I've noticed you're setting up column formatting for References and See also in numerous articles. This is all well and good. Would you mind marking these edits as minor to keep our watchlists reasonable? Thanks. ~KvnG 14:21, 5 February 2014 (UTC)
- Hello there! Thanks for noticing on that, I've been thinking more than a few times whether such edits should be marked as minor or not; guess my dilemma is now resolved. :) Though, on my watchlist (currently 1,100 articles) I'm reviewing minor edits as well. — Dsimic (talk | contribs) 14:27, 5 February 2014 (UTC)
Matrix at feature hashing
Re: your edit, what was shown instead of the matrix? I have MathJax turned on because it's more reliable and produces better-looking output, so I hadn't seen the problem. Sometimes, saving without changes can force the LaTeX output to be regenerated. QVVERTYVS (hm?) 20:50, 6 February 2014 (UTC)
- Hello there! Instead of the expected matrix, this message was displayed in red (of course, you can log off Wikipedia and look at the revision in order to verify it):
- Failed to parse(PNG conversion failed; check for correct installation of latex and dvipng (or dvips + gs + convert)): \begin{bmatrix} 1 & 2 & 1 & 1 & 2 & 0 & 0 & 0 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 1 & 1 & 1 & 1 & 0 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \end{bmatrix}
- Tried a few things, including reducing the number of columns, and for some reason everything over 8–9 columns (or so) seems to result in this error. I really have no idea why – that's not a huge number of columns? — Dsimic (talk | contribs) 21:07, 6 February 2014 (UTC)
Your revert of Ethernet
It's not a matter of better language but of verifiability. "A frame begins with preamble and start frame delimiter, ..." implies that preamble and SFD are part of the frame which they are not.
Your source, clause 35.2.3.2 "The preamble <preamble> begins a frame transmission. [...] The SFD (Start Frame Delimiter) <sfd> indicates the start of a frame ..." is ambiguous – it doesn't really tell where these sequences belong to. Please take a look at the more basic clauses 3.1.1 and 3.2 which very clearly show and state that preamble and SFD are not part of the frame but the (largely neglected) packet: "A MAC frame starts immediately after the SFD." (3.2.2).
With respect to your preferences I'll change the phrase to "a frame begins after the preamble and SFD". Zac67 (talk) 18:45, 7 February 2014 (UTC)
- Hello there! Thank you very much for pointing out sections 3.1.1 and 3.2 (from the 802.3-2012_SECTION1.pdf file), where the relation between Etherner frames and packets is clearly stated. Also, current language is looking good to me; went ahead and added a reference, followed by a small language cleanup. — Dsimic (talk | contribs) 04:28, 8 February 2014 (UTC)
- Great – I keep finding the same problem here and there, but we can surely weed that out. Zac67 (talk) 10:33, 9 February 2014 (UTC)
- Sure thing; I've seen your further edits correcting that in the Ethernet frame article, and I've improved and corrected the Start frame delimiter article so it clearly states the difference between Ethernet frames and Ethernet packets. — Dsimic (talk | contribs) 20:50, 9 February 2014 (UTC)
Debian timeline
Sorry to bother you. I've spent over an hour trying to find the origin of {{Timeline Debian GNU/Linux}} as used in the main Debian Wikipedia article. It's out of date (and I think about to become more so), but I can't find the "source" with which to fix it. I see you take an interest in that Debian article, and are probably more skilled than I am on Wiki-matters, so I hope you can point me to the relevant editing page. Larry Doolittle (talk) 20:35, 8 February 2014 (UTC)
- Hello there! You're not bothering, we're all here to help each other. :)
- That chart is a template, and it can be edited just as any other Wikipedia template or page. Just click on the above template link (which I've created in this edit), and you'll go to the template page where it can be edited as usual. I know it's quite confusing to get to those templates (and not documented AFAIK) – that's where the
{{t|Template_name}}tag comes handy. Also, you can manually create and open a direct URL in form of https://en.wikipedia.org/wiki/Template:template_name. - Hope it helps. — Dsimic (talk | contribs) 21:07, 8 February 2014 (UTC)
- That helps tremendously! I've already edited that template to include the 7.3 update. Thanks so much! Larry Doolittle (talk) 21:36, 8 February 2014 (UTC)
- You're welcome. :) — Dsimic (talk | contribs) 21:39, 8 February 2014 (UTC)
Template:Android tablets
It doesn't look like ThinkPad Tablet 2 is Android? Frietjes (talk) 23:47, 13 February 2014 (UTC)
- You're totally right, it was simply my brainfart to get it included there, sorry. Thank you for catching it so quickly!
- The same applies to ThinkPad 8, and I've already corrected that, while adding it into the {{Windows tablets}} template. — Dsimic (talk | contribs) 00:13, 14 February 2014 (UTC)
Redirect template formatting
Regarding your "cleanup" of my edit on Intel HD Graphics, I was following the format mentioned to me by Paine Ellsworth (talk · contribs), who told me that {{redr}} should be used even if only one category is desired and that a line break should be put between the template and the redirect itself. Is there evidence that this is no longer the consensus? (I see now that WP:REDCAT mentions the line break but not {{redr}}; I'm not sure how regularly that guideline is being updated though.) --SoledadKabocha (talk) 05:45, 17 February 2014 (UTC)
- Hello there! Regarding my edit, the main intention was to have this redirect page using the
{{R ...}}categorization syntax; basically, {{redr}} template is (still) just a proposal for a redirects unification and not officially suggested to be used, as visible from its documentation and WP:REDCAT. If {{redr}} template had become the offical way for tagging redirects, there would be bots automatically editing redirect pages thus making it used all around. - Regarding putting everything into the same line, it's somewhat common to do that if there's only one
{{R ...}}tag – I've seen hundreds of such redirects (and zero redirects using {{redr}} template, by the way). I'm not saying that merging it into the same line is by the book, but it makes such "one-R" redirects a bit more readable, I'd guess, so editors tend not to put single "R-tags" into separate lines. IIRC, I've even seen a few bots placing these tags into the same line, while fixing double redirects etc. — Dsimic (talk | contribs) 06:08, 17 February 2014 (UTC)
- Since my name was mentioned, I suppose my "2 cents" is welcome here? Since there is no set rule on whether to use the {{This is a redirect}} (Redr) template or place Rcats on redirects individually, and since both ways accomplish the same thing in terms of categorization, then there is no reason why either method cannot be used. Most of the redirects I come across, whether or not they already have an Rcat or two, usually need at least one more Rcat, so I use the Redr template to tag redirects with up to six Rcats in one template. I suppose I may be a little biased since I've put so many hours in improving the Redr, but I favor the way it presents text over just to add the Rcats individually. I recently enabled the Redr template to take Rcat parameters as I explained in the documentation and am still looking for ways to improve it. I also made a comparison page so editors can see the difference. This has become more important now that the two bugs were fixed and text appears on redirects. I wish I could judge you and say its wrong to convert from the Redr template to individual usage, but I convert in the other direction whenever I get the chance, so I cannot be one to judge. At this point it is a matter of contributor preference, and even though I consider the Redr usage as a major advancement over individual usage, others' opinions may differ. Joys! – Paine Ellsworth CLIMAX! 14:49, 17 February 2014 (UTC)
- Of course you're welcome – the whole Wikipedia was built by many two-cent contributions. :) As always, it's good to have multiple ways and different options for doing the same thing; the only bit unclear to me is that the official redirects categorization manual nowhere mentions usage of the {{redr}} template? Why is it so? Did it go through an extensive voting procedure to go out of the proposal state? Also, while looking at the usage and results differences, {{redr}} template produces somewhat "too blingy" messages on the redirect pages, when compared to the messages produced by
{{R ...}}tags – though, that's only my opinion. — Dsimic (talk | contribs) 00:07, 18 February 2014 (UTC)
- Of course you're welcome – the whole Wikipedia was built by many two-cent contributions. :) As always, it's good to have multiple ways and different options for doing the same thing; the only bit unclear to me is that the official redirects categorization manual nowhere mentions usage of the {{redr}} template? Why is it so? Did it go through an extensive voting procedure to go out of the proposal state? Also, while looking at the usage and results differences, {{redr}} template produces somewhat "too blingy" messages on the redirect pages, when compared to the messages produced by
- If "blingy" means "gaudy", "flashy", etc., then perhaps it can be toned down, although it would be nice for you to explain exactly what you mean. For nearly all of the Rcats, the messages are the same whether the Rcat is deployed individually or within the Redr template. So if the messages are too blingy, then they are so no matter which method is used. The reason I have not added Redr to REDCAT is because up until very recently Redr had some limitations that needed to be improved, plus the fact that only last month the bugs were fixed and text was then allowed on redirects. If you'll check the oldest bug, Template:Bug, you'll see how long it's been in the fixing, and little "warning" was given that it was about to be fixed, so until now there hasn't been any big hurry to improve Redr. As we speak I have almost completed the addition of another parameter that will fully enable {{R from alternative language}}'s parameters in Redr. A few more tests to make sure the expected performance is up to snuff, and I will deploy the new parameter. Then Redr's limitations will be few and far between. Keep in mind that I and others have been using Redr to tag and sort redirects for nearly six years, so even without its recent improvements, its utility has been excellent for all but a few applications. If it's blinginess from your perspective turns out to be in its usage of color, then if you like, we could try a different type of Mbox to get a less blingy color scheme? The "type" parameter choices can be found at Template:Mbox#Parameters if you would like to experiment with how the different types appear. Joys! – Paine Ellsworth CLIMAX! 02:02, 18 February 2014 (UTC)
- Thank you very much for a detailed insight! That longstanding bug #14323 is quite a good example of how much persistence is often required to make something happen. With all that effort going into the {{redr}} template, I'd say you should go ahead and include it into the WP:REDCAT once you feel it's ready.
- Regarding the "bling factor", I'm not sure how important are my own aesthetics assessments, :) however I went and compared again two variants of the Intel HD Graphics redirect page – "R-tag" and "redr template"... On second thought, and after spending some time erasing the mental imprint of the
{{R ...}}tags, I'd say that adding a1emtop padding to the message box would make a world of difference, as right now it sits too close to the redirect description. It's somewhat "blingy" when compared to the R-tag's output, but it's quite nice once that old imprint is gone – but still, that padding would put a cherry on top. — Dsimic (talk | contribs) 03:00, 18 February 2014 (UTC)
Is there any conclusion I should draw from this discussion yet? (Paine Ellsworth, sorry for relying on WP:Notifications rather than notifying you manually.)
Is it worth formally proposing that {{redr}} is to be used iff multiple categories are desired? What syntax will be used for "{{R from alternative language}}'s parameters in Redr"? --SoledadKabocha (talk) 18:25, 18 February 2014 (UTC)
- Hehe, iff, thumbs up! In my opinion, it is worth proposing the {{redr}} template for official inclusion into the WP:REDCAT manual, once the last bits are ironed out; to me, its use shouldn't be limited to multiple categories only. Of course, all that only if Paine Ellsworth agrees. — Dsimic (talk | contribs) 22:01, 18 February 2014 (UTC)
- It's all good, SoledadKabocha. It's probably "high time" to add Redr to REDCAT, and I agree with Dsimic that Redr should not be limited to multiple Rcats. While I haven't yet come across a redirect that couldn't be sorted into at least one category, Redr is designed to tag redirects that don't need an Rcat into Category:Miscellaneous redirects. That cat now has 22 inhabitants, and while I haven't scrutinized them yet, I would bet I could put at least one Rcat on all or most of them. The sandbox version is ready to be deployed with the "to" parameter for {{Ralterlang}}, and I wonder if both of you would mind having a look? Not too sure yet about the minor addition of the small text at the bottom, which notifies that it is the This is a redirect template. Too blingy, maybe? Also, I have placed a non-breaking space at the top of the sandbox code that may accomplish what you, Dsimic, have suggested? It's elegance is a bit wanting; however, this may be better than spacing the top of the Mbox that probably has applications for which a top space would not be appropriate. Please do not pull any punches, as my main concern is to improve Redr. Joys! – Paine Ellsworth CLIMAX! 07:27, 19 February 2014 (UTC)
- PS. There is a ready comparison of live vs. sandbox at Template:This is a redirect/testcases. PS added by – Paine Ellsworth CLIMAX!
- I had a look at the sandbox version, and—quite frankly—the addition of "This is the {{This is a redirect}} template." at the bottom doesn't look good to me. I've never seen something like that on any of the Wikipedia's templates, and such kind of an "advertisement" (or a usage hint) shouldn't be there, as it's perfectly normal to have a look at the source code; if someone cares about it, the source code is already there, otherwise no ads would do any good. :)
- Regarding the top spacing, it might be better to use a surrounding table or
<div>element with the required CSS definition, as those might play better with the rest of the page elements, when compared to placing a more simple<br />. Also, including a simple<br />actually creates a surrounding<p>element containing that<br />in the rendered HTML code, what results in a vertical spacing much larger than the desired1emspacing. Of course, no modifications should go to the already existing templates, everything goes into the {{Redr}}'s composition of them. - Just my $0.02. :) — Dsimic (talk | contribs) 01:38, 20 February 2014 (UTC)
- Just as an example, here's a table bringing the desired
1emtop spacing, as described above:- {| style="width: 100%; padding-top: 1em;"
- |-
- | {{Redr}}
- |}
- Sorry if I'm overexplaining. :) — Dsimic (talk | contribs) 01:48, 20 February 2014 (UTC)
- Just as an example, here's a table bringing the desired
Didn't mean to
Undo you here. I just thought I accidentally inserted two blank lines. Beware that there has been some unholy MOS war about this issue, i.e. how many lines are allowed in the footer. (General pointer [1]) Someone not using his real name (talk) 20:25, 18 February 2014 (UTC)
- No worries, it's just a newline character, nothing more. :) Interestingly, WP:STUB states that "it is usually desirable to leave two blank lines between the first stub template and whatever precedes it." Based on that manual entry, there actually should be two blank lines, leaving more vertical space before the stub template? — Dsimic (talk | contribs) 22:28, 18 February 2014 (UTC)
Red links
Please do not remove red links, as you did at Metadata - they're a deliberate feature of Wikipedia; see WP:REDLINK. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 21:57, 19 February 2014 (UTC)
- Hello there! Yeah, I've read about the redlinks a long time ago, and they used to be much more recommended back at the time when the Wikipedia's coverage was much more narrow. Also, according to the manual, it actually isn't recommended to create redlinks for people's names – "red links to personal names should be avoided". Anyway, I'm fine with leaving the Metadata's redlink as-is. — Dsimic (talk | contribs) 22:06, 19 February 2014 (UTC)
App Ops
On reflection I think this comment was unnecessarily harsh and I'm sorry for it. – Steel 22:50, 20 February 2014 (UTC)
- No worries! I'm always open to other people pointing out my deficiencies, bugs in code, areas for improvement etc. In my opinion, that's the only way to learn and improve yourself; taking a primrose path is much more convenient, but isn't good at all. :) — Dsimic (talk | contribs) 23:02, 20 February 2014 (UTC)
A barnstar for you!
|
|
The Original Barnstar |
| For your distinction between Android RAM requirements and recommendations. read (talk) 23:03, 26 February 2014 (UTC) |
- Thank you very much, read! Though, I'm not sure that I deserve the credit – I've just cleaned up and propagated further the edit on Android version history article, which was originally submitted by XSpidey01x. — Dsimic (talk | contribs) 00:00, 27 February 2014 (UTC)
I removed categories because the article already was part of subcategories of them, for example, all Capacitive touchscreen mobile phones are automatically "also" Touchscreen mobile phones, and as a consequence automatically "also" Mobile phones. At least at Commons, where I'm more familiar with categorising, this would be a clear case of overcategorisation. |FDMS 17:18, 27 February 2014 (UTC)
- Hello there! You're right, I stand corrected; Category:Capacitive touchscreen mobile phones is covering all deleted categories. Went ahead and re-introduced your changes to the categories in Nokia X article, and cleaned them up even further – please check it out. — Dsimic (talk | contribs) 17:33, 27 February 2014 (UTC)
I overhauled the PCI express pinout chart
I'm curious what you think. If you want to revert it all, or make massive edits, that's okay. I just figured it wasn't so dubious I had to do it in a talk page; I figured I'd WP:BB and do the edit process live. 71.41.210.146 (talk) 23:40, 28 February 2014 (UTC)
- Hello there! You did a good job with layout compaction, but to me it seems like something that might be confusing to the readers, especially as we have different types of cards ending at various pin positions. Also, it looks even more confusing when viewed on small screens... Trust me, I love compact layouts, so reverting it was really difficult to me – it hurts me to see so much work going down the drain. :( Anyway, I'm still thinking about how to make the layout more compact; any suggestions, please? — Dsimic (talk | contribs) 18:06, 1 March 2014 (UTC)
- I was thinking about how to make it more compact while not introducing any potential confusion, and came to nothing that would be an acceptable solution. Having all that in mind, I've just reverted my revert, restoring your initial compacted version. If anyone becomes confused by it, well, that's not our fault. :) — Dsimic (talk | contribs) 00:45, 3 March 2014 (UTC)
- Well, thanks for the fedback. Actually, it could easily be compacted further, as the comments describing the differential pairs have very little information content and can be easily compressed. What window size are you using? Using a 640x480 pixel window, the main problem I see is that the line-wrapping of the legend thickens some rows at the bottom of the table.
- I think a bit of prose explaining that the power and low-speed signals all come before the key notch, while high-speed signals all come after in a variable-width section could be combined with long explanations for the before-the-notch pins and terse ones for after.
- Can you explain the issues you'd like addressed? 71.41.210.146 (talk) 07:08, 3 March 2014 (UTC)
- You're welcome, and thank you for your feedback! Actually, I see no big issues with various browser window sizes (to me, rows thickening you've described isn't a big deal), while the only "itchy" thing is to somehow "connect" two "columns", making it clear that a ×16 card is what takes up pins listed in the second column. That's, in my opinion, the only thing possibly causing confusion – otherwise, the new layout is as good as it gets for so many pins to be listed. — Dsimic (talk | contribs) 07:25, 3 March 2014 (UTC)
Emulator
Hi, cool guy
I could come up with several reasons to perform this deletion but I chose one that covers them all. In case I wasn't clear enough, here is my concerns: You see, the text is unreferenced, has no context and is very technical, so much so that only interests a minority. So, I supplied manual as the reason because manual is the place where you read unreferenced technical stuff like this. (If you'd have to add a source for them, your source would be most likely a manual.)
When I removed them, I thought chances are that they are listed in one of the sources in close proximity, so no one misses anything. But if nothing else, let's at least solve the invalid HTML problem. It's ordered list item -> definition list -> definition item, which is not good. The same list can be written in prose form.
Best regards,
Codename Lisa (talk) 01:32, 2 March 2014 (UTC)
- Hey, how are you? :) Please, let me check first whether those instructions are contained in one of the already existing references, and I'll come back with an update. My main reason for reverting your edit was that such information might be helpful and usable to some readers, so preserving it might be better than deleting. — Dsimic (talk | contribs) 01:40, 2 March 2014 (UTC)
- Sorry for the delay. I've checked the surrounding references, and now I agree that the note is pretty much an overkill, representing a marginal information already contained in the reference #22 (starting on page 65) for those who need such specific stuff. Went ahead and reverted my earlier revert. — Dsimic (talk | contribs) 06:40, 4 March 2014 (UTC)
- Thanks. Always a pleasure working with you. Best regards, Codename Lisa (talk) 04:39, 5 March 2014 (UTC)
Please undo yourself...
Well, I thought my edit summary was quite clear that I was about to do another undo (which I can't do now due to the edit conflict and overlapping edit region). Can you revert yourself so I may show you without me having to undo again? Widefox; talk 22:37, 2 March 2014 (UTC)
- Ok, there you go, though that doesn't make much sense, honestly. While here, you could've also explained what are you actually intending to achieve, if you agree – maybe we could discuss the whole thing in order to find the best option, for example. — Dsimic (talk | contribs) 22:45, 2 March 2014 (UTC)
- You had to revert something in order to perform this edit? Please tell me you're kidding. :) — Dsimic (talk | contribs) 23:01, 2 March 2014 (UTC)
- Thanks! Eventually
 Done If my edit summaries weren't clear please say. If they were clear to you, best not to undo when someone else is mid-undo! All yours now. Widefox; talk 23:30, 2 March 2014 (UTC)
Done If my edit summaries weren't clear please say. If they were clear to you, best not to undo when someone else is mid-undo! All yours now. Widefox; talk 23:30, 2 March 2014 (UTC)
- Thanks! Eventually
- You're welcome! I see what you wanted to achieve and that was just fine, but the revert was somewhat confusing. Anyway, it's all good now. :) — Dsimic (talk | contribs) 23:36, 2 March 2014 (UTC)
A beer for you!

|
Thanks for the kind words. Someone not using his real name (talk) 23:41, 3 March 2014 (UTC) |
- Thank you, and you're welcome! Hopefully, this advice (if I may call it so) might be helpful. — Dsimic (talk | contribs) 00:12, 4 March 2014 (UTC)
Dear Dragan
Dear Dragan: I am injecting myself into the dialogue regarding artificial intelligence (see the newly created User:Synchronist), and I am counting on you to be my Virgil! User:Qwertyus also alerted! Synchronist (talk) 05:21, 9 March 2014 (UTC)
- Wow, your life and work sounds quite amazing! As someone born in one of not so shiny parts of the world (but striving toward the escape), I'm always amazed seeing anyone doing things out of ordinary, and making for a living the same way – heck, even by working as a kinetic sculptor. :) Please feel free to call me crazy, but to me, that's quite amazing.
- At the same time, I guess Wikipedia isn't that much of Hell and Purgatory? :) — Dsimic (talk | contribs) 06:51, 9 March 2014 (UTC)
- Don't kid yourself -- like 99% of all other artists, I have a day job, and not a very glamorous one at that, since I am trying to preserve my mental energy for my art -- and for my participation in this here noosphere. P.S. Thanks for the indents -- I didn't know how! Synchronist (talk) 15:49, 9 March 2014 (UTC)
- You're welcome. Thank you for the clarification – it's quite interesting that the majority of people has day jobs which have little to do with their true desires and passions. I'd say that only truly successful companies are managing to somehow connect people's passions and commercial viability; in my opinion, that's what creates progress through creation of brand new products, ideas etc. — Dsimic (talk | contribs) 23:27, 9 March 2014 (UTC)
Inversion of control
Thanks for the thanks. I’m confused by your latest edits here. "Assembly object" is a fairly important concept. I’m not sure what your objection to it is, but I found the new edits harder to understand. I think we should put more work into this.Strebe (talk) 08:35, 11 March 2014 (UTC)
- Hello there! I totally agree that the Inversion of control article could be improved further – no article can ever be too good. :)
- Regarding the above linked edit, I really see no point in keeping the "assembler object" which is actually quite confusing – to me, it sounds like some special piece of object code doing the work while involving usage of an assembler (what's, quite frankly, next to a nonsense), or it also could be understood as some special object hidden somewhere while doing the magic. In fact, there's no such special object or code doing the inversion of control (or dependency injection), which is in fact an extremely broad concept based on what programming languages are offering through their basic language constructs. There's no mystery behind the whole thing, so defluffing the lead section by stripping out the "assembler object" can be only a good thing.
- Having the "assembler object" is pretty much similar to as if we had some kind of a "recursion manager" for the plain recursion, or a "template selector" for template metaprogramming. :) Hope you agree, and of course I'm more than open to further discussion. — Dsimic (talk | contribs) 03:22, 12 March 2014 (UTC)
As far as I'm noticed, the last part of the article was about whether that thing is android or not, but the last statement which i removed and you added back suggest there are android applications available......The system's android compatibility is announced officially and as far as I concerned, neither side of the argument used the ability to install many android apps as a main argument...C933103 (talk) 20:17, 14 March 2014 (UTC)
- Hello there, and sorry for my delayed response. I see you've already changed that part of the article, while leaving the part describing Aliyun's app store distributing pirated Android applications. It's pretty much important to keep the note on pirated applications, as it also confirms the fact Yun OS is capable of running ordinary Android applications what's related to the clash between Google and Aliyun regarding the true nature of Yun OS. I've improved that section further, please check it out. — Dsimic (talk | contribs) 21:28, 17 March 2014 (UTC)
The tech barnstar for you!

|
The Technology Barnstar | |
| For your extensive contributions in the field of computing. QVVERTYVS (hm?) 13:17, 20 March 2014 (UTC) |
- Thank you very much! Knowing your expertise in the field of artificial intelligence, I'm even more proud of this barnstar. :) — Dsimic (talk | contribs) 20:02, 20 March 2014 (UTC)
- Congratulations! (And thank you for improving my talk page by adding the two templates. I am still not very knowledgeable of the many templates that are available.) — Anita5192 (talk) 21:42, 20 March 2014 (UTC)
- Thank you, and you're welcome! The vast variety of templates (which is good, of course) is what makes knowing and using them quite time-consuming. Even worse, there seems to be no single point of entry into that maze of templates. :) — Dsimic (talk | contribs) 22:01, 20 March 2014 (UTC)
Minor wiki code cleanup on RAID
I'm glad I'm not the only one bothered by Lowercase sigmabot's failure to add a line break! Thanks for fixing it. Note that I complained about the issue earlier this month, but the issue stalled after the fix caused an error. If you would like, you are welcome to and reference my thread in the archives. – voidxor (talk | contrib) 05:05, 21 March 2014 (UTC)
- Hello there! Guess what, now I'm also extremely happy knowing I'm not the only person bothered by such things. :) Thank you very much for commenting!
- There's another related issue with this bot (or maybe another bot, will explain) – when the {{pp-protected}} tag is removed later by a bot, an empty line is left at the beginning of the article source code, producing in most cases additional empty vertical space when rendered into HTML and displayed. I've already fixed one or two of such removals, but unfortunately can't recall on which articles and whether it was the Lowercase sigmabot or some other bot removing the tag.
- Thank you for pointers to the bugfix request, I'll try to post again a bug report about these issues. — Dsimic (talk | contribs) 05:28, 21 March 2014 (UTC)
- Ah, yes, those empty lines were the error caused by the introduced bugfix; sorry, didn't go immediately through provided links. Why people don't test changes they make against such anticipated regressions? — Dsimic (talk | contribs) 06:10, 21 March 2014 (UTC)
Operating system–level virtualization
Hey, with this edit: Special:Permalink/596825429 you moved the article because of its punctuation. How do you know the correct punctuation? Help:Punctuation does not help me. User:ScotXWt@lk 15:47, 21 March 2014 (UTC)
- Hello there! Please have a look at MOS:ENDASH and a detailed discussion which addresses suffixed compound adjectives much further while slightly confronting with that MOS section; while you're there, it might be worth to also have a look at a related discussion. By the way, in case you haven't looked at the Manual of Style discussions before, you'll be discovering a whole new world of its own. :) — Dsimic (talk | contribs) 18:29, 21 March 2014 (UTC)
- Just in case anyone reads this later, here's another related MoS discussion – a lengthy one, of course. :) — Dsimic (talk | contribs) 05:34, 16 May 2014 (UTC)
And/or considered harmful
Thank you. :) Sloppy writing has no place in the compendium of the human knowledge, we should extinguish this uclear construct used by those too lazy to decide whether to use and or or. Sofia Koutsouveli (talk) 23:07, 21 March 2014 (UTC)
- You're welcome. :) I agree, and that's inline with "if you're gonna do it, do it right". — Dsimic (talk | contribs) 23:13, 21 March 2014 (UTC)
Blank lines in talk page discussions
Please don't insert blank lines between indented talk page posts, as you have been doing at User talk:Σ. This goes against both WP:LISTGAP (Do not separate list items, including items in a definition list (a list made with leading semicolons and colons)
) and WP:INDENTGAP (Blank lines should not be used between indented lines as they are currently rendered as the end of a list and the start of a new one.
). Thank you. --Redrose64 (talk) 09:59, 8 April 2014 (UTC)
- Yeah, I know about those list rules, but I have that bad habit only because it makes editing long lists easier – and I do that only on lengthy talk pages, never in articles. However, I'll do my best to get rid of that habit. — Dsimic (talk | contribs) 16:16, 8 April 2014 (UTC)
That guy
Oranjelo100 is at it again. Now he's moved on to game emulation. I'm not asking you to do anything. I just thought I'd let you know, in case he's continued abusing your scope of involvement with Wikipedia, because I saw your history of trying so valiantly and thoroughly to deal with this person. You handled it perfectly, and incredibly thoroughly, and positively but realistically, and I completely agree with you. You were given ridiculous advice such as "perhaps you could have been slightly" blah blah. No, you pretty much couldn't. :( — Smuckola (Email) (Talk) 10:57, 9 April 2014 (UTC)
- Hello there! Thank you for a heads-up and for kind words!
- Yeah, I've seen that Oranjelo100 is back, now in different parts of Wikipedia. The main trouble with him/her is complete absence of self-criticism and obviously not-so-good English. Well, English isn't my native language either, but at least I've been hard at work learning it for the past 20 years or so – and I still keep learning it. :) On the other hand, I'd say that Oranjelo100 is quite good in adding raw facts, but the troubles arise when raw facts are to be converted into good and usable content.
- At the same time, I'm sure we'll agree that nobody is perfect, but humans are supposed to become better with time and work – at least in theory. Making mistakes is a way to learn. Though, the trouble is I haven't seen any of those improvements from Oranjelo100, and I've seen tons of mistakes.
- Regarding those advices on the RFC, ah, you know how it is – those advices are generally good, but they're like proposing world peace and such stuff... It's all great, but how do we deal with the stuff currently on our hands? :) Should I have walked away from repairing damaged articles while proposing world peace? :) That's a standard issue with disconnected management, as things are always looking good from a greater distance.
- Hope it makes sense. Unfortunately, I'm afraid I really have no idea how to help, as talking to Oranjelo100 simply doesn't yield much. — Dsimic (talk | contribs) 17:27, 9 April 2014 (UTC)
Backporting
Hello Dsimic. I noticed you reverted my change to the backporting page. I used to think that backporting meant applying bug fixes from new versions to old versions just like the article used to explain, but https://backports.wiki.kernel.org and the http://backports.debian.org/ do not fit that mold, hence my expansion. As it is, the article is back to not defining the term in a comprehensive enough manner. Do you have a better definition? If not, all unrevert and let somebody else improve it. ARosa (talk) 04:23, 10 April 2014 (UTC)
- Hello there! Please allow me to explain why I've reverted your edit, and I'm sure we'll end up in further expansion of the Backporting article. Edit summary I've provided didn't describe it well, and I apologize for that.
- Basically, you've introduced a pretty much new (article-wise, of course) meaning of the term "backporting" only into the article's lead section, which is there to provide a summary of the article. In other words, that meaning of the term is nowhere available in the article, so introducing a new meaning only in lead section unfortunately isn't the way to go. The article requires a slight layout rework and a new section which is going to describe a somewhat different meaning behind the "backporting" term. Part of all that would be an update to the lead section, of course, but only together with expansion of the article.
- Currently, the article describes backporting as taking smaller pieces (like security fixes) from newer versions of software and incorporating them into older versions. New meaning for backporting is about incorporating much larger chunks of code, like complete device drivers or complete software packages. At the same time, current Backporting § Examples section pretty much isn't inline with the rest of the article, and article expansion would nicely tie it all together.
- Just as a note, the following sources could also be used as references for the new section:
- Hope you agree. Thoughts? — Dsimic (talk | contribs) 06:55, 10 April 2014 (UTC)
- Another example for the new section (and for Backporting § Examples section, of course), could be Red Hat's backport of GCC 4.4 from RHEL 6 to RHEL 5; please see Red Hat's documentation which is describing this further. — Dsimic (talk | contribs) 07:21, 10 April 2014 (UTC)
- You've gathered lots of good material. I edited the lead section to be more general. It'd be great if you expanded the article as you described.ARosa (talk) 03:17, 11 April 2014 (UTC)
- Ok, thanks, I'll have a look and expand the article further. — Dsimic (talk | contribs) 03:25, 11 April 2014 (UTC)
BSD
Hi Dsimic, good to see you added the bitstream entry. I'd refrained (I guess we both came to BSD dab from Phoronix?!) as there wasn't a vendor neutral target, so I quickly created something and changed the target and entry. Widefox; talk 09:35, 17 April 2014 (UTC)
- Hello there! Actually, I came to creating the BSD disambiguation link while reviewing edits – and one of them added link to a Phoronix article as a reference. A quick search on Wikipedia came back with no vendor-neutral destinations for bit stream decoder so I went by redirecting it to anything useful. That was the first step, and it's awesome you took it from there and improved further! — Dsimic (talk | contribs) 14:20, 17 April 2014 (UTC)
- Yes, I wanted to add it to the dab when I was cleaning it up, was surprised it wasn't defined anywhere so had left it lacking. Stream processing is a better target, but it'll do for now, and at least we're not making out it's only one vendor. I personally don't use anchors. Widefox; talk 09:17, 18 April 2014 (UTC)
- Explicit anchors do add some more complexity, but in my opinion they're very usable as many times section titles are changed, breaking the links. At the same time, it's much more neat to have an {{Anchor}} inside section titles rather than attaching those
<!-- warning: something links here -->comments. :) — Dsimic (talk | contribs) 03:36, 19 April 2014 (UTC)
- Explicit anchors do add some more complexity, but in my opinion they're very usable as many times section titles are changed, breaking the links. At the same time, it's much more neat to have an {{Anchor}} inside section titles rather than attaching those
Cache Intersystems
Why did you remove Cache Intersystems from well known DBMS? This is the premier DBMS for healthcare systems and many financial institutions. — Preceding unsigned comment added by 24.183.47.54 (talk) 01:59, 25 April 2014 (UTC)
- Hello there! Well, I've been dealing with databases quite a lot, and I've never heard of Cache Intersystems; I'm far away from being an absolute expert in databases, but at least should be able to judge what's a well-know DBMS and what isn't. :) If we go into covering a broad variety of various databases, we could also include now pretty much defunct Informix, for example – I know at least a dozen of big companies which are still using it. Even already listed FileMaker Pro should probably be also deleted. However, it's about providing a not too long list of well-known databases in the article's lead section.
- Hope you agree. Of course, I'm more than open for discussing this further. — Dsimic (talk | contribs) 02:40, 25 April 2014 (UTC)
- Cache Intersystems is a very well known DBMS that provides solutions outside of the relational DB model. This DBMS should at least be credited for its different style of database management. The article is currently skewed to provide bias towards relational models, the site should be more unbiased. Have you looked into the link I posted? Cache Intersystems in a non-relational database that is the fastest non-relational database system on the planet. I think that because it is the most efficient, and most used by healthcare (and some financial) institutions that it should be included. Please let me know why it is not included, if that's the decision that you reach. — Preceding unsigned comment added by 24.183.47.54 (talk) 04:06, 25 April 2014 (UTC)
- Well, as you insist I'm fine with the inclusion of a link to the InterSystems Cache article – go ahead, and I won't touch it. :) However, there are other non-relational and/or multi-dimensional databases claiming to be the fastest, like Palo OLAP database. — Dsimic (talk | contribs) 04:18, 25 April 2014 (UTC)
<tt> or <code> tags
You recently changed existing <code> tags to <tt> on the Crypto API (Linux) article. Why? As far as I can tell, there is no visual difference between them. "Code" seems like a more descriptive version and I've seen people convert them the other way around. -- intgr [talk] 09:32, 26 April 2014 (UTC)
- Hello there! Regarding my edit you've described above – <code> tag produces pale bluish (#F9F9F9) background for the rendered text, while <tt> tag doesn't do that. Here's an example, try adjusting your monitor to see the actual difference:
Here's some text with inside the <code> tag,- and some more text inside the <tt> tag.
- In my opinion, having no explicit background defined looks much better and it's mandatory in tables having background colors other than #F9F9F9 (what's the default for background-color), see Master boot record § Sector layout section for a few examples. The main reason why people tend to replace these tags the other way around is, I'd say, because the <tt> tag is deprecated in HTML5, but that isn't going to become an issue that soon. — Dsimic (talk | contribs) 21:20, 26 April 2014 (UTC)
- Ah I see now. I really didn't notice that background before you pointed it out. -- intgr [talk] 09:06, 28 April 2014 (UTC)
- Yeah, it's not that easily visible, especially on short <code> sections. — Dsimic (talk | contribs) 19:23, 28 April 2014 (UTC)
Hm, since when OpenSSH is a fork, and of what?
FYI OpenSSH is a fork of OSSH, which is a fork of ssh by Tatu Ylönen. See Project History and Credits page of OpenSSH site. — Dmitrij D. Czarkoff (talk•track) 21:16, 27 April 2014 (UTC)
- Thank you for pointing that out – there's always something new to learn. I've reverted my edit. — Dsimic (talk | contribs) 21:22, 27 April 2014 (UTC)
- At the same, I've expanded the OpenSSH § History section a bit, so it's also described there for future reference. — Dsimic (talk | contribs) 21:33, 27 April 2014 (UTC)
Microsoft Cortana Easter Eggs
Hey. Look at this: Microsoft Cortana Easter Eggs. Looks like someone makes an article every time Microsoft so much as sneezes or burps. 188.245.55.0 (talk) 15:20, 2 May 2014 (UTC)
- Hello there! Hm, that's a somewhat funny list of predetermined answers (just look at "You're awesome" which leads to "Thanks. My programming prevents false modesty, so I can't disagree."), but definitely not good for having a separate article, so my vote goes for it to be deleted. Thank you for a heads-up. — Dsimic (talk | contribs) 03:32, 3 May 2014 (UTC)
Discussion about unrestricted bootloader
![]() You are invited to join the discussion at Template talk:Infobox mobile phone#Unrestricted bootloader. You were selected because of recent edits to the article Android rooting. ViperSnake151 Talk 16:03, 2 May 2014 (UTC)Template:Z48
You are invited to join the discussion at Template talk:Infobox mobile phone#Unrestricted bootloader. You were selected because of recent edits to the article Android rooting. ViperSnake151 Talk 16:03, 2 May 2014 (UTC)Template:Z48
- Thank you for bringing it to my attention, I'll have a look at this discussion while trying to provide a NPOV opinion. — Dsimic (talk | contribs) 03:39, 3 May 2014 (UTC)
- Sorry for the delay, I've added my opinion a few hours ago. — Dsimic (talk | contribs) 12:56, 13 May 2014 (UTC)
Graphics Lab Request
Check the Graphics Lab. I've had a crack at the M.2 keying request. :) NikNaks talk - gallery 20:13, 5 May 2014 (UTC)
- Hello there! The SVG drawing you've created looks great, thank you very much for resolving the Graphics Lab request! I've added this picture into the M.2 article, and it helps a lot in explaining keying of the M.2's edge connector, as well as providing a depiction of the edge connector and socket with their pins/contacts overlapping on different sides. May I ask whether you'd be willing to have a look at another Graphics Lab request? :) — Dsimic (talk | contribs) 07:14, 6 May 2014 (UTC)
{kind=link}
- I'm very much a 2D artist rather than 3D, but if no-one else takes the request I'll probably have a go at it at some point. If it gets archived before it's finished, you're more than welcome to simply repost it. NikNaks talk - gallery 13:04, 6 May 2014 (UTC)
- Check the lab. :) Also, if your original request further up the page (where you link to PDF files) is no longer required, please let me know, or mark it resolved yourself, so that it can be archived. Thanks! NikNaks talk - gallery 18:37, 6 May 2014 (UTC)
- Another SVG drawing you've created also looks great, and it looks even better with larger labels, thank you very much! I've added this picture into the SATA Express article – it helps a lot in describing what the SATA Express motherboard (host-side) connector looks like, and how the backward compatibility with legacy SATA devices is ensured. Awesome! :)
- Regarding the Graphics Lab request for SATA Express connectors, unfortunately the content of PDF file is copyrighted so creating SVG drawings based on it doesn't seem to be acceptable. I'll mark it as resolved, as File:SATA Express motherboard connection.svg provides enough details until we can find a non-copyrighted source for all available variants of SATA Express connectors. — Dsimic (talk | contribs) 21:46, 6 May 2014 (UTC)
{kind=link}
- Okay, then. If you do ever find something suitable, of course, you're more than welcome to make another request. Glad I could help. :D NikNaks talk - gallery 22:40, 6 May 2014 (UTC)
- Thank you for creating the SVG files! I'll feel free to submit new Graphics Lab request(s). :) — Dsimic (talk | contribs) 23:36, 6 May 2014 (UTC)
Red Hat Linux article
![]() Hello, I'm Masssly. I wanted to let you know that I undid one or more of your recent contributions to Red Hat Linux because it did not appear constructive. If you would like to experiment, please use the sandbox. If you think I made a mistake, or if you have any questions, you can leave me a message on my talk page. —Sadat (Masssly)❤T☮C☺M☯ 21:03, 8 May 2014 (UTC)
Hello, I'm Masssly. I wanted to let you know that I undid one or more of your recent contributions to Red Hat Linux because it did not appear constructive. If you would like to experiment, please use the sandbox. If you think I made a mistake, or if you have any questions, you can leave me a message on my talk page. —Sadat (Masssly)❤T☮C☺M☯ 21:03, 8 May 2014 (UTC)
- Yeah, that edit probably requires some discussion so we find the best possible solution. I'll leave a message on your talk page. — Dsimic (talk | contribs) 01:42, 9 May 2014 (UTC)
- Ok, it's probably better to keep the discussion in one place, and you've also stated on your talk page that's how you prefer it.
- Regarding your revert on the Red Hat Linux article, here's why I've deleted the content in the first place. If you have a detailed look at the info it provided, it's pretty much about the history of Red Hat as a company, not about Red Hat Linux as a Linux distribution – deleted content could be classified as WP:TRIVIA simply because it goes too far away from what the article is about. Just as a few examples, what do "1986: ARPANET founded", "February 1999: IBM and Red Hat announce Linux Alliance" or "January 2007: Red Hat launches Certified Service Provider Program" have to do with Red Hat Linux as a Linux distribution?
- In other words, the deleted section could fit well into the Red Hat article which describes the company, but not within the Red Hat Linux article which describes the company's primary product that's a Linux distribution.
- Hope it makes sense. Of course, I'm more than open to discussing this further. — Dsimic (talk | contribs) 02:07, 9 May 2014 (UTC)
- Taking time to go through the article I understand what yo mean, that stuff doesn't really fit well in Red Hat Linux. Meanwhile some of that sundry information is pretty useful I wish someone could pick that up and include it in Red Hat "company" article. Thank you for corresponding. kind regards —Sadat (Masssly)❤T☮C☺M☯ 08:03, 9 May 2014 (UTC)
- I'm glad we're on the same page. It really hurts me whenever I delete anything that someone had invested a lot of time into, so I went ahead and added a to-do for the Red Hat article that refers to the deleted timeline content. Hopefully somebody will pick that up at some point in the future. — Dsimic (talk | contribs) 08:33, 9 May 2014 (UTC)
Discussion at Template talk:KDE
![]() You are invited to join the discussion at Template talk:KDE. Thanks. Codename Lisa (talk) 10:40, 19 May 2014 (UTC)Template:Z48
You are invited to join the discussion at Template talk:KDE. Thanks. Codename Lisa (talk) 10:40, 19 May 2014 (UTC)Template:Z48
- Thank you for bringing it to my attention, I'll have a look at this discussion while trying to provide a NPOV opinion. — Dsimic (talk | contribs) 20:43, 19 May 2014 (UTC)
- Thanks. It is always good to ask for the opinion of someone who knows more about Linux and its landscape. Best regards, Codename Lisa (talk) 13:01, 21 May 2014 (UTC)
- You're welcome! Nobody knows everything, but many people know a lot together – your edit on my talk page is a good example, thank you for pointing out that additional feature of the {{See also}} template! If I recall correctly, that feature might be a recent addition to this template, as I've seen it at least a few times where rendered output was "Article#Section" instead of "Article § Section"? — Dsimic (talk | contribs) 22:14, 21 May 2014 (UTC)
- Yes. It is rather new. Although § sign was part of Wikipedia and people loved {{section link}}, the number of people who knew about it was small. I asked an admin to implement a parsing function in {{Main}}, {{See also}}, {{Further}} and {{Details}} that converts # to § and people seem to love it.
- Now I don't go around removing
|l1=from people's talk pages; but you are open-minded and friendly. So, I abused your hospitality and did that edit.
- Best regards,
- Codename Lisa (talk) 02:30, 22 May 2014 (UTC)
- That's awesome, thank you very much for initiating such an improvement! I totally agree that the "Article § Section" format is much, much more readable and better in general. At the same time, please feel free to abuse my hospitality whenever it leads to improvements or learning of any kind. :) — Dsimic (talk | contribs) 05:11, 22 May 2014 (UTC)
About UEFI
I looked at the UEFI articles on 12 computers. Each one carried the n which was almost unreadable by people inquisitive of knowing what boot lingo mean. I thought I could help by making the n bold n.
Anyway, no issues. thanx for the edit. — Preceding unsigned comment added by Zambi007 (talk • contribs) 05:09, 21 May 2014 (UTC)
- Hello there! I totally understand your intentions, but that's not how Wikipedia's Manual of Style defines the intended formatting in its MOS:BOLD and MOS:WORDSASWORDS sections. It's all about keeping the layouts unified across various articles – hope you agree. However, if a reader is unable to distinguish the notion of pronouncing UEFI as "unify" without the n (as formatted in Wikipedia's style), he or she is also most probably unable to comprehend what the UEFI is all about, thus I'd say that additional formatting tweaks wouldn't be of much help in such cases. — Dsimic (talk | contribs) 06:06, 21 May 2014 (UTC)
Notice on "deletion heros"
![]() There is currently a discussion at Wikipedia:Administrators' noticeboard/Incidents regarding an issue with which you may have been involved. The thread is ScottXW and his "deletion heros". Thank you. Yunshui 雲水 08:29, 21 May 2014 (UTC)
There is currently a discussion at Wikipedia:Administrators' noticeboard/Incidents regarding an issue with which you may have been involved. The thread is ScottXW and his "deletion heros". Thank you. Yunshui 雲水 08:29, 21 May 2014 (UTC)
- Thank you for bringing it to my attention, I'll keep an eye on it. — Dsimic (talk | contribs) 09:07, 21 May 2014 (UTC)
Note that Editor Review has been retired
Hi, Dsimic: this is a notice that after a MfD and two RfCs, the Editor Review process has been officially retired. You should not expect further comments on your open Editor Review, which will be archived soon. In the coming weeks there may be information available on alternative processes that you can pursue if you so desire. —/Mendaliv/2¢/Δ's/ 21:05, 28 May 2014 (UTC)
- Hello there! Thank you for letting me know, I've removed the {{Editor review}} template from my user page. — Dsimic (talk | contribs) 22:16, 28 May 2014 (UTC)
SATA Express
Why does lowercase make more sense to you? If you are going to revert somebody's edit, you should provide a more elaborate reason than what arbitrarily makes more sense to you. – voidxor (talk | contrib) 05:09, 3 June 2014 (UTC)
- Hello there! Edit summaries don't allow for longer descriptions, that's why I wasn't elaborate enough. :)
- In a few words, MOS:BULLETLIST allows both sentence case and lower case for list items, and the lower case style made more sense to me because those weren't real sentences, and they were quite short at the same time. However, with latest edits that section grew up a bit, so I've edited the article by extending the section further and turning the list items into true sentences. Hope you find that acceptable. — Dsimic (talk | contribs) 23:32, 3 June 2014 (UTC)
Requested moves of "Android rooting" and "iOS jailbreaking" articles
Hi there, Dsimic! Now that the move of "Android rooting" to "Rooting (Android OS)" has been completed, I know you'll be interested in this parallel proposal:
I'll see you there, I'm sure! =) — Jaydiem (talk) 19:36, 16 June 2014 (UTC)
- Hello there! Thank you for bringing it to my attention, I'll keep an eye on it. — Dsimic (talk | contribs) 22:09, 16 June 2014 (UTC)
ZFS - use in commercial products
Thanks for letting me know that I had missed items for my ZFS edit. I've updated it, and it should meet the requirements, year & references. Let me know if additional information is required. A'kwell (talk) 20:30, 6 July 2014 (UTC)
- Hello there! You're welcome, and thank you for providing references and years, it looks good now! Went ahead and improved it further by touching it up, and by filling in a few references so they're now protected from link rot – please check it out. — Dsimic (talk | contribs) 22:26, 6 July 2014 (UTC)
- Great. Thanks for the extras. I'm still learning Wikipedia editing, so some of my updates will be a bit primitive. But, I have the technical details, (with proof), to contribute. A'kwell (talk) 02:32, 9 July 2014 (UTC)
- You're welcome. Just take your time, we've all gone through the learning phase here just as everywhere else. As a small suggestion—and I'm sure you're already well aware of it—there's the Wikipedia's Manual of Style as a great resource, which is also very usable outside of its primary role to be a general guide to editing Wikipedia. — Dsimic (talk | contribs) 04:46, 9 July 2014 (UTC)
En dash
I do not understand how the article can be full of e.g. "flash-based" with a hyphen, and that is fine, but as soon as it becomes "flash memory-based" the hyphen is supposed to change to an en-dash.
Why??? What is the justification here? What is the benefit? I think it just clutters up the wikitext, makes editing more difficult, and will require more redirects when these things get into article titles (since nobody will be typing in the keycodes for endashes in the search box). Jeh (talk) 06:50, 8 July 2014 (UTC)
- And from what I can tell, WP:ENDASH does not support you. "Instead of a hyphen, when applying a prefix (but not a suffix) to a compound that includes a space".
- ex–prime minister Thatcher; pre–World War II aircraft; but not credit card–sized
- "flash memory-based" is parallel to "credit card-sized", and therefore, per this point, should NOT get an endash. Jeh (talk) 06:56, 8 July 2014 (UTC)
- Hello there! I totally understand your confusion (BTDT), so please allow me to explain – I'm sure you'll see where are the benefits from the whole thing.
- As I've already pointed out in my revert on the Solid-state drive article, more details are provided in MOS:ENDASH and in a detailed discussion which addresses suffixed compound adjectives much further while slightly confronting with that MOS section; while you're there, it might be worth to also have a look at a related discussion. You're right that MOS:ENDASH currently doesn't state that en dashes should be used for suffixed compounds, but the above linked discussion(s) provide numerous arguments why the en dash rule should be extended to suffixes as well. That's something I simply don't agree with the MoS, and there are more editors sharing that disagreement – as you can see in these linked MoS discussions.
- What are the benefits of en dashes at all? Well, that's a good question. From one side, I've also thought a lot of ditching every form of hyphenation except plain hyphens; on the other hand, that would simply reduce value of the English language what can't be good. Sure thing, it's much more simple to use plain hyphens everywhere, but then we'll slowly end up with a text messages–style language, which is simply disgusting and in a long run makes people less smart without any true reasons of real-life benefits.
- Speaking of "flash-based" vs. "flash memory–based", it's all about "flash memory" being a compound. Having a hyphen in place indicates the relation between only two words ("flash" and "based", and "memory" and "based"), while having an en dash idicates that "based" relates to "flash memory" as a whole. Sure thing, human brain is advanced enough to figure out these examples even with no hyphenation, but if we'd extend that a bit further we could easily go even without capitalizing first words in sentences, right? :)
- Another examples of the en dashes usage (for a different purpose, of course) are Diode–transistor logic, Eye–hand coordination, Request–response, etc. These are all article titles, and they would have a completely different meaning if en dashes were replaced with plain hyphens; in those cases, using en dashes implies that the "linked" words remain independent what's important for the resulting meaning.
- Regarding cluttering of the Wiki code, en dash character (–) could be used in the source code instead of the – HTML entity. This should make Wiki code more clear; however, I find typing in HTML entites much faster than going into "Special characters" picker, scrolling a bit and clicking onto the en dash character provided there. Could've used the toolbar available under the source code edit box instead, but I'm somehow used to the "Special characters" picker for that purpose. :)
- Hope it all makes sense. Thoughts? — Dsimic (talk | contribs) 07:37, 8 July 2014 (UTC)
- I think you are vastly overestimating the percentage of readers who will even notice whether a "short horizontal line" is an en dash as opposed to a hyphen... let alone ascribe to that distinction the meaning you think they well. It's not as if we're talking about em dashes, which are obviously different. I am something of a "type person" and the only way I can tell if something on WP is an en dash vs a hyphen with perfect reliability (provided there are no examples of both next to each other) is to use character search on the page to highlight the latter. And your invocation of "slippery slope" is a logical fallacy.
- Anyway, as it stands, your edit and your reversion are contradicted by the MOS page. The discussions are interesting, but if there was consensus to agree to that change then the actual MOS page should have been changed. It is unreasonable to post MOS and then say "oh, well, you can't rely on that! See, this discussion says otherwise." Since when? Jeh (talk) 08:35, 8 July 2014 (UTC)
- Well, I can always tell the difference in legth between a hyphen and an en dash just by looking at them while reading. You're right that most people don't even know (or care about) the difference between hyphens and en dashes, what's somewhat sad. A flawed "slippery slope" or not, the very fact people don't know about that, or about the distinction in meaning, indicates something... Right?
- Linked MoS discussions could've resulted in actual changes to MOS:ENDASH, but there were a few editors completely reluctant to accept anything outside of their "by the Chicago Manual of Style" bubbles, so the proponents of changes lost their energy and interest.
- In a few words, please feel free to revert my changes, I won't stand in your way. — Dsimic (talk | contribs) 08:52, 8 July 2014 (UTC)
- Thanks. I may return to this. Jeh (talk) 09:56, 8 July 2014 (UTC)
- You're welcome. — Dsimic (talk | contribs) 10:15, 8 July 2014 (UTC)
Changing ref syntax on Android Runtime (ART)
Please do not use that style of citation syntax on articles. The |publisher field is designed to list the publishing company of the work, not the domain name it came from. The title of the website must be in either a |work or |website field. Also please do not use Android Police as a source; it is a blog, and blogs are typically not considered reliable sources. ViperSnake151 Talk 16:36, 8 July 2014 (UTC)
- Hello there! Thank you for pointing this out, moving forward I'll use the
|website=parameter. However, to me web sites are publishers and specifying their domains instead is more usable in many cases, but of course that's debatable. For example, if a LWN.net article is used as a reference, I'd say that 99% of people wouldn't recognize "Eklektix" when it's specified as a publisher, while "LWN.net" is pretty much widely recognizable. Should we end up using something like "|website=LWN.net |publisher=Eklektix" for this example? - Oh, and by the way, please consider including edit summaries in your edits, they're quite usable. :) — Dsimic (talk | contribs) 21:58, 8 July 2014 (UTC)
Kmscon
Thank you for your recent improvements to kmscon article. Posting here only because I didn't want to spam your echo notification log with multiple "thanks" (for each edit). Good work! — Dmitrij D. Czarkoff (talk•track) 08:19, 9 July 2014 (UTC)
- Hello there, and thank you very much! I'm glad you like those improvements I've made to the article. Oh, and of course thank you for your contributions to the kmscon article – that started everything. :) — Dsimic (talk | contribs) 00:59, 10 July 2014 (UTC)
OpenSSH reverse forwarding
Hi Dsimic,
I was just commenting on a feature SSH has. Yes, it allows to "punch" through a firewall, but I don't how that affects the text. Should I revert and append a reference to the manpage of openssh where that feature is described?
http://www.openbsd.org/cgi-bin/man.cgi?query=ssh&sektion=1 option "ssh -R [bind_address:]port:host:hostport"
Cruzzer (talk) 10:04, 14 July 2014 (UTC)
- Hello there! In your addition to the OpenSSH article, you've described that it "can also be done in reverse direction where the server receives access to the environment of the client." However, that's a bit confusing, as in that case it is still about tunneling connections (or port forwarding requests) that are initiated from the client, what's also clearly described in the man page you've linked above:
- -R [bind_address:]port:host:hostport
- Specifies that the given port on the remote (server) host is to be forwarded to the given host and port on the local side. This works by allocating a socket to listen to port on the remote side, and whenever a connection is made to this port, the connection is forwarded over the secure channel, and a connection is made to host port hostport from the local machine.
- [...]
- In other words, -R [bind_address:]port:host:hostport can be used to connect arbitrary TCP ports both on the server side and and on the client side through an SSH tunnel, but that's still the same thing no matter from which side we're looking at it. Thus, it might be a bit misleading to describe it as being "done in reverse direction", if you agree.
- Hope it makes sense. Went ahead and edited the article to include this info in a form that allows no misinterpretation by the readers. Please, check it out – hopefully you'll find this edit good enough. — Dsimic (talk | contribs) 11:54, 14 July 2014 (UTC)
- Avoiding confusion is surely the way to go. My intention was more to highlight the feature, as it's pretty unexpected from a network stance. It's also a security issue, as the client can open connections back into his own network, sidestepping firewall rules disallowing access to the client network. But I guess the the red "flag" is set with the --and to circumvent firewalls-- part. Cruzzer (talk) 12:44, 14 July 2014 (UTC)
- Right, there's already a note that SSH port forwarding can be used "to circumvent firewalls". Thus, if a reader is unable to grasp that, I'd freely conclude that no additional explanations about possible security issues would be helpful. — Dsimic (talk | contribs) 13:01, 14 July 2014 (UTC)
- Additionally, OpenSSH § Features section now contains a link to the SSH tunnel article, which describes potential security issues in detail. That should make it all covered, if you agree. — Dsimic (talk | contribs) 13:13, 14 July 2014 (UTC)
- However, went ahead and clarified it additionally. Please, check it out. — Dsimic (talk | contribs) 13:20, 14 July 2014 (UTC)
- Yes, I like that. Thanks for your help. Cruzzer (talk) 13:43, 14 July 2014 (UTC)
- You're welcome, and thank you for your contribution to the article – it started the whole thing. :) — Dsimic (talk | contribs) 13:59, 14 July 2014 (UTC)
Power supply unit
Re: Power supply unit (computer): the calculation is explained in the next sentence. Otherwise, the other result is not explained either. Glrx (talk) 17:42, 15 July 2014 (UTC)
- Hello there! Sorry, my bad, everything is fine with your addition to the article. Totally a brainfart from my side. — Dsimic (talk | contribs) 18:15, 15 July 2014 (UTC)
Re: List of M.2 SSDs as a section in the M.2 article
By this logic, the following pages should also be removed, correct?
- List of android devices
- Comparison of Linux distributions
- Comparison of smartphones
- Comparison of file archivers
- Comparison of tablet computers
- Comparison of wiki software
- Comparison of netbooks
- Comparison of firewalls
- Comparison of digital SLRs
- List of displays by pixel density
- Comparison of platform virtualization software
- Comparison of disk encryption software
- Comparison of handheld game consoles
- Cryptocurrency
- Comparison of portable media players
- Comparison of stackable switches
- Comparison of single-board computers
The list goes on ad nauseam, and that's only the computer related things! The fact is these drives are extremely hard to find information on, instead of removing a list that's a challenge to maintain, we should allow everyone to help grow the list like all these others... Isn't that the spirit of Wikipedia anyway? I created this list out of frustration over not being able to find a good list that shows all available, or even most of the available M.2 SSDs, which I'm currently in the market for. My original plan was to put the list on one of the forums I frequent, but then I thought 'this list would best serve everyone if it was available on an unbiased site where anyone can contribute to it'... There is only one place I know of like that — Preceding unsigned comment added by DracoDan82 (talk • contribs) 15:17, 16 July 2014 (UTC)
- Personally I agree with the removal and I think most of the above articles should go as well. Wikipedia should not be a product catalog. WP:ITSUSEFUL is not a valid argument for retention. Jeh (talk) 18:02, 16 July 2014 (UTC)
- So what about lists like the following?
- Where do you draw the line? There are literally thousands of articles that are either lists or contain lists of products.
- I guess it also depends on which definition of "encyclopedic" you use, I grabbed the following from google:
- en·cy·clo·pe·dic
- adjective:
- comprehensive in terms of information.
- relating to or containing names of famous people and places and information about words that is not simply linguistic.
- If you use the first definition then a list is absolutely encyclopedic, assuming the effort has been put forward to make the list as complete as possible.
- If you use the second (vague) definition then it could be argued that the list I created isn't encyclopedic, but then neither would half the other articles on Wikipedia that millions of people benefit from on a daily basis. — Preceding unsigned comment added by DracoDan82 (talk • contribs) 19:38, 16 July 2014 (UTC)
- Yes, those lists should go too. The one of "Dell PowerEdge servers" is particularly egregious. Google's first definition is belied by every encyclopedia on the planet. Tell me with a straight face that any encyclopedia includes "comprehensive" information about any subject it covers. If it did, then no other books or reference material would be necessary for any of those subjects! Can you learn all there is to know about, say, radio design or quantum mechanics or Egyptology from an encyclopedia? Of course not. You learn the history of the field, the key discoverers, the key theories and maybe a few of their implications. We don't need to have a list of m.2 products to provide similar information about the product category. Where do YOU draw the line? Should there be a List of machine screw-threaded fasteners, to include every combination of diameter, thread pitch, head drive type, core material, finish, etc., etc., from every manufacturer who's ever made them? If not, why not? Again, "WP:ITSUSEFUL to you" is not an accepted argument. Jeh (talk) 19:54, 16 July 2014 (UTC)
Hey everyone! DracoDan82, trust me, I understand your intentions and associated confusion, so please allow me to explain a bit further. Oh, and by the way, please sign your posts on talk pages. :)
Let's start with the definition of "encyclopedic"... As we know, Wikipedia has grown into a medium-sized :) monster when it comes to its Manual of Style and the set of rules articles need to follow, thus it's important what those rules say, not what a dictionary definition of "encyclopedic" might be. :) That's how every system works, and one must play by the rules of a system; luckily, Wikipedia's rules are truly awesome when you compare them to the rules of many other systems. Also, Wikipedia's rules can always be discussed, improved and potentially changed by the principle of establishing a consensus.
Regarding the first batch of "List of XYZ" articles, I totally agree with Jeh that almost all of them are clear candidates to be nominated for deletion. Let's just have a look at the Comparison of stackable switches article, for example – that article looks almost like a bad joke, as not even 25% of the available stackable switches are covered there. At the same time, that article should be called Comparison of stackable Ethernet switches instead, as there are also things like FibreChannel switches, for example – not all switches are Ethernet switches. It's always better not to have a list-of-XYZ at all, rather than having an incomplete and outdated list. On the other hand, lists are almost always badly updated, so they eventually become outdated.
At the same time, when a certain manufacturer (or even a model) is left out from the List of microwave owens, for example, such a list clearly becomes a favoring of other manufacturers (or models), what slowly creeps into the field of adertising. And, we're not here to advertise anything. :)
Let's have a look at more examples from the above. Comparison of Linux distributions is also a true mess, filled with pretty much outdated information; I've tried to clean it up once, and gave up quickly as I by no means have internal knowledge of 50+ Linux distributions, while becoming familiar enough (and staying familiar, for later updates) with each of them would be a very time-consuming (and pretty much pointless) thing to do. Of course, there are people on Wikipedia who have deep knowledge of all those Linux distributions—such people wrote the associated articles—but they either don't care about updating the Comparison of Linux distributions article or don't even know that it exists. Thus, sooner or later, all those lists turn into a mess.
Now, let's have a look at the second batch of "List of XYZ" articles, and compare it to the batch #1. The second batch has a much better reason for its existence, as each of the articles lists products coming from a single manufacturer, or a single line of products made by a specific manufacturer. Thus, even if a product or two are missing from such lists, that doesn't turn into advertising, what's a good thing. However, I'd never rely solely on the data available from the List of Dell PowerEdge Servers, for example, and instead I'd always go to the manufacturer's website; however, sometimes even the manufacturer introduces various changes to available server models that aren't even available on its website (and you become aware of them only after you've purchased a server – BTDT). With all that in mind, it's quite hard to expect "List of XYZ" articles to be always up-to-date. However, I'd say that the batch #2 doesn't deserve to be nominated for deletion, as it serves the purpose of an initial look-up for a particular product line.
Then, how does all that apply to the List of M.2 SSDs? Of course, that would be a good question. :) Well, if we had List of Crucial M.2 SSDs (or even List of Crucial SSDs) instead, I might vote for having such an article; though, it would be a quite short article. :) With the List of M.2 SSDs, there's simply too much room for turning it into advertising, especially as M.2 SSDs are currently a somewhat "hot topic" and a few manufacturers (as always) are trying to dominate the market.
Thoughts? — Dsimic (talk | contribs) 06:32, 17 July 2014 (UTC)
- OK, you have some points. Let's start by proposing one of those articles for deletion and see what'd happen. I proposed "Comparison of stackable switches" for WP:AFD, the discussion is open here: Wikipedia:Articles for deletion/Comparison of stackable switches. All of you are welcome to join that discussion and say again your arguments for or against deletion. Vanjagenije (talk) 10:25, 17 July 2014 (UTC)
- Thank you, we'll see how the deletion nomination develops and what the other editors think about the whole thing. — Dsimic (talk | contribs) 14:01, 17 July 2014 (UTC)
- The first discussion is over and the consensus was reached to delete "Comparison of stackable switches". I've continued by nominating "List of displays by pixel density" for deletion. Vanjagenije (talk) 20:50, 27 July 2014 (UTC)
- Great, thank you very much! List of displays by pixel density is a really bad article, and Comparison of smartphones might be later a good candidate for the next nomination round. — Dsimic (talk | contribs) 03:33, 28 July 2014 (UTC)
- My feeling is that the base articles for these things (like Network switch in this case) could well mention the most significant products in the field, the ones that represent significant advances, all put into historical context. But a list that includes all of the "me too" products doesn't serve the purposes of an encyclopedia. Jeh (talk) 06:08, 28 July 2014 (UTC)
- Totally agreed. — Dsimic (talk | contribs) 06:14, 28 July 2014 (UTC)
- As an example of what product coverage should be, look at History of IBM magnetic disk drives. Although many models there represent only incremental development, each is put into historical context, the fundamental enabling technologies are described, etc. IBM was long a leader in disk storage; many many advances in the field came from their labs, so this article is entirely appropriate for WP. That doesn't mean we should have exhaustive coverage of the myriad "plug-compatible", "work-alike" drives that were made by other companies. Jeh (talk) 01:27, 29 July 2014 (UTC)
- Exactly, History of IBM magnetic disk drives is a very good product line coverage article. At the same time, it reflects what I was referring to above while comparing the nature of List of M.2 SSDs and List of Crucial M.2 SSDs (or even List of Crucial SSDs) articles – even if some of the IBM's magnetic disk drives aren't included, that provides no room for turning it into anything similar to advertising. — Dsimic (talk | contribs) 14:35, 29 July 2014 (UTC)
- @Vanjagenije: Just checking, do you intend to continue with nominating these articles for deletion? Both nominations you've performed so far ended up in deletion, so it must be that we were right there. :) — Dsimic (talk | contribs) 09:57, 17 August 2014 (UTC)
- Actually, Comparison of smartphones ended with "no consensus" (Wikipedia:Articles for deletion/Comparison of smartphones), and newly created Comparison of Music Education Software is also going towards keeping (Wikipedia:Articles for deletion/Comparison of Music Education Software). I'm little bit tired of this. Would you continue with nominating? Vanjagenije (talk) 11:13, 17 August 2014 (UTC)
- Thank you for pointing out those already existing nominations for deletion. However, Wikipedia:Articles for deletion/Comparison of smartphones is a nomination back from 2010, and it's quite possible that points of view have been changed since then, especially when it comes to smartphones and such related articles. I'll see to nominate Comparison of smartphones for deletion a bit later. — Dsimic (talk | contribs) 07:47, 18 August 2014 (UTC)
- Sorry, just saw the actual nomination you've referred to, Wikipedia:Articles for deletion/Comparison of smartphones (3rd nomination). As that was article's third nomination for deletion, which also was closed just three days ago, there's simply no point in nominating it again. — Dsimic (talk | contribs) 07:59, 18 August 2014 (UTC)
- I'm sorry to say that this effort is pretty unappreciated by me, especially since it makes some of my IT research much more difficult. Glad that the comparison of smartphones deletion seems to have (hopefully) taken some of the steam out. Categorical removal of most of our (admittedly prolific) Wikipedia technology lists, which are a widely-used resource across the internet, based on let's just say a vigorously interpreted approach to rules, is a bad trend (in my opinion). Actionslike this are why so many people roll their eyes or express frustration at the idea of contributing to Wikipedia. – ImperfectlyInformed (talk) 03:23, 31 December 2014 (UTC)
- Sorry but WP:ITSUSEFUL is not considered a valid reason to keep an article that should otherwise be deleted. In my opinion, "sorry to say" but Wikipedia articles should not be parts or product catalogs. Such "articles" contribute nothing to understanding of the product category, of the progression of technologies, etc. An encyclopedia article should be more than just a table of unexplained, context-less facts, however useful the table might be to some. I think that one of the things that makes many people roll their eyes at the idea of contributing to Wikipedia is the presence of such low-grade articles, and the accompanying notion that anybody with a distributor's product list or product specs handy can "contribute to the encyclopedia" by copying product names, model numbers, and basic specs into yet another table-heavy article. Such articles also attract linkspam, new product announcements, etc., which further degrade WP's reputation. See my comments above about the History of IBM magnetic disk drives article, which I hold up as an example of a product-centric article that does belong here. If the "Comparison of smartphones" had that kind of contextual information, that would be a different matter. Jeh (talk) 05:01, 31 December 2014 (UTC)
- For a longer, more thorough explanation of what's wrong with this sort of stuff in WP, please see this unpublished draft. Jeh (talk) 05:09, 31 December 2014 (UTC)
- Hello there, ImperfectlyInformed! As Jeh already explained it, plain product lists usually end up as not-so-good articles. Beside going pretty much below from what the encyclopedic content should be, they almost always end up unmaintained and outdated; such articles usually don't attract many editors, what makes them prone to spam, advertisements, bias, and false or unreviewed information. In other words, creating a good article of that kind (History of IBM magnetic disk drives is a good example, while it's an article whose growth has ended) requires significant and continuous efforts; IMHO, the majority of "product list" articles simply don't attract the editors willing to put in required amounts of elbow grease.
- Another example of a similar type of article might be Android version history, which had engulfed significant amounts of work put in by multiple editors. At some points in time, working on it was so tedious and time-consuming that I've almost removed it from my watchlist and stopped contributing to it – and I'm a quite dedicated and determined type of person. :) — Dsimic (talk | contribs) 08:54, 31 December 2014 (UTC)
- What we are creating with Wikipedia is not set in stone. It is an evolving standard defined by what its editors determine to be acceptable, and personally I don't agree with the view that the priority is to write lengthy prose in the style of Encyclopedia Britannica. I've been around since 2007, Jeh has been around since 2005, and Dsimic has been editing a lot since 2013 (in other words, enough to get a very good idea of how Wikipedia's anarchist system works). I'm glad that Jeh prefaced his statement with "in my opinion" because that's what Wikipedia is about, and no personal statement (or even an essay such as commonly-cited arguments to avoid essay) is law. We debate a lot. I know just how much sucks but it's the way it is. Now, whether or not product lists are not-so-good articles is (debatably, if you you're axiologically inclined) an empirical and subjective question which could be most reliably answered by surveying our users, or our editors if they're not your priority. In my experience, lists are great for their purpose, and as a power Wikipedia user and editor, I've derived enormous benefit from them - and our users probably derive much more benefit from an article like Comparison of smartphones than the benefit which is derived from, say, the dozens of references I've added to articles like Tort, Trust law, or Economics and hundreds of much lower traffic niche topics. Lists in general are not easy candidates for "good articles"; as I recall, back around 2008 or so there was a campaign by a couple people to to delete a lot of list articles on that basis and on the duplication with categories, but when I pointed to WP:CSL, the steam was taken out even though that didn't change the sensibility of the decisions. In any case, you are welcome to boldly make and advocate for changes, and I reserve the right to express my own opposition within the limits of my available free time. :)
- As an aside, I mention the views of users seriously - it has been pretty well empirically shown that oldtimers like myself are actively hostile to newcomers (as documented by Aaron Halfaker, User:EpochFail). I'm pretty sure most prospective editors are more bothered by the detailed and voluminous rules than maintaining the style of an old-school encyclopedia. I realize I'm channeling this a bit myself in my approach here, but oh well! II | (t - c) 10:34, 31 December 2014 (UTC)
- Sure thing, Wikipedia is by no means set in stone and it's never going to be perfect, just as WP:IMPERFECT says – what's actually one of its strong points. At the same time, I don't think that the way Wikipedia works sucks; the debate is the key, and I always find open environments to be much better. The whole thing is very similar to how and why enterprises and startups differ, and why enterprises always need fresh blood in form of acquired startups: form eats function and kills innovation very quickly. Then again, having no rules at all also isn't good, and balancing the whole thing is a quite delicate act. And, of course, all that I've said (and what I'm saying right now) is just my opinion, nothing more. :)
- Please don't get me wrong, but I totally understand why the oldtimers may be hostile to the newcomers: newcomers usually don't show enough respect and take things too easy. That's why I didn't simply start to poke around randomly back in 2013; instead, I've invested a lot of time into reading many of the guidelines and policies first. Sure thing, it took me a few months to get a solid grasp of everything (we all know how long the MOS is, for example), but I've always listened to corrections from more experienced editors and continued to expand my knowledge. I'm sure you'll agree that not so many people are ready to invest a few months into the flat portion of a learning curve, no matter how beneficial the whole thing might be; learning LaTeX vs. using Microsoft Word is a good example outside Wikipedia. In a few words, newcomers usually bring in new ideas and that's excellent, but they tend to behave too cocky or lazy, even to the extent of not wanting to learn how to properly use the Wiki markup language; I've always been humble, and I don't intend to become cocky. :) To sum up my thoughts, breaking the rules is good, but one must know a lot to break them in a widely beneficial way.
- Speaking about the list-style articles, you've probably noticed that I'm putting emphasis on the long-term quality of such articles. From what I've seen so far, slapping them together quickly usually doesn't produce a good and reliable article a few months or years later. Please, let's have a look at another example, List of PHP accelerators article; it covers a quite popular topic, but it's so outdated and badly written that it might be better if we didn't have it at all. I've tried more than once to collect enough energy to do a complete rewrite of that article, but after looking at it for more than ten minutes all the interest simply faded away each time. That pretty much complies with the "first broken window" syndrome: usually, people like to improve already good things, but not so much to polish turds :) or to rebuild things from the ground up. — Dsimic (talk | contribs) 13:48, 31 December 2014 (UTC)
- Hey folks. Got the ping. It doesn't look like there's much for me to comment on here. I just wanted to hop in to agree with II. The media coverage of the Rise and Decline work is kind of crappy (as often happens with coverage of scientific work). I don't believe that we have any evidence that Wikipedia editors are jerks -- to the contrary actually. However, we have plenty of evidence that rule enforcement tends to scare newcomers away and the situation of rule enforcement tends to be old-timer vs. newcomer. We report on this carefully in the paper in question and much of our follow-up work has not been to seek and destroy mean old Wikipedians (or take away their tools), but to explore ways to improve old-timers/newcomer interactions (e.g. WP:Teahouse and WP:Snuggle). --EpochFail (talk) 16:39, 31 December 2014 (UTC)
- Hello! I also have no reasons to think that people here are bad; my own experience shows that (if I exclude only a few unconstructive or incompetent editors encountered so far) people are here with very good intentions. Regarding the rules, every system has its own set of those, and it's the duty of newcomers to learn them – as simple as that. If you want to drive a car, you have to learn how, learn the traffic signs, make a few (hopefully smaller) mistakes and learn from them, etc.; pretty much the same drill applies to Wikipedia. In other words, a common misconception is that teachers are evil jerks, but they simply aren't. — Dsimic (talk | contribs) 16:55, 31 December 2014 (UTC)
- Thanks for the detailed response, although I'm sorry to consume your time. Sorry, meant to include a link to Halfaker's Rise and Decline article, and I should clarify that I'm not picking on you guys in particular as being harsh to newbies but Jeh's offhand comment that "that one of the things that makes many people roll their eyes at the idea of contributing to Wikipedia is the presence of such low-grade articles" struck me as the opposite of my personal experience and the conclusion I would draw from that research. In terms of the low-quality and outdated articles, most articles on Wikipedia are hardly even in decent shape, but that by itself is clearly not a good reason to delete them. It makes me feel better to avoid looking at articles in terms of wholesale rewrites and through a lens of perfection, as that can make the messiness less frustrating. It's not realistic to expect Wikipedia to be without broken windows. You say that these articles are deserted and outdated, but that's an empirical question and a glance at, say, the edit history of the Comparison of smartphones shows dozens of different editors incrementally adding their improvements. The four AfDs to that article give an indication of the community's view towards deleting such articles (see, e.g., Wikipedia:Articles for deletion/Comparison of smartphones (2nd nomination)). And in some ways it is problematic to keep pushing for deletion as the prior commenters may not notice the re-raised issue. In that case User:DGG and User:Cyclopia are still highly-active, made strong arguments, and may be willing to reaffirm those arguments if they noticed the issue come up again. As far as I know, our system doesn't make it convenient to set an alert to be reminded when, in particular, an AfD proposal hits an article but I may set up an RSS feed on a few of these articles as a workaround. II | (t - c) 20:15, 31 December 2014 (UTC)
- No worries, this isn't wasting anyone's time; sweeping any issues or concerns under the carpet is never a substitute for discussing them openly. Sure thing, no system or environment is without broken windows; instead, it's more about how much time passes between the repairs. :) While looking at various articles, at least at over one thousand articles I've contributed to and watched over so far, it all depends on the editors interested in particular articles. IMHO, another big issue is how changes to the articles are reviewed; raw spam patrol is only one part of the whole thing and it works very well, but sometimes there are over three or four days before more subtle errors are fixed or improved.
- Based on comparing Wikipedia with my own experience in commercial environments, it's—as always—all about the people. As a system becomes more complex, it becomes tougher to introduce changes or new features into it without breaking already existing functionality. That's why systems tend to become more and more inert as they grow, as people simply can't track everyhing that accumulates over time. Of course, that affects the newcomers even harder, and hurts the oldtimers as they need to clean up the mess while repeating the same things over and over. But, that's probably the way the cookie crumbles. :) — Dsimic (talk | contribs) 22:02, 31 December 2014 (UTC)
- Pinging User:Vanjagenije as an fyi since he was also heavily involved; no to pressure to comment. I've said all I have to say; thanks for the hard work and I hope to get active here again when my life has settled down. II | (t - c) 06:04, 1 January 2015 (UTC)
- Just take your time, there's no hurry – we'll take good care of Wikipedia without deleting too many articles. :) — Dsimic (talk | contribs) 06:39, 1 January 2015 (UTC)
Ironically your revert comment came at a point I was fixing the same issue. See reworked version which should be simpler and more direct, and better tone (you probably saw it just now).
See what you think, fix what you need to, but try to avoid wholesale "plain reverting" :)
I look forward to discussing anything you want to, on the t/p later. FT2 (Talk | email) 14:38, 17 July 2014 (UTC)
- Hello there! Please don't get me wrong, as I've already noted on Talk:SATA Express § Stimulus for SATAe your latest additions to the article aren't bad per se, but they're simply way too wordy and make the article look a bit like a forum post.
- The only reason why I went with the "revert everything" approach (which I really don't like) is because at the moment I don't have enough time to dedicate for going through everything in detail. In the meantime (until later today, or early tomorrow latest), to me it's better to leave the old version. Of course, that's only my humble opinion. :) — Dsimic (talk | contribs) 14:50, 17 July 2014 (UTC)
kpatch listed at Redirects for discussion

An editor has asked for a discussion to address the redirect Kpatch. Since you had some involvement with the kpatch redirect, you might want to participate in the redirect discussion if you have not already done so. -- intgr [talk] 10:52, 21 July 2014 (UTC)
- Hello there! Thank you for bringing it to my attention, I'll provide some feedback in the above linked redirect discussion. — Dsimic (talk | contribs) 01:34, 22 July 2014 (UTC)
TSX article
HI, this is my first reponse on a talk page, please forgive me if I mangle this submission. I found your TSX page quite good. I was wondering if you have an affiliation with Intel or have a contact with someone responsible for TSX at Intel? Regards, AndrewX – 12.15.146.127 (talk) 13:07, 7 August 2014 (UTC)
- Hello there! No worries, it's Ok and I've just cleaned up your post a bit. :) Actually, I haven't created the Transactional Synchronization Extensions article, I've just contributed some improvements to it. Unfortunately, I have no connections with Intel, at least not beside using their products. :) — Dsimic (talk | contribs) 07:58, 8 August 2014 (UTC)
Which vs. That
There you go violating BRD again. Your reversion to your text (after your change was reverted) is considered edit warring. The next stage is supposed to be "Discuss". It is not BRRD. Jeh (talk) 07:26, 9 August 2014 (UTC)
- And your analysis is incorrect. The clause that follows which/that is not necessary to the sentence's meaning; it merely adds description. Therefore, according to your reference, "which" is correct. Jeh (talk) 07:30, 9 August 2014 (UTC)
- Hello! Please, let's not split hairs on the WP:BRD rule – as you probably know, I'm more than open for discussion and this is one of the places where we can exchange our views. Anyway, here's an excerpt from the style reference I've included in my edit summary:
- Use “which” plus commas to set off nonrestrictive (unnecessary) clauses; use “that” to introduce a restrictive (necessary) clause.
- ... and here's the edited sentence from the article (emphasis added):
- Price decreasing from about US$15,000 per megabyte to less than $0.05 per gigabyte by 2013, a greater than 300-million-to-1 decrease that corresponds to a 41% per-year increase in bytes per dollar (or a 29% per-year decrease in price per byte).
- According to the referenced rule, "which" is to be used for unnecessary clauses, and you've also confirmed that what follows which/that in the edited sentence simply adds a better description. That's simply true, there's no doubt. When looked from that side, "which" is the way to go; let's see how the sentence looks when that unnecessary clause is trimmed away:
- Price decreasing from about US$15,000 per megabyte to less than $0.05 per gigabyte by 2013, a greater than 300-million-to-1 decrease.
- To me, that doesn't sound great and it should be edited like this, what also complies with the referenced rule as the sentence still contains another unnecessary clause:
- Price decreasing from about US$15,000 per megabyte to less than $0.05 per gigabyte by 2013, which is a greater than 300-million-to-1 decrease.
- Now the sentence sounds good, at least to me. But, in this case returning back the initial unnecessary clause simply by using "which" (as the style refrence suggests) would look even worse:
- Price decreasing from about US$15,000 per megabyte to less than $0.05 per gigabyte by 2013, which is a greater than 300-million-to-1 decrease, which corresponds to a 41% per-year increase in bytes per dollar (or a 29% per-year decrease in price per byte).
- Now, that would be a true mess. :) Based on all that, using "that" is a much better choice. However, it could be me splitting hairs here, but please let me know where am I wrong and I'll be totally fine with using "which" in the first place. :) Also, maybe this could be some kind of a compromise:
- Price decreasing from about US$15,000 per megabyte to less than $0.05 per gigabyte by 2013, which is a greater than 300-million-to-1 decrease that corresponds to a 41% per-year increase in bytes per dollar (or a 29% per-year decrease in price per byte).
- Thoughts? — Dsimic (talk | contribs) 08:04, 9 August 2014 (UTC)
- Hello! Please, let's not split hairs on the WP:BRD rule – as you probably know, I'm more than open for discussion and this is one of the places where we can exchange our views. Anyway, here's an excerpt from the style reference I've included in my edit summary:
- I do not at all see how you arrived at "'that' is a much better choice". I cannot, in fact, imagine how you can at once accept the notion that "that" is used to introduce necessary clauses and then argue for its use on an unnecessary clause, just because it "sounds better". (A lot of correct things "sound wrong" to many because the correct grammar has been misused for so long.)
- In your compromise, "that" is still introducing an unnecessary (descriptive) clause, so "that" is still incorrect.
- The sentence was fine as it was, except that it needed the comma before "which"... and I was in the process of adding that when you re-reverted.
- The "true mess" is simply avoided by not using the "which" you're trying to introduce before "a greater than..."; not every descriptive clause needs "which" in front of it.
- As a side note, there are many other ways to handle multiple descriptive clauses: em dashes, parentheses, break the second one off into a second sentence ("This corresponds to..."). But I see no need to inject a compromise here when the dispute is not between two shades of right, but rather between right and wrong. You want to use "that" to introduce an unnecessary clause, and that's wrong. Please restore the previous wording. Jeh (talk) 08:45, 9 August 2014 (UTC)
- Ok, to simplify the things I've edited the sentence as you've suggested, tweaking it a bit further so we don't have a mishmash of parentheses, which'es and other constructs. Looking good? — Dsimic (talk | contribs) 08:59, 9 August 2014 (UTC)
- No. None of the other items get two sentences, this shouldn't. Jeh (talk) 12:18, 9 August 2014 (UTC)
- Why would something like that be important? That's really a hairsplitting; please feel free to edit the sentence as it suits your taste, I won't stand in your way. — Dsimic (talk | contribs) 20:20, 9 August 2014 (UTC)
- "I won't stand in your way." Well, that didn't last long, did it? I took you at your word and... Yet another revert notice in my inbox. I strongly feel that when you have a series of bullet items like this they should present information like this in as parallel a form as possible; one point should not have embellishments that the others lack. And no, the answer is not to add similar embellishments to the others. Jeh (talk) 17:48, 10 August 2014 (UTC)
- Please pardon me, but this is slowly becoming an inconvenience to me, and I'll try to explain why. Firstly, I didn't revert your edit, I've just restored the deleted sentence by converting it into a note by using "undo" feature to quickly fetch the deleted content and convert it. Just to emphasize it, I didn't simply revert your edit. At the same time, I've changed the edit summary so it doesn't trigger the "your edit was reverted" notification, as I've read somewhere in Wikipedia's guidelines (or in MediaWiki documentation, can't remember) that those notifications are based solely on edit summaries. Though, as we see that isn't the case, and I apologize for not using a different way to fetch the deleted content.
- Then, why is your opinion in this case so much more important than mine, and why is it so important to you that some additional information is deleted? Ok, I'm not a native English speaker, and I'm always more than open to receiving any criticism language-wise as that's the only way to improve myself, but this is no longer about the language and style. Sure thing, that sentence by far isn't the Holy Grail of HDD-related information, but why should we delete it, as it simply provides an additional perspective? Someone invested his/her precious free time to do the required calculation and provide some more content, which does no harm whatsoever; hitting "delete" on something like that makes little sense to me. Also, now as a note, it doesn't disturb the overall form of the surrounding bulleted list.
- Please don't get me wrong, I'm not here to argue, but I'm sensing some kind of pressure directed toward me, and (what's quite reasonable) that makes me uncomfortable. — Dsimic (talk | contribs) 05:04, 11 August 2014 (UTC)
As discussed in Talk:Hard disk drive § Highlights In History Section, bulleted list from the Hard disk drive § History section is now converted and compacted into a table, please check it out. At the same time, the troublesome footnote has been deleted. Looking good? — Dsimic (talk | contribs) 08:48, 11 August 2014 (UTC)
- And, here we go again – 71.128.35.13 went a step back and restored that footnote. Hm. — Dsimic (talk | contribs) 21:01, 11 August 2014 (UTC)
- See my comments at the talk page there. Jeh (talk) 00:59, 12 August 2014 (UTC)
National varieties of English
![]() In a recent edit to the page Transactional Synchronization Extensions, you changed one or more words or styles from one national variety of English to another. Because Wikipedia has readers from all over the world, our policy is to respect national varieties of English in Wikipedia articles.
In a recent edit to the page Transactional Synchronization Extensions, you changed one or more words or styles from one national variety of English to another. Because Wikipedia has readers from all over the world, our policy is to respect national varieties of English in Wikipedia articles.
For a subject exclusively related to the United Kingdom (for example, a famous British person), use British English. For something related to the United States in the same way, use American English. For something related to another English-speaking country, such as Canada, Australia, or New Zealand, use the variety of English used there. For an international topic, use the form of English that the original author used.
In view of that, please don't change articles from one version of English to another, even if you don't normally use the version in which the article is written. Respect other people's versions of English. They, in turn, should respect yours. Other general guidelines on how Wikipedia articles are written can be found in the Manual of Style. If you have any questions about this, you can ask me on my talk page or visit the help desk. http://english.stackexchange.com/questions/1338/are-collective-nouns-always-plural-or-are-certain-ones-singular Little Professor (talk) 18:33, 13 August 2014 (UTC)
- Hello! Additionally, per WP:ARTCON articles should be written in a consistent manner, following one of the English varieties throughout the article. Which one prevails in this article? — Dsimic (talk | contribs) 04:28, 14 August 2014 (UTC)
- Actually, Little Professor, it is you who would have been templated - except that Dsimic is too polite to template a regular. Intel is an American company and therefore articles about them and their developments should be phrased in American English. Nor is this a question of respecting the existing usage in the article. It contains numerous examples of treating "Intel" as singular, so your use of the British treatment of a collective noun goes against prevailing usage. Furthermore, you took what had been a completely dialect-neutral phrase ("Intel announced... which resulted in disabling...") and changed it to English dialect ("Intel announced... which lead to them disabling..."). In short it is you who are going against MOS:ENGVAR here, and you should withdraw and apologize for your complaint against Dsimic forthwith.
- Just by the way, we don't care much what stackexchange.com says about anything (even though, in this case, it supports the notion that American dialect treats companies as singular); it consists of user-contributed content and therefore is not what WP considers a reliable source. Jeh (talk) 05:25, 14 August 2014 (UTC)
- Thanks, Jeh. Getting a templated notification did look a bit strange to me, but I'm always more than eager to receive criticism related to my usage of the English language, as that's the only way I can improve myself. Anyway, I always assume that all editors are here to make both Wikipedia and themselves better. — Dsimic (talk | contribs) 09:00, 14 August 2014 (UTC)
WP:AN/I discussion on disruptive edits in Nvidia-related articles
![]() There is currently a discussion at Wikipedia:Administrators' noticeboard/Incidents regarding to discuss a disruptive IP-hopping editor that edits Nvidia-related articles. The thread is Disruptive edits by IP-hopper on Nvidia-related articles. Thank you. —Jesse Viviano (talk) 17:40, 14 August 2014 (UTC)
There is currently a discussion at Wikipedia:Administrators' noticeboard/Incidents regarding to discuss a disruptive IP-hopping editor that edits Nvidia-related articles. The thread is Disruptive edits by IP-hopper on Nvidia-related articles. Thank you. —Jesse Viviano (talk) 17:40, 14 August 2014 (UTC)
- Hello there! Thank you for bringing it to my attention, I'll see to provide some comments in the above linked discussion. — Dsimic (talk | contribs) 05:02, 15 August 2014 (UTC)
- @Jesse Viviano: Well, the WP:AN/I discussion got archived with zero responses from other editors. That makes me wonder why should you, Lonaowna or I care for those Nvidia-related articles? Who else cares? — Dsimic (talk | contribs) 20:47, 18 August 2014 (UTC)
- I just tried to resolve the situation. I used to automatically hate Nvidia products because a G86 GPU that was soldered to my laptop's motherboard failed due to the bad bumps issue and took the motherboard down with it. I had to spend a large amount of money to recover from that. Nvidia then hit another reliability low point with its GeForce 400 series which endured high RMA rates probably due to overheating. Later on, AMD's drivers for my Radeon HD 6970 started to crash on me when I am trying to read my email or use a web browser on my desktop machine I built after the failed laptop motherboard incident. AMD's driver quality apparently tanked after Carrell Killebrew, the then head of the AMD Graphics Product Group, was laid off from AMD. I had to replace my Radeon with an Nvidia card in my desktop build to solve the frequent crashes. Nvidia's poor sales figures and high RMA rates for its GeForce 400 series spanked some sense into Nvidia that we care about card heat and noise. Since the GeForce 500 series was not as hot, it was much more reliable. These incidents have left me with a bitter hatred for idiotic fanboyism for both sides. I still wish there was a way to force Nvidia to recall all of the G84 and G86 GPUs that were made with the defective stepping. (A later stepping fixed the bad bumps issue that destroyed my laptop's motherboard.) I also don't like someone spreading debunked statements on Wikipedia without explaining that they were debunked. Such half-truths and lies in Wikipedia without disclosing that they are debunked hurts Wikipedia. Jesse Viviano (talk) 22:52, 18 August 2014 (UTC)
- I'm not a fanboy either. Back in 2002–2006, I had two desktop PCs with Nvidia GPUs, and they both worked just fine under Linux with open-source drivers, what made me quite happy about Nvidia. Then, in 2007, I got a newer desktop PC with a more modern Nvidia GPU, which simply refused to work properly with even the latest available open-source drivers of the time. Speaking about garbled screens in X sessions (for example, all buttons in Firefox turn into black rectangles, and almost on a regular basis), manual upgrading to latest X and its associated libraries, and other extremely time-consuming endeavours aimed toward fixing the issues, I was forced to use Nvidia's closed-source Linux drivers. Aaargh, a binary blob as a module in my kernel?! Never thought of having those before, but that became an unavoidable everyday reality; at least the GPU worked fine with that huge (4–5 MB, IIRC) binary blob.
- Back in 2008 (or so) I got a laptop that came with a discrete Radeon GPU; I was already used to having binary blobs around. Linux support for Radeon GPUs can't be bad, right? If open-source drivers don't work, official binary blobs will do the trick. Not so fast! It turned out that open-source drivers existed only as a then-beta RadeonHD open-source project, while the official closed-source Linux drivers were a story of their own. For example, when a running X session is switched to virtual consoles (Ctrl+Alt+Fn), laptop's screen turns into something that extremely resembles a broken LCD, making it look as if moisture got into LCD from the bottom and destroyed it. You can imagine my feelings while looking at that for the first time. :) Luckily, those were only visual effects; of course, all that also locked up the laptop requiring hard reboots. After a few days of experimenting, I've ended up with hand-crafted RadeonHD open-source drivers, which worked but caused very reduced battery runtimes and made it impossible to use an external monitor. Sigh.
- Thus, I've been tortured with products from both manufacturers, but at least was lucky enough not to experience physically damaged hardware – I can feel your pain when your laptop's motherboard failed. :( — Dsimic (talk | contribs) 02:28, 19 August 2014 (UTC)
USB article
You're very welcome. Now I wonder what you think of my edits to your edits. One is basically a revert. :-)
As mentioned in the edit comment, other than forgetting the final "s" on "suspects", I really was quite fond of that description of the reason for PING packets "This avoids the need to send a large DATA packet if the host suspects the device will just respond with NAK." If that's actually unclear, I'm curious how you interpreted it. Anyway, I tried a different phrasing. (Good reference finding, BTW.)
One change I wanted to make, but haven't found the right words for, is to split up the two uses of "non-standard" in the cable plugs table. Mini-A to micro-B is weird, but perfectly reasonable. A to A may exist, but you can't talk USB over it.
Another thing I'm tempted to do is mark the mini plugs as deprecated, tinting the column & row headers, and switch the compatibility matrix entries to green. To me, that reflects reality a bit better. What do you think? – 71.41.210.146 (talk) 20:52, 16 August 2014 (UTC)
- Hello there! Regarding "ID pin" vs. "ID line", on second thought using "ID pin" should be actually better as it's used where connector pinouts are described. In other words, your revert is just fine with me. :) Your other edits are also fine with me, FWIW, especially simplification of the note in USB § Host and Device interface receptacles section – while it was acceptable before, I wasn't too happy with it as the provided description of differences in pin assignments between connectors wasn't precise enough. Thanks for improving the note so it's down to the exact differences; I've just cleaned it up a bit for improved readability.
- The description of PING packets was somewhat confusing, as it was unclear how can a host suspect that. That's much more clear with your additions, and (after thinking about it for some time) I've restored your initial wording, sligthly tweaked and now in addition to the already present additional description. Hope you're fine with that. In addition, I've just cleaned up and clarified that and another earlier section, together with adding two more references.
- Speaking about changes to the tables, I wouldn't change the colors or wording – both for "non-standard" combinations of cable plugs, and for Mini connectors. Why? Well, there's WP:COLOR that disallows color to be used as a sole carrier of the meaning, as there are blind people who use screen readers to access articles. Beside that guideline, introducing additional shades of color would probably be simply confusing. Thus, for the uses of "non-standard" I'd suggest a few notes to be added into respective table cells using the {{Efn}} template. For the Mini plugs and receptacles, I'd suggest we add nothing as they are deprecated but still used; please see WP:COMPNOW for something that might be used as a preservation analogy. Hope you find that acceptable. — Dsimic (talk | contribs) 08:23, 17 August 2014 (UTC)
- Good points, especially about color & accessibility. Sigh, that may mean I have to go back and fix my beautiful Conventional PCI § Connector pinout chart. Anyway, it appears we're basically on the same page and don't have any significant disagreements. Feel free to go nuts with a red pen on my edits, and I'll try to communicate in edit comments. I just like to start discussion when I get as close to an edit war as re-doing a change that you reverted. (TIL about Template:Diff.) 71.41.210.146 (talk) 09:27, 17 August 2014 (UTC)
- I'm glad that you find our discussion productive. :) Sure thing, there are no significant disagreements, it's all about improving the article by providing as clear and correct descriptions as possible. By the way, having small disagreements along the way is actually a good thing, as that way things (usually :) become better. And, of course, please feel free to change the content brought in with my edits.
- Regarding the chart you've mentioned above, redoing it might not be required as a color-coding legend is also provided. Though, I'm not sure about that; if there isn't anything similar described in WP:COLOR, it might be better to ask on Wikipedia talk:Manual of Style/Accessibility before changing anything. Oh, and {{Diff}} template is quite useful. :) — Dsimic (talk | contribs) 09:49, 17 August 2014 (UTC)
MOS:DAB
Hi. I linked the entries as I did on the dab page IML because WP:DABPIPE encourages linking the article itself, rather than redirects. ENeville (talk) 22:53, 18 August 2014 (UTC)
- Hello there! Thank you for pointing out this disambiguation linking guideline, I'll use it for my future edits related to disambiguation pages. — Dsimic (talk | contribs) 02:33, 19 August 2014 (UTC)
F5 Networks Corporate page
Hello - I notice you've undertaken a lot of work to build out the F5 page...nice work. Could you help me? I am wondering where the content for "history of software development" originates. I cannot find the sources and I am wondering if you are the brother of Bojan Simic and getting content from him. Any help you can provide is appreciated. – Jaim Harlow 17:39, 19 August 2014 (UTC)
- Hello there! Thanks, I've contributed a little bit to the F5 Networks article. Regarding the F5 Networks § BIG-IP software development history section, back at the time I was interested in the design of Traffic Management Microkernel (TMM), and I've contributed a few related references to that section. Unfortunately, I have no brother named Bojan, and those references I've contributed were simply Googled out. I'm sorry I can't provide a better assistance, but that's how it is. — Dsimic (talk | contribs) 18:17, 19 August 2014 (UTC)
Graphics Lab Request (Android Runtime...)
Just a heads up to let you know I responded to your request with a question. MjolnirPants Tell me all about it. 13:48, 21 August 2014 (UTC)
- Hello there! Thank you very much, I'll respond there in a few minutes. — Dsimic (talk | contribs) 04:47, 22 August 2014 (UTC)
Duff's device as outdated and harmful method of loop optimization
Hi. Thanks you for your comment in revert in Duff's device with link to WP:COMPNOW. I think we should somehow mention in introduction that this method was used in 1980-s and in early 1990-s, but can be harmful for modern optimizing compilers (it creates very complex CFG - control flow graph - which should be deoptimized back into simple unrolled loop before compiler can optimize it in correct way)... a5b (talk) 17:50, 21 August 2014 (UTC)
- Hello there! You're welcome; by the way, WP:COMPNOW is a recently added guideline and I've seen it as a result of watching the page it belongs to. As we know, relation between the Duff's device and modern compilers is already covered in Duff's device § Performance section, here's a quotation for completeness:
- This automatic handling of the remainder may not be the best solution on all systems and compilers – in some cases two loops may actually be faster (one loop, unrolled, to do the main copy, and a second loop to handle the remainder). The problem appears to come down to the ability of the compiler to correctly optimize the device; it may also interfere with pipelining and branch prediction on some architectures. When numerous instances of Duff's device were removed from the XFree86 Server in version 4.0, there was an improvement in performance. Therefore, when considering using this code, it may be worth running a few benchmarks to verify that it actually is the fastest code on the target architecture, at the target optimization level, with the target compiler.
- You're right that the article's lead section should also sum this briefly – went ahead and slightly expanded the lead section, improving one reference at the same time. Please check it out, hopefully you'll find it good enough. :) — Dsimic (talk | contribs) 05:42, 22 August 2014 (UTC)
- Thank you. PS: what do you think about Reliable Sources for Ribbon cable (flat IDE cable)? I added two at bottom after improving ru: article ru:Ленточный кабель. `a5b (talk) 00:48, 23 August 2014 (UTC)
- You're welcome, I'm glad you like changes to the Duff's device article. Regarding those two references, I presume you refer to these two edits to the Ribbon cable article? They look good and WP:RELIABLE; however, they should be converted into WP:FOOTNOTES, as in current form they're more suitable to be moved into new "Further reading" section. — Dsimic (talk | contribs) 04:37, 23 August 2014 (UTC)
Edit warring on Heartbleed article
Chealer continues to edit-war[2][3] on the Heartbleed article, even though I've asked them numerous times to discuss their changes on the article talk page, yet they still refuse. I'm not sure what to do next. Do you have any ideas? A Quest For Knowledge (talk) 23:44, 21 August 2014 (UTC)
- Hello there! Situations like this one are always a bit tacky; if an editor repeatedly refuses to discuss his/her edits, requesting a Wikipedia:Third opinion or reporting that on the Wikipedia:Dispute resolution noticeboard or Wikipedia:Requests for mediation are the only remaining options. Of course, reporting other editors isn't the nicest thing to do, but that's pretty much what remains if there's no possibility for a discussion. However, as this content dispute is currently about the section title ("Source code patch" / "Code patch" vs. "Resolution") and associated differences in the meaning, and as the whole thing has been somewhat discussed already, it would probably be much better to try discussing that with Chealer once again before reaching out to other mechanisms.
- At the same time, please have a look at Wikipedia:Dispute resolution and Help:Wikipedia: The Missing Manual/Collaborating with Other Editors/Resolving Content Disputes for more information. — Dsimic (talk | contribs) 06:13, 22 August 2014 (UTC)
- A Quest For Knowledge, you might want to have a look at Talk:Linux distribution § Information on GNU/Linux for my own lengthy, hair-pulling crusade with Chealer. Did you have other issues with this editor since August 2014? — Dsimic (talk | contribs) 16:51, 17 January 2015 (UTC)
DIMM
I think 'class="hintergrundfarbe6"' is a color code for the cells. I borrowed the tables from a German Wikipedia page haha, the class may not apply here. Thanks, again, for the help! — Preceding unsigned comment added by Jchap1590 (talk • contribs) 23:00, 24 August 2014 (UTC)
- Hello there! You're right, 'class="hintergrundfarbe6"' changes the color of table headers, I've confirmed that by temporarily changing Wiki code on the German Wikipedia page linked above. And, yes, that CSS class doesn't apply on the English Wikipedia. :) You're welcome, and thank you for your contributions to the DIMM atricle, I've just touched them up while reviewing the changes. — Dsimic (talk | contribs) 05:21, 25 August 2014 (UTC)
- Hey, I like the new table layout! It may be my browser version or some other factor, but it looks like there is a broken empty row from the DDR2 table on the second column of tables. I didn't see anything in particular that needed correcting, however. see here: http://i1304.photobucket.com/albums/s526/jason_chapman1/DIMMSpeeds_zps1d66ed8b.png Jchap1590 (talk) 22:09, 1 September 2014 (UTC)
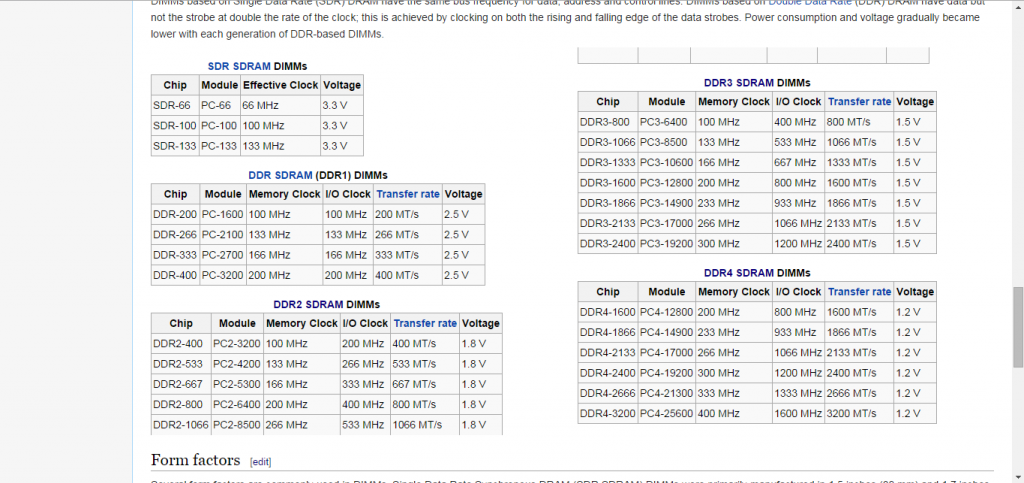{kind=link}
- Thanks, and that's a very good remark – you're right, there are some issues when {{Div col}} template is used for a compacted layout and columns contain tables; additionally, the template documentation states that it "handles wiki table code", but it's up to browsers to split the content into columns. I've just tried it in Internet Explorer 11, and I can only confirm that it doesn't render columns properly; though, I see it as an empty row inserted before the end of the DDR2 table in the first column, while its last row "overflows" into the second column – how much sense in the world does that make? :) Anyway, Firefox 31.0 renders it just fine.
- Went ahead and changed the way layout compaction is performed; that's still not an ideal way to do it, but unfortunately I'm unaware of a better way. It renders fine in Internet Explorer, but the issues are now on narrow screens – please try resizing your browser window and you'll see what I'm talking about. I'd really love to know if there's a better way to do it? — Dsimic (talk | contribs) 04:34, 2 September 2014 (UTC)
- Just tried another approach that uses {{Col-float}} template and it slightly simplifies the Wiki code. Though, it's still not ideal as column breaks must be specified manually instead of having a dynamically adjusted number of columns that's produced by the {{Div col}} template. — Dsimic (talk | contribs) 05:08, 2 September 2014 (UTC)
What was the RAMAC price and capacity?
![]() You are invited to join the discussion at Talk:Hard disk drive § An End To The RAMAC Price Duologue. Please help end the duologue on capacity and price of the IBM RAMAC Model 350 disk file. Thanks. Tom94022 (talk) 21:49, 4 September 2014 (UTC)Template:Z48
You are invited to join the discussion at Talk:Hard disk drive § An End To The RAMAC Price Duologue. Please help end the duologue on capacity and price of the IBM RAMAC Model 350 disk file. Thanks. Tom94022 (talk) 21:49, 4 September 2014 (UTC)Template:Z48
- Sure thing, I'll have a look into that in the next few hours. — Dsimic (talk | contribs) 21:57, 4 September 2014 (UTC)
- Done, added a comment. — Dsimic (talk | contribs) 05:06, 5 September 2014 (UTC)
Re: Explicit anchors
{{anchor|2-clause}}
=== {{anchor|2-CLAUSE}} 2-clause license ("Simplified BSD License" or "FreeBSD License") ===
Content ... ...
Hello. I assumed that {{anchor|2-clause}} and {{anchor|2-CLAUSE}} are hidden anchors and "#2-clause license ("Simplified BSD License" or "FreeBSD License")" is an explicit anchor, which is the opposite to a "hidden anchor". Maybe I got wrong, maybe you meant "anchor with an all capitalized name" by saying "explicit anchor"? --Tomchen1989 (talk) 23:09, 4 September 2014 (UTC)
- If so, I don't know why we should use an "anchor with an all capitalized name" instead of a normal anchor. Is there a guideline about this? Thx. --Tomchen1989 (talk) 23:12, 4 September 2014 (UTC)
- Please allow me to explain. In a few words, no anchors (as HTML elements) are visible in resulting web pages; let's have a look at what the HTML code looks like for a section title:
<span id="Section title" class="mw-headline">Section title</span>
- Creating a section also implicitly creates an anchor (the <span> HTML element above) with the same name as the section title, and that's what an implicit anchor is. On the other hand, placing {{Anchor}} templates explicitly creates additional anchors (hence the name of such anchors). The main benefit of explicit anchors is that they remain unaffected if a section becomes renamed later – that's why using explicit anchors is always a good idea when linking to sections.
- Regarding the all-uppercase names for explicit anchors, there are no guidelines regarding that (AFAIK) but I've seen a few other editors doing that for explicit anchors so I've followed them. As of why, that way it's much easier to distinguish implicit and explicit anchors wherever they're referenced – if it's an all-uppercase anchor, that's an explicit one. Hope you agree. — Dsimic (talk | contribs) 23:53, 4 September 2014 (UTC)
- Please allow me to explain. In a few words, no anchors (as HTML elements) are visible in resulting web pages; let's have a look at what the HTML code looks like for a section title:
- Ah you mean
{{anchor|2-clause}}and{{anchor|2-CLAUSE}}are explicit anchors, and"#2-clause license ("Simplified BSD License" or "FreeBSD License")"is an implicit anchor, just the opposite to what I thought LOL. Whatever.. Thank you for clarifying this. I'm aware of these concepts and techniques, I just didn't know what you meant by saying "explicit anchor".<a name="link_here"></a>(btw no whitespace is allowed in name or id attribute in the specification) was used, but now it is not supported by HTML5. Although the template's name is {{Anchor}}, it renders as a<span id="link_here"></span>rather than an anchor element<a></a>in HTML actually. - Well I still have a little doubt about that word "explicit" after doing a little lookup. It seems that WP:ANCHOR uses the word "explicit" to describe section title links.
- Anyway, it is not the definition of "explicit" that matters here. Under your definition, I've replaced an explicit anchor "#2-CLAUSE" with another explicit anchor "#2-clause". You can see in the article BSD licenses we have
{{anchor|2-clause}}{{anchor|3-clause}}{{anchor|4-clause}}with lowercased names, but we only have{{anchor|2-CLAUSE}}with a uppercased one. There should not be too much {{anchor}}. As a shortcut, one {{anchor}} for every section title is usually enough. It is reasonable to remove that "isolated" (no other anchor with uppercased name){{anchor|2-CLAUSE}}I guess. I don't see using all-uppercase name for anchors is conventional at all. Unless if it's an unwritten but relatively conventional approach used or advocated by even a small majority of editors, I don't think it's good to use uppercase names.--Tomchen1989 (talk) 00:52, 5 September 2014 (UTC)
- Ah you mean
- Sorry, this means that I was unnecessarily explaining concepts you're already familiar with. I apologize for doing that. Of course, thank you for further clarifications and corrections. By the way, I really don't know else how should the results of placing {{Anchor}} templates be called? You're right that WP:ANCHOR seems to be using word "explicit" for exactly the opposite anchor variant, but FWIW that makes little sense to me.
- Regarding
{{Anchor|2-clause}}in the BSD licenses article, I've contributed to the whole confusion by looking at the Wiki code by clicking on "edit" links right to the section titles; this explicit (or however it should be called :) anchor is placed in a separate line before the section title, what makes it invisible when a section is edited. I totally agree that{{Anchor|2-CLAUSE}}is then redundant, but according to documentation of the {{Anchor}} template additional anchors should be part of the lines that contain section titles (== {{Anchor|EXAMPLE}}Section title ==, for example). - All-uppercase explicit (additional or whatever) anchors or not? Of course, that's debatable as there are no guidelines that would either encourage or disallow such a scheme. To me, all-uppercase anchors are quite usable – again, FWIW. — Dsimic (talk | contribs) 01:25, 5 September 2014 (UTC)
- Well, technically and very strictly, I guess it can be called "a subordinate resource that can be pointed to by URI with a hash mark ('#') fragment identifier".
- But it can also be called:
- fragment identifier (strictly speaking, it's the "#ABC" "?ABC" stuff in the URI, not the resource it points to)
- link (but "link" usually refers to the
<a href=""></a>anchor, or the URL "http://...", rather than the thing we are talking about) - link within a page / link within the same page (understandable)
- internal link (very ambiguous. it has two meanings: 1. (primary) an anchor link to a page outside the same domain name; 2. the thing we are currently discussing here. The lead section of the article Internal link defines it using the first meaning, but the "Examples" section uses the second, this article definitely needs to be rewritten)
- section link (for Wikipedia pages)
- anchor / anchor name (as I mentioned before, "anchor" is an old school name and technically not that right since it's not necessarily an anchor element
<a href=""></a>. However the word is largely used and may considered OK)
- For the part where
{{Anchor|2-clause}}is outside the section and invisible when the section is edited, I put all those anchor templates inside their related section titles. --Tomchen1989 (talk) 10:19, 7 September 2014 (UTC)
- We should also take into account that it's the MediaWiki who diverts from the ordinary definition of HTML anchors, what was required for MediaWiki redirects and such stuff; a brief explanation is available here: Wikipedia:Village pump (technical)/Archive 121 § JavaScript and redirects issues?. As we know, including
#ABCin a URI works only with<a href=""></a>if there is no additional JavaScript code that would handle the page positioning. With all that, MediaWiki's "anchor" is pretty much unrelated to true HTML anchor elements – it's more of an abstraction of that concept, if you agree. - And, of course, thanks for folding the
{{Anchor|...}}templates into section titles! — Dsimic (talk | contribs) 20:56, 7 September 2014 (UTC)
- We should also take into account that it's the MediaWiki who diverts from the ordinary definition of HTML anchors, what was required for MediaWiki redirects and such stuff; a brief explanation is available here: Wikipedia:Village pump (technical)/Archive 121 § JavaScript and redirects issues?. As we know, including
Edit summary on Dalvik (software)
Hey, I just wanted to offer my apology since my edit summary wasn't as polite as it could have. Sorry about that and glad that you took it so well. Cheers! --uKER (talk) 02:39, 11 September 2014 (UTC)
- Hello there! No worries, just as I've stated in my consecutive edit summary that was a clear mistake from my side, and your disagreement was perfectly fine. The tone in which the disagreement was expressed might be debatable, but it was fine with me – I'm always more than open to having anyone point out my mistakes, as that's the best way for both personal and project improvements. In other words, I'd say that there was pretty much no need for the apology, however I'm happy that you've thought about it afterwards and I'm more than gladly accepting it. Thank you! :) — Dsimic (talk | contribs) 19:28, 13 September 2014 (UTC)
- While we're here, it might be good if I describe further the reason why I've reverted your edit on the Dalvik (software) article a few minutes ago. I totally agree with you that we shouldn't limit ART to the previews of Android L, but that's all what we have currently available from Android L. In my opinion, your edit is just fine but we should probably wait with it until Android L becomes released and available in its production form. Hope you agree. — Dsimic (talk | contribs) 19:36, 13 September 2014 (UTC)
- Well, I understand that theoretically there's the remote possibility that L could go back to Dalvik and to avoid going WP:CRYSTAL we should leave it, so well, while it's now what I'd do, I respect your concern. --uKER (talk) 20:34, 13 September 2014 (UTC)
Docker
Nice job on the Docker, it looks much better now! Best, --Nabak (talk) 16:16, 21 September 2014 (UTC)
- Hello there! Thank you very much, I'm glad that you like those layout improvements. — Dsimic (talk | contribs) 20:38, 21 September 2014 (UTC)
768×1280 is totally uncommon?
What about the Sony Xperia Z3 and the Sony Xperia Z3 Compact? --Jobu0101 (talk) 20:14, 11 October 2014 (UTC)
- Hello there! Regarding my edit on the Nexus 4 article, I probably wasn't clear enough in the provided edit summary. It was about "768×1280" being uncommon as the way to specify a screen resolution, not about how often screens with that resolution are found in cellphones. In other words, "1280×768" is the common way to specify this screen resolution; if you look around, it's almost always that the bigger number goes first. — Dsimic (talk | contribs) 20:41, 11 October 2014 (UTC)
- However, UKER just reverted my edit; if that's the standard format for cellphone screens, I'm fine with it, although "1280×768" is more logical to me. — Dsimic (talk | contribs) 20:47, 11 October 2014 (UTC)
- Screen resolutions have been historically expressed as Width*Height, and that's the way most technically correct sources mention it (see GSMArena, PhoneArena). Some sources use it the other way around (biggest length first) I guess for the sense of familiarity, as for example 1080x1920 doesn't ring the same bells in the public as 1920x1080. I, for one, am for keeping it as WxH, since it reflects the true orientation of the display, but feel free to put it up for discussion if you see fit. --uKER (talk) 23:13, 11 October 2014 (UTC)
- It all makes sense, and I don't see the need for starting another discussion. However, maybe I'm a bit old-fashioned, but I'm somehow "classifying" the screen resolutions mentally by their first numbers; thus, seeing "768" as the first number brings me a much worse sense of direction than seeing "1280" first. Of course, that's just me. — Dsimic (talk | contribs) 01:07, 12 October 2014 (UTC)
HHVM redirect, and capitalization of templates
Yes, I know HHVM is defined as HipHop Virtual Machine in that article; I meant exactly what I said, which was that no pronunciation is given. My point was that, as a native English speaker, I can see no way to pronounce "HHVM" other than as an initialism.
I admit all that was a bit unnecessary, so, sorry for such a wordy edit summary in the first place; but I digress. To get to the point:
- Does that capitalization convention also apply to
{{Redr}}or only the single-rcat templates? - Is this a serious enough issue that I should be editing redirects I previously categorized just to capitalize that "R"? My understanding is that such trivial edits are normally discouraged. Is there some previous discussion I should be looking at?
--SoledadKabocha (talk) 00:41, 12 October 2014 (UTC)
- Hello there, and thank you for the clarification! I can't pronounce "HHVM" in any other way either, not even in my native language if that matters. :) No worries about your edit summary, maybe it was just a bit confusing but adding
{{R from initialism}}was totally fine. - Regarding the capitalization of template names, that's debatable and I'm unaware of any associated official guidelines. However, I tend to capitalize them, and
{{R from initialism}}also refers to itself with a capital R. At the same time, I'd usually leave such edits to Wiki code unchanged, but I've used that more to quickly comment back. Not a great way to do that, I know; hopefully you find that acceptable. — Dsimic (talk | contribs) 02:09, 12 October 2014 (UTC)
Thank you
Thank you. I've been trying for a few years in the Turkish language. I know Wikipedia, but I do not have much English :( --Fsandlinux (talk) 19:28, 13 October 2014 (UTC)
- You're welcome, and thank you for your contributions. Just keep working and learning – almost everything can be accomplished by investing some time, together with applying just the right amounts of elbow grease. :) — Dsimic (talk | contribs) 20:16, 13 October 2014 (UTC)
Lollipop on Nexus 4
I think the guy you just reverted was referring to the fact that Google officially announced Lollipop for the N4 a couple of days ago. --uKER (talk) 12:54, 21 October 2014 (UTC)
- Well, I've reverted Harshal.dhumal's edit that pretty much changed the Nexus 4 article so Lollipop is stated as an offical and over-the-air upgradable release. As we know, Lollipop is still only a developer preview, which requires a phone to be flashed using one of the official preview images. Thus, to me it's better to wait a bit longer until Lollipop becomes released as a regular Android update. Hope you agree. — Dsimic (talk | contribs) 19:46, 21 October 2014 (UTC)
RAID-Z (non-standard RAID levels)
Hello again, there, sir! I was wondering if you would be able to provide assistance with improving the RAID-Z section (which was) in the non-standard RAID levels article. the information was unsourced and has been deleted by another user. I feel this is an important topic on the subject of non-standard RAID and would like to ask for your help in recreating the section. Thanks, in advance, for any consideration. Jchap1590 (talk) 07:33, 26 October 2014 (UTC)
- Hello! Thank you for bringing it to my attention; of course, I agree that RAID-Z deserves to be part of the Non-standard RAID levels article. Though, as everything else in Wikipedia, it needs to be backed by a few references – I'll have a look into finding better references, as the ones used for RAID-Z descriptions in the ZFS article are somewhat bordering with what's acceptable. To keep the discussion in one place, I'll post my findings and further opinions in Talk:Non-standard RAID levels § RAID-Z section you've already created. — Dsimic (talk | contribs) 08:54, 26 October 2014 (UTC)
Picture asking for republication in FUNKAMATEUR Magazine
Hello Dragan,
I found your Picture of a small Voltage and Current Meter for USB-Connections on Wikipedia: File:USB voltage and current meter.jpg.
{kind=link}
As I am preparing an article about Charging of portable devices from different sources and especially the Problems the User should be aware, I am asking you two questions:
- May I use this picture in the publication in the German Radio Amateur Magazin FUNKAMATEUR? Of course, I will mention it in a literature annex, where I've found it.
- Could you please give an Idea, were I will have a chance to buy such a useful tool? This question is primarily because I expect users to ask me or the publisher after publication where they may buy it and/or looking for more detailed specs, such as voltage drop on the GND or the VBUS line(s).
I am awaiting your kind reply. kind regards, or as Radio Amateurs around the world would say: vy 73.
Hartwig Harm, DH2MIC http://dh2mic.darc.de [in German :-( ] mailto: dh2mic@darc.de — Preceding unsigned comment added by 84.148.215.15 (talk) 16:05, 7 November 2014 (UTC)
- Hello there!
- Sure thing, please feel free to use this picture in the article you're preparing. The picture has been made available and licensed under CC-BY-SA-3.0, which allows pretty much all kinds of usage, though a brief attribution would be required.
- I've bought this gadget on eBay; since that time, other variants became available as well – some of them provide simultaneous voltage and current readouts, others even provide power measurements and estimated battery capacity readouts (in mAh, of course). More fancy versions even have OLED displays, :) and just saw that some versions additionally allow calibration to be performed by end users. Simply search for "USB meter" on eBay, and you'll see a whole bunch of such devices, which are also quite cheap at the same time (under $10). Unfortunately, detailed specifications for these measurement devices, such as their temperature dependencies and incurred voltage drops, do not seem to be available. However, accuracy levels are usually available, and they're typically specified to be within 0.1 V and 0.01 A error margins.
- As a side note, you might also find Wikipedia's USB article usable, sections USB § Power, USB § Charging ports, and USB § USB Power Delivery in particular. Those sections provide an overview of the power delivery over USB ports and involved negotiation between devices, as well as links to detailed documentation that describes it further and provides official specifications.
- Is your article, once it's published, going to be available online? I'd like to read its published version, if possible. :) — Dsimic (talk | contribs) 21:05, 7 November 2014 (UTC)
RfC appearance
The request about Wikipedia style and naming looks confusing. 84.127.115.190 (talk) 23:52, 9 November 2014 (UTC)
- Hello! Thank you very much for bringing it to my attention, I'll make sure to make it less confusing; that's the result of a bot listing it on Wikipedia:Requests for comment/Wikipedia style and naming. — Dsimic (talk | contribs) 00:25, 10 November 2014 (UTC)
- Done, it should be better now. Improved RfC description should be picked up soon by Legobot. — Dsimic (talk | contribs) 01:13, 10 November 2014 (UTC)
Red Planet Mars
My friend Dragan! First of all, I see that you have been recognized by one of my few other Wikipedia buddies QWERTYVS [or is it QWERTYUS ?]; and so I draw your joint attention to the anomalous Wikipedia entry on the movie "Red Planet Mars", which movie (which I have just viewed on Youtube) was a quite heartfelt and anomalous comment on the possibility that compassion is a universal reality! But the Wikipedia entry itself is way, way out there! Synchronist (talk) 05:25, 10 November 2014 (UTC)
- Hello! Unfortunately, I haven't watched Red Planet Mars yet, but I'll make sure to do that. Based on what's available in Red Planet Mars § Plot, I'd say that it describes what might be seen as "search for the higher goal". In other words, human society seems to be flooded with "you must have latest and greatest <something>, which is of course much more shiny, bigger and better", while things like alternative, less polluting energy sources are receiving much less (public?) attention. Knowing that we aren't alone in space might be a wake-up call for the search for the higher goal, bringing back more compassion into people's hearts at the same time. :) — Dsimic (talk | contribs) 06:36, 10 November 2014 (UTC)
1BASE5
Sorry for reverting your changes to Ethernet. I mistook 1BASE5 for 10BASE5. I don't think I would have made this error if you had linked to StarLAN instead of 1BASE5. I'm tempted to change that. Do you have any objection? ~KvnG 15:50, 11 November 2014 (UTC)
- Hello there! No worries about reverting those changes, we're all here to work together. I totally agree that it's very easy to see "10BASE5" while looking at "1BASE5", as 10BASE5 was actually used and seen around in commercial networks. While 1BASE5 is actually a redirect to StarLAN, I went ahead and clarified it a bit further; please check it out. Looking good? — Dsimic (talk | contribs) 17:21, 11 November 2014 (UTC)
Talkback (Bufferbloat)

Message added 18:21, 11 November 2014 (UTC). You can remove this notice at any time by removing the {{Talkback}} or {{Tb}} template.
Widefox; talk 18:21, 11 November 2014 (UTC)
- Hello! Thank you for bringing it to my attention, I've just replied on the article's talk page. — Dsimic (talk | contribs) 18:46, 11 November 2014 (UTC)
File:Linux kernel live patching kpatch
Category Linux kernel on Commons is empty, actually in use category Linux-Kernel. --Victor•talk 18:50, 11 November 2014 (UTC).
- Hello! That's a good point, thank you for pointing it out. However, having "Linux-Kernel" as a category name is simply awkward... I'll see how to get that cleaned up. Once again, thank you for the SVG drawing, it looks great! — Dsimic (talk | contribs) 18:57, 11 November 2014 (UTC)
- Done: After a lot of clicking around and editing, Linux kernel category replaced Linux-Kernel on Commons. — Dsimic (talk | contribs) 20:05, 11 November 2014 (UTC)
Lowercase username
I saw your desire for a lowercase username on your user page. While not technically possible for the reasons you state, you can somewhat fake it by adding {{Lowercase title}} to your user page and user talk page, then changing the capitalization in your signature. This is just merely a tip from your friend who also prefers a lowercase username. – voidxor (talk | contrib) 20:57, 13 November 2014 (UTC)
- Hello! Thank you for the tip, but that might create some kind of a discrepancy between different places where the same username is displayed, like in article histories, diffs, talk page posts, etc. Sure thing, changing the case of one letter doesn't introduce a huge discrepancy, :) but I've also seen some editors that use completely different names in their signatures, what makes quite difficult to track and correlate their edits in various places. With all that in mind, back at the time I've decided to ignore my desire and keep capitalized username all around. :) — Dsimic (talk | contribs) 22:05, 13 November 2014 (UTC)
English spelling reform
Don't feel bad about making this error; even native English speakers make it all of the time (myself included). The problem is English spelling—not you! May I suggest the following userbox? – voidxor (talk | contrib) 21:09, 13 November 2014 (UTC)
| Code | Result | |||
|---|---|---|---|---|
| {{User:Asarlaí/Userbox spelling reform}} |
|
Usage |
- Hehe, well, that mistake was a true brainfart from my side, and I wouldn't attribute it to English spelling. :) Speaking about the English-language spelling reform, that's a highly debatable topic... Inevitably, every language becomes changed slightly over time, but it also isn't good to lose the existing variety and fine language details. I always tend to compare such simplifications to the so-called Web 3.0 when it's displayed on large screens – it becomes a big question why large screens are actually needed. :) — Dsimic (talk | contribs) 22:43, 13 November 2014 (UTC)
Date format in Linux articles
Months ago, I wrote a review about Dsimic. I have defended this user when he made a good decision. Now, I would like Dsimic to reflect on his contributions; I am aware of what has happened in Linux distribution. 84.127.115.190 (talk) 06:02, 16 November 2014 (UTC)
- Hello! I understand your concerns, so please allow me to explain.
- It's all about bringing in opinions from more editors, as the whole thing in Wikipedia talk:WikiProject Software § Date format in release history sections of Linux articles pretty much turned into a not-so-well discussed imposing of additional rules to a WikiProject. Please don't get me wrong, I'm not trying to influence the outcome of the discussion; doing something like that would also be against WP:CANVASS. Instead, what I'm trying is to turn that into a much better discussion that would lead to a much broader consensus, which may be whatever we end up with.
- In other words, a few editors simply can't create new guidelines – a much broader consensus is required for something like that (please see WP:CONLEVEL). Furthermore, that proposed new guideline even went into effect in a few places, what simply isn't the way to go. Thus, the whole thing spins out of control and doesn't have much sense if we don't bring in more editors, and that's what I've tried to do by posting invitations to talk pages of a few editors with substantial edits in the field; doing something like that complies with WP:CANVASS.
- Hope you agree. — Dsimic (talk | contribs) 06:35, 16 November 2014 (UTC)
PAD Runtime
I'm not looking for support. I'm trying to warn people (and give accurate info) about the FACT that PAD, a game enjoyed by millions of people several times a day on Android, will not be playable for them once they allow the upgrade to 5.0. Since you're well-established here, perhaps you can add that info in the appropriate ways and places? To those who play the game (and those seeking facts about ART vs. D.) it is significant. Thanks! JT (talk) 02:13, 18 November 2014 (UTC)
- Hello! Thanks for the clarification. As with any major software release, or major architectural change in a mature software product, there will always be bugs, unforeseen troubles, and eventually broken stuff. Your report on this Android game no longer working with ART is valid, but unfortunately Wikipedia shouldn't list individual problems with particular software products; that would turn Wikipedia into a bug tracker, what it isn't. On the other hand, adding such info would be doable in case such problems are widespread (affecting numerous Android applications, in this case), together with having them backed by reliable sources. Hope you agree. — Dsimic (talk | contribs) 02:33, 18 November 2014 (UTC)
HDDs less than 100 MB
The HDD article concerns HDDs, not SSDs. HDDs less than 100 MB aren't common, because they're largely obsolete. Cluttering the article with SSD-specific provisos and eventualities is not justified. It just adds clutter. SSD formatting should be addressed elsewhere, not here.71.128.35.13 (talk) 22:55, 20 November 2014 (UTC)
- Hello! Thank you for bringing it to my attention, I'll reply in Talk:Hard disk drive § Partitions? File systems? RAID? section so we keep the discussion in one place and better visible to more editors. Just for later reference, it's about this revert on the Hard disk drive article. — Dsimic (talk | contribs) 23:19, 20 November 2014 (UTC)
DDR5 SDRAM
Could you weight in on Wikipedia:Articles for deletion/DDR5 SDRAM, since it seems that nobody feels qualified to "vote"? Thanks! Thue (talk) 18:45, 23 November 2014 (UTC)
- Hello! Thank you for bringing it to my attention, I'll have a look and possibly cast my vote. — Dsimic (talk | contribs) 22:41, 23 November 2014 (UTC)
- Done, unfortunately the article should be deleted as highly misleading; it seems to be created by a confused editor that jumped the gun over some quick searches for "DDR5". — Dsimic (talk | contribs) 23:27, 23 November 2014 (UTC)
Hi, there is broken link in article in Ref. #3. --Victor•talk 19:24, 23 November 2014 (UTC).
- Hello! Nice catch, thank you! I've just fixed the reference by pointing it to another web page that also provides man page for the ksplice-create utility, which covers the content in article's lead section. While we're here, may I ask you to have a look at the Wikipedia:Graphics Lab/Illustration workshop § A high-level overview of Ceph's inner workings section, just in case you might be willing to take that request as well? :) — Dsimic (talk | contribs) 21:59, 23 November 2014 (UTC)
- OK, I will. --Victor•talk 23:45, 23 November 2014 (UTC).
- Thanks! — Dsimic (talk | contribs) 23:46, 23 November 2014 (UTC)
Fixing a hole where the rain gets in
Dragan, I have for the first time found it necessary to stick a fork in something -- see my recent edit to the "Semantic Search" article. The guys at IDMARCH are giving semantic search a bad name, and so I have tried to follow the BOLD directive -- but perhaps there was a better way? Synchronist (talk) 04:41, 29 November 2014 (UTC)
- Hello! I had a look at your edit on the Semantic search article, and unfortunately there are a few issues. The biggest issue comes from the fact that, in general, editors should try to refrain from writing about something they're directly involved with; please see WP:COI for more details on possibly associated issues. Also, articles should never include links to Wikipedia user pages; even using self-written published articles as references requires additional attention, please see WP:SELFCITE for more details. — Dsimic (talk | contribs) 05:02, 29 November 2014 (UTC)
- OK, it's been undone, and thanks for keeping me on the straight and narrow! But if you find out anything about those guys at IDMARCH -- their motto is "Designed and built with all the love in the world in Europe", although the site is basically anonymous -- I would love to be clued in. Synchronist (talk) 15:30, 29 November 2014 (UTC)
- You're welcome, and I'm glad that you took it so well, so to speak. I know, it's quite difficult to go by all the guidelines, rules, essays and unwritten rules Wikipedia has in place – it's no surprise that nowadays not many editors contribute new content to Wikipedia articles. Speaking about that IDMARCH thing, right off the bat it looks a bit strange to me; with no description of who they actually are and why do they do that, it looks as just another AdWords revenue generator. — Dsimic (talk | contribs) 22:00, 29 November 2014 (UTC)
- Dragan, there has been a happy ending -- or perhaps beginning! -- to the story. I used the "whois" facility to get the email address of IDMARCH's founder, and we had a pleasant correspondence today (available here: http://www.space-machines.com/Nov_29_correspondence_with_IDMARCH_founder.pdf ), with the salient feature that he has added a facility to the web site enabling one to determine the number of hits for a particular article. Unfortunately, I have had no hits except my own, and so my consternation with Dragomir -- for that is his name -- has now now turned to solicitude. He really has pulled off a neat trick in indexing 7 million PDF documents -- the only one of the many semantic search engines out there, for example, to have found my two articles, if Google Advanced Search can be trusted in my hands, and the semantic indexing is really not bad. Furthermore, he has asked for ideas, and so I will be thinking about ways to help him in both practical and strategic terms. And given that I have alluded in the correspondence to a Wikipedia buddy who is perhaps his near countryman -- and the guy, in fact, who got the critical edit reverted! -- it would be quite appropriate for you to jump into the fray. All for now, but there is much, much more I could say about all of this. Synchronist (talk) 02:28, 1 December 2014 (UTC)
- Hey, that's great you've actually reached someone at the other end of the wire! I'd be extremely happy to see a semantic search website like that grow into something many people use to find better-matched content. I'll think about what could be added in terms of features, options, etc. For the beginning, it might be good for the website to include a description of what they do and why do they it, so it looks less like a puzzle. By the way, it's quite interesting to compare websites with US background and those having Eastern Europe or (in particular) Russian background – it might be only up to legal stuff, but the US ones tend to provide better descriptions of actual intentions that drive them. Oh, and based solely on Dragomir's last name, he and I could be considered countrymen only if we abstract out hundreds of miles and a few country borders. :) — Dsimic (talk | contribs) 05:52, 1 December 2014 (UTC)
Drives and other storage
Since you made the solid-state storage redirect, just notifying that because I have been informed there are some other kinds of non-drive storage (cards) I turned the SSS page into a disambig. Was wondering if you know any other types, or if I am wrong and other forms of solid-state storage like the SD Card might be considered drives in some way. --64.228.88.135 (talk) 01:29, 1 December 2014 (UTC)
- Hello! That looks like a good move to me, thank you! I've just improved it a bit, so the major meanings are listed, and so it conforms to the basic guidelines for disambiguation pages. There's also the Flash-based storage page, and I've turned it into a redirect to Solid-state storage – that should fit better with the now available disambiguation page. Just as a note, article links in general shouldn't point to disambiguation pages (linked example might not be very good as it was more of a prose addition, which might have introduced potential confusion that early in the article's lead section); please see WP:DABNAME for more details. — Dsimic (talk | contribs) 07:05, 1 December 2014 (UTC)
Illustrations in Unix-like article
Hello, both illustrations in this article are out of date: as if OpenBSD "quit" :) in mid-2013, as if Mac OS X is not OS X now and v.10.10, etc., etc... You may answer in Gr. Lab. --Victor•talk 08:54, 4 December 2014 (UTC).
- Hey Victor! Yes, both File:Unix history-simple.svg and File:Unix timeline.en.svg could use some maintenance. :) I'll see to compile a list of required changes to these two drawings, thank you for pointing it out! — Dsimic (talk | contribs) 10:33, 4 December 2014 (UTC)
{kind=link}
{kind=link}
About Skylake
We don't know its cache system until we see the actual product in fall 2015. Before that we'd stick with current info. Please do not edit this unless you're an employee that works for Intel. Thank you! — Preceding unsigned comment added by 71.57.33.215 (talk) 08:05, 6 December 2014 (UTC)
- Hello! Well, if you insist, leaving the article's infobox as-is is fine with me; also, cache-related information is already tagged with
{{Citation needed}}. However, it's quite unlikely that the L1 cache in Skylake is going to be bumped to 128 KB, but the time will tell whether that will be the case. — Dsimic (talk | contribs) 08:14, 6 December 2014 (UTC)
- All the back-and-forth (also known as edit warring) over essentially unsourced L1/L2/L3 cache sizes information is pretty much pointless, so it is better not to have that as part of the article's infobox at all. At the same time, content marked with
{{Citation needed}}may be removed if the sources haven't been provided for extended periods of time, and in this case no sources have been provided since October 2014. — Dsimic (talk | contribs) 18:31, 30 December 2014 (UTC)
- All the back-and-forth (also known as edit warring) over essentially unsourced L1/L2/L3 cache sizes information is pretty much pointless, so it is better not to have that as part of the article's infobox at all. At the same time, content marked with
PDF page links
Hi. I saw that you deleted the addition about PDF pages on WP:Citing sources, on the grounds of avoiding browser-dependent stuff and/or needing more explanation of where it works. As far as I know it works in all popular browsers, including the built-in PDF viewers and Adobe plug-ins for Chrome, Firefox, IE, and Safari. And according to SourceOhWatch (SrotahaUvacha), who originally added it, if a browser doesn't support it, then it degrades gracefully with the browser displaying the first page.
I added a comment to Wikipedia talk:Citing sources#PDF page links, with a link to a PDF explaining these hash URIs. If you know of any browser-dependent issues, could you leave a comment there? Otherwise I'd like to put it back. Thanks. – Margin1522 (talk) 15:03, 6 December 2014 (UTC)
- Hello! Well, the content I've deleted would require additional explanation; basically, it should be explained that it depends on built-in web browser functionality (or a browser plugin), and that it works only when a linked PDF file is viewed/opened inside a web browser. Despite the introduction of somewhat technical mumbo-jumbo, :) having that additional explanation would be beneficial. Hope you agree. — Dsimic (talk | contribs) 15:19, 6 December 2014 (UTC)
- OK, I think that since the only way to view a Wikipedia link is in a browser (right?), we don't need to explain that. But I guess it wouldn't hurt to add a caveat that the browser has to support it. There are dozens of viewers and OS variants for smartphones, and some of them might not. Would the following be OK?
- Note that this functionality depends on support from the browser's PDF viewer. In some cases, the browser may ignore the PDF page specification and display the first page instead.
- I don't think we have to worry about downloaded files. Users will expect the browser to download the whole file, which is what happens, and then once you have the file, the link where you got it is irrelevant. – Margin1522 (talk) 17:05, 6 December 2014 (UTC)
- OK, I think that since the only way to view a Wikipedia link is in a browser (right?), we don't need to explain that. But I guess it wouldn't hurt to add a caveat that the browser has to support it. There are dozens of viewers and OS variants for smartphones, and some of them might not. Would the following be OK?
- Actually, links to PDF files do not always end up viewed inside web browsers – some people prefer to use "open with" or even to save PDFs before opening them using a separate application. Furthermore, if we go into corner cases, someone could even use wget or curl to bypass the browser entirely. :) Anyway, your additional explanation is just fine, I totally agree on including it. By the way, as another editor pointed out, I was wrong and WP:YOU doesn't apply to guidelines, which already address readers directly in numerous places. — Dsimic (talk | contribs) 06:55, 7 December 2014 (UTC)
- That's a point. In the meantime, Mxn has restored it in the guideline with a better version of the caveat. He's also started a thread at Module talk:Citation/CS1/Archive 11#PDF page links, where Gadget850 pointed out that this has been discussed before and rejected for reliability reasons. – Margin1522 (talk) 07:47, 7 December 2014 (UTC)
- Went ahead and improved the guideline addition (clarified and added the note you've proposed above), hope you find it good. Yeah, I saw the module talk discussion, and it surely isn't "dependent on the server", as web servers generally have nothing to do with the URLs they're requested to serve. Of course, if a PDF file isn't served statically that's another story, but the majority of PDF files are served that way. — Dsimic (talk | contribs) 07:58, 7 December 2014 (UTC)
Piped links
Don't do this again. It is pointlessly antagonistic. There is nothing which makes an editor look less suitable for collaborative development than this sort of idiotic revert war. The rationale behind keeping the case is that if the link is somehow transformed such that the piping is no longer necessary (such as in "Interface" in your example, where the pipe trick means the piped text can be omitted entirely in the edit) it doesn't accidentally enter wrongly-cased text. If you've some control issues with your life that you need to work out, do it somewhere else. Argh, and this was going so well. Chris Cunningham (user:thumperward) (talk) 10:32, 11 December 2014 (UTC)
- Hello! If I may notice, your commanding tone isn't that friendly, and it simply doesn't help in making Wikipedia a good and collaborative environment. If there's a disagreement, we're here to discuss it and find a solution whatever the subject is. Anyway, is there a guideline about that, or are those just your own preferences for piped links? As far as I can see, Wikipedia:Piped link says nothing about the case; by the way, the tone you used in an edit summary while adjusting that guideline today also doesn't seem to reflect a great amount of tolerance and openness to discussion.
- At the same time, please stay away from involving any personal issues as you see them – no editor, myself included, simply doesn't deserve to be addressed that way. We're here to make articles better; as WP:TPYES says, "comment on content, not on the contributor". Also, as an administrator, you should be the one who promotes friendliness and tolerance, and helps in reaching compromises and solutions for various issues that are inevitable along the way. — Dsimic (talk | contribs) 11:40, 11 December 2014 (UTC)
- The precise tone I use is dependent on context. You've demonstrated that you're a mature editor with a solid understanding both of the technical matters of what you edit and of the editing process itself. Accordingly, I'm not going to beat around the bush when confronted with passive-aggressive nonsense like this (not by any means the first summary revert I can remember). I've provided an actual rationale, whereas you simply pointed at an example without any elaboration on why you think that example said what it did. The onus is on you to explain your edit, not on me to find some stone tablet marked with instructions that back up the rationale I've provided. But I'd far rather you simply stopped doing it, and reconsidered whether using the undo button on good faith edits is improving the project. That article has a long way to go (though it's getting better incrementally) and it needs its editors to be cooperating rather than competing with one another. Chris Cunningham (user:thumperward) (talk) 12:58, 11 December 2014 (UTC)
- No matter how something is or isn't to be approached softly, friendliness and non-commanding tone only demonstrate one's maturity and improve the overall desire toward collaboration and team work. Also, technically speaking, I didn't revert your edit, as that wasn't performed by clicking on the "undo" link. However, the way my edit was performed is less important, and here's why I find capitalized piped links to be suited better.
- As we know, Wikipedia internally capitalizes article titles by default and nothing can be done to prevent that; using
{{Lowercase title}}only displays lowercase titles while reading articles. Thus, following the Wikipedia's approach down to piped article links makes things more consistent; the text to right of the pipe is what's to be displayed, while the text on the left is pretty much Wikipedia's "key" for the linked article. In regular non-piped links, using a lowercase title (where appropriate, of course) actually determines what's displayed, with automatic conversion into article "keys" (capitalized titles) when a page is rendered and actual URLs are generated. In other words, using "keys" in piped links stays to Wikipedia's (externally visible) internal way of referencing articles. - Of course, a perfectly logical question for my train of thoughts is "why shouldn't then
[[Article|article]]also be used?" Because only the first letters in article links become automatically capitalized, no matter what, and that can be relied upon to produce valid "keys". At the same time, repeating pretty much the same string twice would be overly redundant. - Considering your rationale toward keeping piped links case in accordance to their positions in sentences, so someone later isn't going to put a capitalized word in the middle of a sentence, I'd say that "foolproofing" it that way simply isn't worth it. Unfortunately, if an editor isn't careful enough to click on "show preview" and review his/her changes before hitting "save page", nothing helps, and we'll probably have much bigger errors to handle than needlessly capitalized words.
- Hope it makes sense. — Dsimic (talk | contribs) 14:12, 11 December 2014 (UTC)
- The English Wikipedia's use of initial uppercase in article titles is a hack for articlespace; it's not the preferred form for MediaWiki itself (nor the other namespaces on en-WP), and in any case the very last thing we should be optimising for is the backend codebase. It is far better to optimise for editors, who should see as few implementation details as we can get away with. As far as editors should be concerned, Example and example are exactly equivalent, and thus "optimisation" of pages by piping the latter to the former shouldn't even be considered. What that boils down to is that we should not be including capital letters in links unless except in the specific case that we want them in the output. Chris Cunningham (user:thumperward) (talk) 10:50, 12 December 2014 (UTC)
- While understanding your reasoning, I still respectfully disagree. It's perfectly fine to have different opinions on things not covered by any explicit rules or guidelines, and probably the solution in this case is not to modify case of piped links once they're placed into an article's Wiki code. — Dsimic (talk | contribs) 13:25, 12 December 2014 (UTC)
- Nope. Your version is demonstrably broken IMO, leading to unnecessary piping for pointless optimisation. I fixed this during routine copyediting and will continue to do so in future. I don't expect that such changes will be reverted in future. Chris Cunningham (user:thumperward) (talk) 13:59, 15 December 2014 (UTC)
- How can that be clearly demonstrated, and how does that cause "unnecessary piping"? What I've questioned above about
[[Article|article]]was not a suggestion for something like that to be used, but exactly the opposite; that was just a self-asked question for my reasoning. - Also, I expect you not to do such copyediting, as there are no related guidelines; moving forward, I won't do such changes either. Changes in case would be similar to switching articles between different styles, what's—as we know—explicitly forbidden in the lead section of WP:MOS and further explained in this ArbCom ruling. — Dsimic (talk | contribs) 14:22, 15 December 2014 (UTC)
- How can that be clearly demonstrated, and how does that cause "unnecessary piping"? What I've questioned above about
- It's not "switching articles between different styles"; it was only present in a couple of sentences. I don't really expect to find many articles where this idiosyncrasy has been prevalent since article creation, but if I do then you're free to invoke ArbCom rulings regarding style changes on said pages if you wish (though I dare say most people would consider invisible changes like this to be a different matter from the language and date formatting disputes that led to ENGVAR). Chris Cunningham (user:thumperward) (talk) 14:29, 17 December 2014 (UTC)
- It does involve some kind of switching an article or its part between different styles, or better said, between different personal preferences. If something isn't explicitly regulated by a guideline, and if there are multiple ways to do it with the same or similar final results, then that is some kind of a style and the only good solution is to leave it as-is while copyediting articles. Thus, there's simply no ground for saying that you "will continue to do so in future" – in that case I also have the same right to implement my preferred style; though, as we probably agree, there's no point in doing something like that. Of course, there's also the article-level consistency argument that may justify such changes in style, but that clearly wasn't the case in BIOS article.
- Would you feel comfortable if I ask for a WP:3O on this? We're clearly in a slight disagreement here, and a third opinion might help. — Dsimic (talk | contribs) 22:49, 17 December 2014 (UTC)
- IMO it's far too much work to have to decide whether any particular area of syntax oddness is due simply to sloppy editing or some editor's particular writing idiosyncrasies across the entire encyclopedia, and therefore editors shouldn't be expected to do so, particularly in cases where the style in question is obviously not in common use. You can ask for a 3O if you like, though I'm sure you're aware that as a non-binding process it's unlikely to resolve an issue which is basically a difference in personal aesthetics. Chris Cunningham (user:thumperward) (talk) 13:18, 18 December 2014 (UTC)
- That's exactly why I've said that the case of already existing piped links should simply be left unchanged while editing articles – that way no personal preferences would be involved into something that isn't regulated by Wikipedia's guidelines. Also, based on my experience,
[[Article|something]]form is much more commonly used than[[article|something]]. Thus, capitalized form is far away from being "not in common use". — Dsimic (talk | contribs) 13:56, 18 December 2014 (UTC)
- That's exactly why I've said that the case of already existing piped links should simply be left unchanged while editing articles – that way no personal preferences would be involved into something that isn't regulated by Wikipedia's guidelines. Also, based on my experience,
Article on restrict
Just saw your edit on restrict with the pithy description "Hm, doesn't look like an improvement". How is marking an example as flawed (is not actually an example due to other issues) even if one cannot (maybe just then) add a correct one, *not an improvement*? I reverted your edit. 94.220.161.15 (talk) 22:57, 13 December 2014 (UTC)
- Hello! I apologize for my terse edit summary, please allow me to explain it here. First, the changes I've undone introduced additional spacing that's too Java-like and doesn't improve the code readability. Second, but not too important, since when "UB" is an abbreviation for "undefined behavior"? Sorry, but I've never heard of it. Third, what's the point of saying that those pointers might overlap? Surely they all might overlap or point to exactly the same location, as pretty much nothing of that is checked against by the C language, compiler or runtime; even with
restrictin place, the pointers can still overlap or be the same asrestrictis merely a hint to the C compiler. Additionally, could you please elaborate a bit on how and why the example in Restrict § Optimization section is broken? - Usually I wouldn't immediately revert an edit performed this way (with an ongoing discussion), as doing something like that pretty much isn't by the WP:BRD, but your edit is somewhat misleading; thus, I've dared to revert it. Hope you understand, and I'm more than open to discussing this further. — Dsimic (talk | contribs) 08:57, 14 December 2014 (UTC)
Mousing
Hi, re this edit, mousing is a word, see wikt:mouse#Verb. --Redrose64 (talk) 19:15, 16 December 2014 (UTC)
- Hello, and thank you for pointing that out! Got my associated neural paths updated. :) — Dsimic (talk | contribs) 20:16, 16 December 2014 (UTC)
CPU and SMP configurations
In early computer the CPU it was the only unit that handed all the system. The only "clever" unit. All passed through the CPU (memory accesses, interrupts, etc.). So that the name "central". To day the function of old CPUs is to execute only the "instructions" of a program and no other. It is equivalent to another processor, for instance Disk processor, Graphic processor etc., just only with a different task. The correct name would have to be "instruction processor" but it is called shortly only "processor". We have Intel processor, PowerPC processor etc. but no one recall the term CPU, why ?. Because it is obsolete. Please does not to confuse the term "central" with the "main" meaning, that is the most important processor just only because execute the instructions that are the main function of a computer. I am a super expert in the computer field, mainly in multiprocessor e NUMA system with several patents (more than twenty: find: Ferruccio Zulian patent). I have collaborated with Olivetti, IBM, General Electric, Honeywell, Bull, AT&T, NCR during more than 30 years as computer architect with more a tens design systems. In wiki there are many not correct information written by no not expert people. Ferry24.Milan (talk) 19:37, 18 December 2014 (UTC)
- Hello! While your reasoning makes sense to a certain degree, changes you've introduced into the Central processing unit article would require at least one good reference. As you probably already know, Wikipedia doesn't allow original research, and content of the articles should be based on reliable sources. Please don't get me wrong, that isn't personal and means absolutely no disrespect – that's simply the way Wikipedia works.
- At the same time, I do remember "CPU" as a term and use it regularly; the actual meaning, which might be somewhat historical, should be clear to a wide audience. Also, if we stretch your rationale far enough, even the PC XT's 8088 chip shouldn't be called a CPU as it, for example, relies on the 8259A PIC for interrupt handling; XT's selection of graphics cards just takes that further. As another example, with that reasoning even the Commodore 64's 6510 can't be called a CPU, as it offloads majority of graphics and sound processing to VIC-II and SID chips. All that wouldn't make much sense, if you agree. — Dsimic (talk | contribs) 11:00, 19 December 2014 (UTC)
ECC memory
Hi!
I just read in Wikipedia about ECC memory. Under solutions it lists ECC memory and RAM parity memory. But I find the wording misleading, because the memory itself is not performing the ECC nor the parity algorithm. The memory only offers an extra-wide memory bus (typically 72 instead of 64 bits). The error detection and correction is in all cases a feature of the CPU / the memory controller which creates the parity bits and writes them to the extra-wide memory bus. Upon a READ, the controller receives the data including parity bits, verifies and corrects the data then continues it's processing of that data.
I think it is not clear enough on Wikipedia that ECC/parity are mainly microcontroller-features, just because of the wording "ECC memory", "Parity memory"
But in fact there is now new DRAM-memory on the market with 'on-chip integrated ECC error correction'. See http://www.intelligentmemory.com/ECC-DRAM/ . These ECC DRAMs really perform the complete algorithm inside the memory components on their own. They do not require any special microcontrollers with parity or ECC functionalities, nor an extra wide memory bus is required. Upon a WRITE to the ECC DRAMs, they generate parity-bits and store them separate from the data into an additional memory-area. On a READ, they logic on the ECC DRAMs performs the hamming algorithm and outputs verified&corrected data.
The interesting thing about these ECC DRAMs is that they are 100% compatible to JEDEC standard DRAM components. They can be used in any existing application on the market, no matter if the memory controller is having a 8, 16, 32 or 64 bit bus, and no matter if the controller has own features to handle ECC or parity.
I did not feel comfortable trying to change the Wikipedia entry as my mother-language is not English. Additionally, I work for a company that is distributing the products of Intelligent Memory and I really do not want the Wikipedia page to look like 'advertising'. Still, I am fascinated by the technology and find it worth mentioning. If you would like to work on some changes, I am ready to help and provide lots of input (how about a block diagram explaining the way 'on chip integrated ECC' works?). I am in the memory business since 23 years and can surely support to make some things a bit clearer / more correct.
Regards, Thorsten Wronski t.wronski@memphis.ag 80.156.59.106 (talk) 15:23, 22 December 2014 (UTC)
- Hello! Actually, various implementations and their differences are described in more detail in article's ECC memory § Implementations section, which mentions that some implementations depend on the memory controller to do the work, while some other implementations include the ECC logic as part of the ECC memory itself. Of course, the majority of contemporary ECC-enabled systems involve pretty much passive memory devices, at least when looking at the way ECC functionality is handled (buffering usually has nothing to do directly with ECC); an interesting exception is POWER8's Centaur, which puts a lot of logic onto memory modules.
- The link you've provided describes a really interesting technology, thank you for pointing it out – I've already included it into the article as a reference. The main benefit and a great thing, as far as I can see, is that it acts as a drop-in replacement for systems not supporting ECC memory in the first place. I'd like to expand its coverage a bit; for example, it would be especially interesting to know how does it interface with the rest of a system that doesn't support ECC memory natively, so the rate/count of detected and corrected memory errors is eventually available to the firmware and operating system? How does it handle uncorrectable errors?
- Looking forward to your reply. :) — Dsimic (talk | contribs) 00:23, 23 December 2014 (UTC)
- Hi! The ECC DRAM chip does not have a communication-pin for reporting errors, otherwise it wouldn't be a JEDEC-standard-compatible drop-in-replacement to conventional DRAM components any more. But it offers a 'passive' way to read out an error-flag through a special mode register. Unfortunately an error-flag can not tell you when, how often and at which address(es) the error(s) occured. All you get is a flag 0 or 1.
- We need to be careful with the definition of 'Uncorrectable errors'. A two or more bit error is uncorrectable by the normal 64/72 hamming code. But a two bit error is at least detectable with ECC algorithms. Now it depends on the exact usage of the hamming code. Most hamming codes can not see a difference between a corrected single bit error and a detected but uncorrected double bit error, same on the ECC DRAM.
- Thus, the error-flag could have various meanings:
- Error-Flag = 0 -> Either No Error happened or maybe there was a multi-bit error (2+ bits) which was not detectable
- Error-Flag = 1 -> Either a Corrected Error occurred or there was an uncorrected, but detected double-bit error
- Well, what does this help? In my opionion this does not provide any usuable feedback. We really need to think about the importantce of the ability of detecting - but not correcting - a double-bit error. Some statistics: Let us look at the statistical frequence of double-bit errors compared to a 'complete memory fail' (functional) or 'multi-bit-fail' and you will see what I mean...
- Assuming we talk about 1 Gigabit of data which is the typical memory-chip-capacity. That is 1 billion bits. The hamming code is able to correct 1 incorrect bit per every 64 bits. In 1 billion bits there are 16 million blocks of 64 bits. So in theory, a 1 Gigabit ECC DRAM could have 16 million correctable errors at a time without failing, as long as each bit-error is in a different 64 bit word. Or you could say that every 16 millionth bit-error might hit a 64 Bit word where another bit flipped before.
- DRAM bit-flips are rare cases. There are several statistics about their frequence, but finally it depends on many hard-to-evaluate factors. But even if we had a bit-flip in 1 Gigabit every day which the ECC DRAM corrects 'on the fly', the probability for an uncorrectable double-bit error in the same 64-bit-word would be 16 Million days = 43800 years. That is 384 Million hours or 3 FIT (failures-in-time).
- When you look into a reliability-report of any DRAMs (these documents are available from all DRAM-makers upon request), you will typically see a FIT-value of 11 or higher. Important to know: This FIT-value refers only to total functional fails/defects, and not about the sporadic/random single bit errors. If a DRAM is shown with a FIT of 11, it means it is expected to have 11 defective parts after a billion device hours.
- Now what I am trying to say: A 'total fail / defective chip' is about 4 times more likely than having an uncorrectable double-bit-error in an ECC DRAM. I do not dare to specify a FIT-value for single-bit-errors (which an ECC DRAM will correct, but let a conventional DRAM have a real error). The field-study of the University of Toronto named 'DRAM Error in the wild' is talking about 25000 to 70000 FIT of ECC-correctable single-bit errors PER MEGABIT. This would convert to 25 Million to 70 Million FIT per Gigabit. A shocking high number!
- Thus I think the importance of ECC focuses on correcting single-bit errors. Everything beyond this requires different methods to secure the continuous operation or safe shut-down of the application.
- Additionally, for high-reliability applications it is a good idea to do a 'memory scrubbing' on ECC memory periodically. Scrubbing means that the CPU uses it's idle-time to read from the DRAM and then writes back to the DRAM. This way single bit errors get corrected during the read and that corrected data is then written back to the DRAM. Since the majority of DRAM bit-errors are typically not permanent, scrubbing reduces the probability of 'a second bit-flip in the same 64 Bit word' extremely.
- I hope it was correct to 'Edit' the post to add my reply. I could not find a reply button anywhere. Regards, Thorsten 80.156.59.106 (talk) 14:33, 5 January 2015 (UTC)
- Thank you for a detailed overview! Though, as far as I can see from it, memory chips with integrated ECC functionality provide a very limited way for reporting their statuses back to the firmware or operating system. As we know, some organizations have policies that mandate replacement of ECC-enabled memory modules once their corrected error counts go over a defined limit, what makes the reporting a necessity. Also, some vendors, such as Apple if I'm not mistaken, even have warranty policies that allow ECC DIMMs to be replaced under warranty if they encounter more than a defined number of correctable errors over a defined period of time.
- However, I'd say that the memory chips with integrated ECC functionality aren't even made with the above mentioned applications in mind; instead, they're probably a good fit for embedded systems that have no hardware support for ECC memory – nobody is going to monitor such systems anyway. Though, I wonder how many manufacturers care about not having silent data corruption in CPEs they sell in high volumes?
- By the way, clicking "edit" to reply is exactly how Wikipedia works – unlike regular forums, talk pages provide absolutely no functionality specific to posting replies. :) — Dsimic (talk | contribs) 03:38, 6 January 2015 (UTC)
- The idea of these products has never been to replace a normal ECC method (through CPU and extra wide memory modules) by using ECC DRAMs. Instead, the idea was to make it possible to have ECC in applications where it was not supported at all before. Look at all the access controls, smart meters, routers, industrial PCs, automotive&avionics electronics, medical instruments, cash-registries and data-entry terminals, ticket machines, any kind of control boards, etc. These are often too small for memory modules with ECC and using ECC-capacble CPUs would also make them much too expensive. With ECC DRAMs they can be upgraded to an extreme stability.
- In automotive markets the manufacturers use conventional DRAM, just pretested according to the AEC-Q100 regulations. But this does not protect from single bit errors. You might have seen electronics in your car randomly malfunctioning, but working fine again when you restart the car. No testing can protect from memory errors, only ECC can. And how could anybody use 9 DRAM-chips or a memory module on a little camera module that is integrated into the cars mirror? There is just no space. Automotive manufacturers use multiple methods to at least make sure the applications get safely shut down upon an error, but it is very difficult to control. With ECC DRAM those effects would not even happen (for a 16 million times longer period).
- But let me repeat again what I wrote before: A totally defective DRAM is 4 times more likely to happen than an uncorrectable, but detectable double-bit error. And multi-bit (more than 2 bit) errors are not even detectable. Due to this, I see no need for detecting double bit errors.
- 'Not having any more visible single-bit errors' by using ECC improves the reliability of DRAMs by a factor of 16 Million. Even in the very extreme case of 1 bit-error per day, the DRAM will continue to work flawlessly for many thousands of years (by far longer than it's expected lifetime).
- Based on those factors, I do not see a reason why someone would want to get a feedback about corrected single bit errors as long as the system still works. And if the system fails, it was most-likely a total memory-fail, which is 4 times more likely to occur than a double-bit error. Both, the chip fail and double bit errors, will lead to a system-fail as they are uncorrectable and fatal, but fortunately EXTREMELY rare.
- I think you are right when you say a memory-module vendor will replace the module when the customer complains about seeing too many correctable errors. And yes, there is this difference from CPU-controlled ECC to DRAM with integrated ECC. The ECC DRAM can not pro-actively inform the CPU about a detected/corrected error. However, it is possible by reading out a flag.
- But please do not forget: It is a big milestone to add ECC functionalities at very low cost (no redesign necessary, no expensive CPU needed, no extra memory chips required) to ANY application, no matter what CPU is used, no matter how much space is on the board. Even a $50 WiFi-Router could be made as stable as a server at just a dollar or two more. Any HDD/SSD drive uses 1 DRAM Chip for Cache/Write Buffering and a bit-flip can cause data-corruption (in fact it does happen, I see it on our companies RAID), which would not happen with ECC DRAM.
- Technically it would not have been a big issue to add an Error-Pin to the ECC DRAM, but then the big complaint from all customers would be 'it is not compatible, we need to do a re-design to use it'.
- The FIT for correctable single-bit errors (according to the field study) might be as high 25 Million to 70 Million FIT (failures in time), while total fails count only 11 FIT and double-bit-errors count only 3 FIT. These numbers show that the key-factor is to eliminate single-bit errors. When these get corrected, the stability is 99.9% secured. 80.156.59.106 (talk) 08:26, 6 January 2015 (UTC)
- You're totally right, adding ECC memory functionality to otherwise incapable systems, without the need to modify their designs in any way, is a really, really great thing. However, as I've already noted above, the big question is how many manufacturers are willing to spend those extra few dollars? Please don't get me wrong, I love to see ECC memory in any equipment, but the fact is that profit margins for high-volume products are quite thin.
- Asking why would anyone want to have such feedback available is perfectly fine, and one of the reasons is that some companies tend to replace ECC DIMMs once they produce one or more uncorrectable errors. Here's a quote from the Google's DRAM study:
- In many production environments, including ours, a single uncorrectable error is considered serious enough to replace the dual in-line memory module (DIMM) that caused it.
- Perhaps the feedback for correctable errors might be freely ignored (though, personally, I love to have as much feedback available as possible), but uncorrectable errors should be clearly reported in some way. That's where your error flag comes into action, and it might be even better to see its transition to logical one only if an uncorrectable error is detected. In other words, if its "1" indicates that there are some errors, that isn't too usable, if you agree.
- Though, it all depends on where the memory with integrated ECC functionality is used; for example, even if it had full reporting capability, I doubt that car manufacturers would be quickly replacing ECUs with such memory due to a single uncorrectable error. Or maybe they would be replacing them – I can only theorize. :) — Dsimic (talk | contribs) 09:17, 6 January 2015 (UTC)
- The field-study is right, an uncorrectable error is serious enough to replace the DIMM. Any yes, it would be nice to see any uncorrectable errors to be reported. Since total DRAM fails are also 'uncorrectable' (as well as 3+ bit error), but are more likely than double bit errors, it would require completely different methods than ECC which can detect ANY error, no matter if the DRAM has a functional fail or multi bit error. ECC can impossibly do that. It would detect only double-bit errors, but before detecting those, 4 chips already had total functional fails or multi-bit errors that were not detectable by ECC! (because of the theory that the FIT-value for total functional fails is 4 times higher than for double-bit-flips)
- The capabilities of a standard 64/72 ECC hamming code are limited. If a total fail or multi-bit fail is more likely than a double-bit fail, I do not see a sense in being able to detect only the double bit fails. Either you find a way to catch ALL uncorrectable errors or you accept that there is a very very little risk of failing due to such rare uncorrectable errors. The double bit detection alone is not very helpful. In case of a double bit error, the system will malfunction or crash or perform an automatic reset anyway. And what if it just malfunctions or crashes due to multi-bit or functional fail errors without detection? The information 'system malfunctioned or crashed' is the same.
- Until now, all manufacturers use standard DRAMs which do have a bit-flip from time to time. Either they use 9 or 18 Chips per rank in a 72 bit wide memory bus to do ECC by the CPU like on servers, or they have no protection at all.
- Automotive applications can not use ECC, they are typically too small to fit so many DRAM chips into them. Any automotive electronics I know is using just one or two DRAMs with a 16 or 32 bit memory-bus to the CPU. There is no ECC. They calculate some of the important data multiple times to compare them and detect an error. This is good, but slow. Additionally the CPU will jump to an interrupt routine when an illegal command is found to be executed. Such illegal commands can happen when there is a bit flip in the program code. You might have seen that when your navigation or multimedia system suddenly resetted itself. Unfortunately not every bit-flip in the program code results in an illegal command, it can also become another legal command causing system malfunction. The possibilities to secure the stable operation of the electronics without ECC are limited. The automotive industry welcomes any improvement, and ECC DRAM will clearly relax and optimize the activity of other functional-safety methods used in the car-electronics. This does not mean they do not need them any more, but the frequence of their activity is getting reduced a lot and they become a lot safer (taking the example of a legal command changing into another legal command that results in malfunction...this won't happen with ECC!).
- For consumer electronics and price-sensitivity, I agree with you partially. There are thousands of customers having to reset their electronics periodically. For example just Google for 'Router hang' or 'Router crash' and you know what I mean. It is also a question of marketing and bringing the awareness to the people that they can have something more stable at a few dollars more.
- Any manufacturer of practically anything is trying to announce something 'new and better' to the market to present their products being superior. Look at how many new hair-shampoos are fighting each other claiming to have the best results by new ingredients with funny names. ECC in a router or in a HDD/SSD can be promoted a lot better, because ECC is well-known, the people really know the issues and many will happily pay a few dollars more to have a stable product. If each chip costs $1.50 more (for example) and most router just use ONE piece, then the manufacturers cost will increase by $1.50, but he can sell the product to end customers at maybe $5 more. This is not much compared to the massive price difference between electronics without or with ECC. Example: A desktop-PC costs $299, but a server with ECC at least 10 times more. Still the people buy a real server and do not use a standard PC. And if you look at the difference, there is not that much. The main reason for the 'better stability of the server' is in fact the ECC. So in the PC vs Server market the people even realized they have to pay thousands of dollars more to get reliability. Paying $5 more for a router with ECC is peanuts. BUT it requires marketing of these products and then the manufacturer will surely be able to make extra money and gain market share from their competitors.80.156.59.106 (talk) 12:24, 6 January 2015 (UTC)
- Well, uncorrectable double-bit errors are rare, and undetectable triple-bit errors are even more rare, but IMHO that doesn't justify a blanket statement that detectable double-bit errors shouldn't be reported at all just because it's more likely that a memory chip is going to fail completely. A total failure of a hardware component in most cases isn't a cause for silent data corruption, and the primary goal of ECC memory is to prevent silent data corruption. Sure thing, it would be great to also cover silent corruption involving more than two bits, but that kind of corruption is predictably very rare.
- Regarding the automotive applications and space constraints, I'd say that it also depends on a particular control unit. For example, engine and transmission control units, as well as instrument clusters and GPS navigation units, are usually large enough to house more than a few memory chips, and they're anyway much more important than some random in-car gadgetry. Heck, some GPS navigation units even have built-in 2.5-inch hard disk drives, and those mechanical devices are huge in comparison to a full-size SO-CDIMM, for example. :)
- I agree that some marketing around more stable products that contain ECC memory could be a huge selling point, but please let's remember that many of the "reset your router" scenarios are due to software bugs and sloppy firmware and not because of cosmic rays messing up memory cells. :) For example, I used to have ordinary PCs with no ECC memory serving as busy Linux servers, and some of them had 1+ year uptimes with absolutely zero issues (others needed to be rebooted for kernel-related security updates to be applied). — Dsimic (talk | contribs) 18:32, 6 January 2015 (UTC)
- Hi! First of all I would like to say: I like this discussion. Thanks for your time for it!
- A detected double-bit error still has not been corrected. Very immediate action has to be taken like a Reboot. This is similar to Rebooting on an illegal command, which most CPUs can do. If it is in the data, the data gets lost due to the reboot. But yes, the more reporting you get, the better, I totally agree. I am just trying to show up that having double bit detection is not a major improvement.
- I know the memory-demands of Conti, Delphi, Harman, etc. In none of their applications they use ECC and in most they have only one or two DRAMs. There is ONE navigation system using 8 pcs 2Gb DRAMs, so also this is without ECC. I can't say why they did not just put 9 Chips into it. Maybe the CPU does not support it. I talked a lot to people designing driver-assistance systems which are able to keep you on the right lane, detect obstacles on the road, read traffic signs, etc. They told me a lot about the functional-safety methods they currently use and that they only use one or two DRAMs, but they all said they are interested in DRAM with integrated ECC. Some of them had similar questions and concerns as you have, but all agree that having ECC with single-bit correction is MUCH better than using todays conventional DRAMs which have no protection at all.
- You could also understand the ECC DRAM as a super-reliable-DRAM, million times better than the hardest tested conventional DRAM, but 100% compatible to a conventional DRAM.
- On the router-fails, I do not agree it is software bugs, as a router executes the same (fairly small) software-routines again and again over hours, days and weeks. A PC has much more complex software and a full operating system with many processes running. It depends how you drive the PC. If you run different programs, surf the web, download and install, open/close programs&files, etc, then at some point it becomes slower, eats up your memory or might hang. There sure are some bugs in complex software like Windows, maybe some less on Linux.
- If you read the field-study of the University of Toronto, you will find that not every memory module failed! Only 8% of the DIMMs needed to be replaced. Thus some memories seems to work well for a very long time without troubles, while others show more or less bit-flips.
- Also, Conclusion 7 of the field study says that the majority of errors are not soft-errors (caused by external disturbance like cosmic rays), but hard errors. Hard Errors are for example 'weak-cells'. They are not permanent in most cases. When a DRAM is intensively used, it will degradate over time and sporadically show a bit-flip. You can see this from the charts in the field study, where the error-rate increases further and further over time. This speaks against cosmic rays, but clearly for a degratation-process. Degradation is a well-known problem of DRAMs. After some time of operation, after soldering processes or even after a longer flight in an airplane, the isolations of the cells get reduced, cell-leakage increases and the data retention-time drops. The cell loses its content before the next refresh cycle sets it back. This appears to be as random as a soft-error, but when watching it carefully, it can be found that always the same cells have this problem, which is a clear sign that it is not caused by an external influence. In many cases the problem only appear with specific data-patterns written to the DRAM, showing that the cells are linked to each other (bit-lines/word-lines, etc) and if one cell gets charged, the neighbor one suddenly also gets part of that charge (due to leakage) changing its binary content resulting in a single-bit-error.
- When talking to DRAM test engineers who write the test-programs for wafer-level testing, and for package-level core-, speed- and burn-in-testing, you will always hear that their biggest challenge is to find data-patterns and routines to stress the DRAMs in a way that they show these weaknesses and interferences. During the tests, they always find a handful of single-bit errors which they can repair by e-fusing, but everybody is aware that it is impossible to test in 'every possible way', thus a certain risk for single-bit errors is unavoidable. And unfortunately, those often appear only after some time of operation. The more stress, the faster they appear.
- I have a nice report here for a test which was performed on conventional DRAMs. They have been heated up to 85°C, then 95°C, 105°C, 115°C up to 125°C and at the same time the refresh rate was reduced to simulate the degradation. Note: The tested DRAMs were brandnew, never soldered or used, so not degradated. The test was not meant to accelerate degradation (which is difficult anyway), but to show what errors are to be expected IF they degradate.
- At the worst case scenario of 125°C and 128ms Refresh-Rate, about 1000 to 8000 bit-flips were observerd in every single test-run on all tested DRAMs. Not even one double-bit error has ever appeared. But at a bit better conditions, some RAMs showed no errors at all, while others had hundreds. This shows that even after the manufacturers testing, there are still DRAMs that are more likely to have issues than others. And it explains that not every DRAM will have errors after some time, but some do, and the percentage is too high to ignore the need for ECC. 80.156.59.106 (talk) 08:16, 7 January 2015 (UTC)
- Thank you very much, I also really enjoy our discussion! :)
- I agree that having double-bit error detections isn't an improvement by itself, but it allows some kind of damage control, so to speak. In general, such corruptions happen very rarely, but at least someone can know that something went wrong and see what to do about it. Of course, halting or rebooting in case of a detected uncorrectable error might even cause bigger troubles than simply ignoring the corruption – let's just think of complex file systems interrupted in the middle of their busy operation.
- Regarding the routers and Wi-Fi access points, many of them actually run Linux, so reduced complexity of their software simply isn't to be counted on. In other words, those boxes are small but quite complex on the inside. :) The main trouble with the stability of embedded systems running Linux comes from the fact that manufacturers usually opt for their own hardware designs with no existing community ports of the Linux kernel; they do the porting themselves, or contract it to someone else, and that results in a much lower quality of the port than what a community-developed port could provide. Why? Because manufacturers have deadlines, tight schedules, not so much enthusiasm, ;) and they end up with a limited amount of testing before releasing a product (when compared to having tens of thousands of people doing the testing in vastly different environments).
- Of course, no matter how software/firmware is well-written or not, DRAM bit flips contribute a lot to the overall stability. That's even more important and evident as the amounts of installed RAM increase: not so many years ago, PCs with 128 MB of RAM were common, and nowadays many consumer-level embedded devices have that much RAM. Contemporary PCs went to 8 GB of RAM as standard, the amount of RAM that leads to about one bit flip per week, per field studies. To me, that's a serious thing that turns ECC memory into a necessity.
- When looking at a big picture, having no ECC functionality is like gambling – things might work just fine, but not necessarily. Speaking of cosmic rays, I'd say that they serve as a "fallback" description for something we actually don't understand. :) Just as you've described it, many of the bit flips come from undetected manufacturing defects, manufacturing stresses, or simply aging of a device. With ever increasing amounts of RAM per device, and ever increasing complexity of the devices, the issues just grow in size.
- What's also really interesting is why consumer-grade PCs still remain without the ECC memory? It's true that profit margins are also quite thin in the PC business, but still, 12–15% more expensive RAM (effectively, if we disregard price inflation due to low volumes) simply doesn't look like a viable explanation for the situation. And, even more interestingly, why there are no laptops with ECC memory? — Dsimic (talk | contribs) 09:20, 7 January 2015 (UTC)
- I am still of the opinion that the 'damage control' is not the job of ECC as it's damage-control possibilities are too limited (only double bit error detection). But ECC is fantastic to improve overall reliability, as it is a fact that 99.9% of all DRAM errors are just single-bit-fails.
- Really reliable damage control can only be safely achieved by triple-redundant systems. Three CPUs with three separate memories execute the same code and do separate calculations. If one is different from the other two or if one of them hangs, this one must be 'bad'. The method of rebooting upon an illegal program-code only has a small chance to become active, as for example a JUMP-instruction could just be jumping to a wrong address due to a bit error, or the JUMP becomes an ADD command or other legal command. Only if the command-code does not exist, the illegal-command interrupt-routine would help.
- On the routers: Maybe they run Linux, but how much of the program-code RAM is being used? Take a PC and only work with one and the same program in the same way for a long time, for example with WORD. The program takes up maybe 2GB of your memory, but if you just type some text, you use by far less than 1% of the total WORD program code. You would not even notice if bit-errors hit into the other 99% of the code. Same thing when using a PC as a server...you only run maybe a few MB of program code again and again, although you have loaded Gigabytes of program-code into the RAM. You also use very very little parts of the total OS. But if you use your PC for lots of things like Excel, Word, Internet, other programs and try all the functions, etc, then your percentage of code-usage becomes a lot larger and the visibility of running into a bit-flip that causes malfunction or crash increases heavily.
- Most routers (you can Google for pictures of the PCBs and see it) have just 16MB to 64MB of RAM. I'd say the the code in the RAM is loaded much more effectively than in a PC. Unnecessary routines and OS-parts have been elimiated to make the code fit into the small memory. However, routers also have lots of menus, features and settings. During normal operation of the router the effectively used code for just transferring data in and out to/from the web is again just a small portion of something between 1% and 5%.
- With 1% effective RAM usage, only every 100th bit-flip causes visible trouble. I have three (different) routers at home, two used as repeaters. Two of the routers need a Reset about every 3 months, although I do regular software updates. And interesting enough the errors on both are different every time. Sometimes it does not accept my WiFi password and asks me to re-enter (which does not help=, sometimes it just does not connect although every entry in the menus looks fine, next time one of the submenus does not appear, another time I can not connect to it through it's IP at all, although it still lets me into the internet, etc etc. It is really weird! When I googled if other people have similar experiences, I noticed that the web is full with millions of entries about router hangs and random functional fails for all brands of routers. So it is not limited to one router with one specific software.
- One day I opened the routers and noticed the antenna cables are lose-wired going right over the DRAM....I assume here we really can talk about soft-errors!
- The same problem happens on HDD/SSD drives. There is just a 512Mbit (64MB) DRAM on it which is mainly used for Cache&Write Buffering as well as for running the (very small) firmware. The SMART features of the firmware add a cyclic CRC checksum to the data (only the data, not the firmware) passing through the RAM and in the SMART-value IOEDC End-To-End Error you can then retrieve the count of errors. An error hitting the data in the cache will increase the number of those End-To-End errors without repairing them (file on drive damaged), but a hit into the firmware can cause worse malfunctions. And in fact, I sometimes experience that I save a file to the drive and when trying to load it again it says the file is corrupted. This even happens on our big company raid-system. If it was a bit-error on the magnetic media, the drive normally tries to read multiple times before it reports an error. And re-trying then sometimes helps. But what I experience when I have a bad file is an immediate 'file corrupted' error that can not be corrected by re-trying. Thus I think the write-buffer (DRAM) had a bit-flip when writing the file to the drive and the data got incorrectly written to the media. Well, I don't really know, I just guess. But I am still very sure that many business customers would pay $5 more for Enterprise-HDD drives having ECC on the DRAM. And the HDD manufacturer could also 'proudly present his new innovation' and take away market-shares from their competitors, publish press-releases, get magazines to review it, etc. If the manufacturers like, they can also offer their drives with and without ECC DRAM at two different prices. In this case the customers will question the difference, read into it and then decide 'do I want the increased safety or not?'. Many will!
- Do you know the "Intel Inside" sticker on many computers? There is an "I'M ECC PROTECTED" sticker/badge/logo which Intelligent Memory offers to customers using their DRAMs. I think it is a good marketing tool to put onto the end-products, product websites, brochures, advertisings, etc to show the end-customers what they get for the extra-money! If I could have your e-mail address, I can e-mail you some things. I do not want to type mine here, but if you e-mail to sales@memphis.ag and put into the subject 'Att. Thorsten', I will get it and reply to you. 80.156.59.106 (talk) 10:31, 7 January 2015 (UTC)
- Sorry, perhaps I haven't expressed myself clearly enough when referring to "damage control"; what I also wanted to say is that ECC's protection against silent DRAM corruption (that is, one-bit errors) is the best kind of damage control it provides. Handling of uncorrectable double-bit errors is just a continuation of that.
- As you've described it, usage of RAM contributes largely to how a computer is going to react to a silent DRAM corruption. Speaking of Linux running on embedded systems, it's true that Wi-Fi APs or routers don't use a lot of RAM, but NAS appliances, as another example, use everything that's available for caching and various file system-related operations. Having a flipped bit in NAS appliances is even more dangerous, as that has the potential to cause file system corruption and loss of user data. Sure thing, the amount of RAM in embedded devices depends on what they're used for, so a Wi-Fi AP might run Linux just fine with as low as 16 MB of RAM, while a NAS appliance needs more RAM (they usually have around 256 MB).
- As far as I know, end-to-end data protection doesn't exist in consumer-grade SATA HDDs; that's reserved for the enterprise segment and SAS HDDs. That's the reason why there are advanced file systems, such as Btrfs and ZFS, which implement end-to-end data protection on their own, by calculating and storing checkums of data and metadata. However, file corruption issues you've experienced sound quite uncommon to me – are you sure that the hardware you're using isn't flaky? I've seen such random corruption only on some flaky hardware. For other issues related to HDDs, you might want to have a look at unrecoverable read errors; back at the time I've compiled a good summary there. — Dsimic (talk | contribs) 11:16, 7 January 2015 (UTC)
- Well, a single bit flip here and there is not a sign of a damaged DRAM for me. It just happens, either due to external disturbance or a cell weakness which only shows up with certain patterns of data. To a normal DRAM without ECC it is an 'effect', not a 'defect', but still the effect can cause a damage. However, such effect can typically not be repaired by replacing the RAM, as the next RAM will most-likely also see such effect every now and then.
- As my point of view is 'single bit errors happen, they are not a sign of defect, we can't avoid them', I see ECC being mandatory for system stability, but it is nothing I need to count to evaluate if the DRAM is bad. DRAMs just tend to have those hiccups, we just need ECC to cover them, but - depending on the safety level required - we can hardly evaluate the system-stability by getting informed when they happen. If someone puts his cellphone on the electronic device, there might suddenly be an increased number of bit-flips in the device. As soon as he takes it away, the issues are gone. Is this already a sign for a DRAM of the device being bad? I think the DRAM has just gotten into a temporary critical environment. Same in a car... park the car in the sun, the inside mirror gets over 100 degrees hot, the DRAM in the camera or distance-sensor gets some bit errors. But when it cools down, it is fine again. The DRAM is not damaged, but it was under temporary stress and ECC can save it! And again the same under radiation, high data-traffic between DRAM&CPU, etc.
- The risk of 'errors adding up to result in an uncorrectable double bit error' is extremely little and can be avoided by scrubbing during CPU Idle-Time.
- Yes, especially Enterprise drives have the SMART features. Here in the company we use only Enterprise class SCSI drives, where the price is 5 times higher than for a consumer drive. Our employees save and open hundreds to thousands of files every day. It does not happen very often, but it does happen that files become unreadable for unknown reason. We can read out the SMART parameters of the drives and can see some IOEDC (Input-Ouput Error DETECTION Code) end to end errors occured, but have no information on when they happened nor which file is affected, so I can only guess there is a relation to those files which we found becoming corrupted. Per the WikiPedia documentation of the SMART parameter for IOEDC : 'This attribute is a part of Hewlett-Packard's SMART IV technology, as well as part of other vendors' IO Error Detection and Correction schemas, and it contains a count of parity errors which occur in the data path to the media via the drive's cache RAM. 80.156.59.106 (talk) 11:50, 7 January 2015 (UTC)
Totally agreed, as the purpose of ECC memory is to recover from singe-bit errors. If having single-bit errors from time to time would be seen as a sign of bad DRAM, that would mean it is possible to manufacture perfect DRAM that would never ever encounter bit flips – and as we know, that's pretty much impossible.
Everything shows that ECC DRAM is they way to go, either through native hardware support or by using DRAM chips with integrated ECC functionality. Hopefully more equipment manufacturers will share the same point of view. :) Do you, maybe, have any insights why there aren't any laptops with ECC memory? That's very strange, and I'd be extremely happy to pay even a significant price premium for such a laptop.
The silent (or not so silent) corruption you're experiencing in data storage is really interesting. Does the manufacturer of storage system you're using have anything to say? I wonder how would Btrfs or ZFS perform in such an environment... Is the overall storage capacity and number of HDDs something you'd be comfortable with sharing here? — Dsimic (talk | contribs) 07:44, 8 January 2015 (UTC)
- The right people at the manufaturers of storage systems are difficult to find. They have an endless number of employees. I was hoping that a bit more detail could appear on Wikipedia about the ECC DRAM technology, so more potential customers find it and more 'awareness' is being created. If you have any further ideas on that, I would really appreciate any kind of activity that helps making the world aware of this technology. I think it really fits to each and every industrial, automotive, medical, military product, no matter if the application is computing, networking, telecommunication, storage, control, measurement, etc, because all of these applications require to be 'better than a normal PC' and should run perfectly smoothly without ever requiring to be rebooted/resetted.
- Laptops with ECC are really rare. Only some rugged military laptops might have it. BUT: With 16 Chips 1Gbit ECC DRAMs we can build 2GB SO-DIMM modules, where each chip has ECC. Since 8 chips are per memory-bank, you get eight times ECC in parallel! This is a lot stronger than having a 72 bit bus with just one time ECC over all bits. If 2GB modules are big enough for you, then we can do that. 80.156.59.106 (talk) 11:47, 8 January 2015 (UTC)
- You're right, reaching engineering people is almost an impossible mission in larger companies. Could you, please, send me a few links to data sheets for the DRAM chips with integrated ECC functionality, their specifications, related promotional materials, etc.? Of course, all that needs to be publicly accessible so it can serve as references. After reviewing all that, I'll see how to add more content into already existing articles – you're right that such a technology deserves better coverage.
- As you've pointed it out, such SO-DIMMs would be even better than regular SO-CDIMMs by offering "finer grained" ECC protection. Does your company already sell such DDR3 SO-DIMM modules in small quantities? If so, what are the prices compared to same-capacity standard non-ECC SO-DIMMs? Also, I was wondering whether your company sells small/sample quantities of DRAM chips? I have a few embedded Linux devices (Wi-Fi access points, small NAS appliances, etc.) that would benefit from replacing their factory-soldered "plain" DRAM chips. — Dsimic (talk | contribs) 22:06, 8 January 2015 (UTC)
- Hi Dragan! FYI, a lot of the info and datasheets you ask for is visible and downloadable at www.intelligentmemory.com and on the FAQ pages, etc, but I have even more documents I can send. But how can I send you that? I can hardly include it here onto the talk-page.
- And yes, we do build such modules and can also make them based on ECC DRAMs. I can tell you pricing by email, but I do not have your email address! 80.156.59.106 (talk) 07:56, 9 January 2015 (UTC)
- Please let me dig through the documentation available on intelligentmemory.com in the next few days, and I'll let you know if more would be required. Basically, all that would be used as references needs to be publicly accessible on some web server; I could host some files for you, but it would be much better if you could host them somehow on your company's website (perhaps you have some means to make more files downloadable through the CMS you're using, or maybe by uploading them manually).
- The availability of such SO-DIMM modules is a great thing, thank you! What about individual DRAM chips in small/sample quantities, for replacing DRAM chips soldered in embedded devices such as Wi-Fi access points? Sure thing, I'd provide specs of the currently soldered DRAM chips. I'll shoot you an email to t.wronski@memphis.ag in the next few days, or you could open an account here on Wikipedia and use the "Email this user" functionality that's available on this page for registered users. — Dsimic (talk | contribs) 22:25, 9 January 2015 (UTC)
- Individual DRAM chips in small/sample quantities are also readily available in stock. Just let me know what you need. I hope you have a BGA soldering station to replace the parts. After replacing the RAM, try and heat up the ECC DRAM or disturb it with an antenna or in any other way. You will see that you can't get it to fail unless you use brute force.
- I don't think I need a Wikipedia account. If required, I can put any additional documents into Dropbox or something like that. — Preceding unsigned comment added by 80.156.59.106 (talk) 12:50, 13 January 2015 (UTC)
- That's awesome, and I was hoping to be able to outsource BGA soldering to some local shops; of course, I need to verify first whether that kind of work is actually doable locally. By the way, I already went through one part of the documentation available on intelligentmemory.com and will come back soon with an update. — Dsimic (talk | contribs) 01:28, 14 January 2015 (UTC)
- Some new links:
- http://embedded-computing.com/guest-blogs/why-ecc-matters-in-embedded-design/
- http://www.electronics-eetimes.com/en/dram-chips-integrate-error-correcting-code.html?cmp_id=7&news_id=222922892#
- And did you read the product-brief? Here is the link:
- http://www.intelligentmemory.com/fileadmin/download/PB_IM_ECC_DRAM.pdf
- 80.156.59.106 (talk) 08:37, 15 January 2015 (UTC)
- Thanks, those are good links, and I haven't read this product brief before. I've also considered whether Intelligent Memory would be notable enough for a separate article; please see WP:NOTE for Wikipedia's notability requirements. Unfortunately, running a Google search doesn't yield a large coverage in form of potential reliable sources, some of which are these:
- http://embedded-computing.com/news/intelligent-code-ecc-functionality/ (pretty much the same as one of the links you've provided, but not presented as a blog entry)
- http://www.anandtech.com/show/7742/im-intelligent-memory-to-release-16gb-unregistered-ddr3-modules
- http://www.tweaktown.com/reviews/6817/i-m-intelligent-memory-16gb-ddr3-udimm-memory-review/index.html
- http://www.guru3d.com/news-story/im-intelligent-memory-8-gigabit-ddr3-and-16-gb-modules.html
- Are there any other secondary sources, third-party reviews, etc. available, which a Google search was unable to find? Having only a few more would be just fine. — Dsimic (talk | contribs) 09:09, 15 January 2015 (UTC)
- Thanks, those are good links, and I haven't read this product brief before. I've also considered whether Intelligent Memory would be notable enough for a separate article; please see WP:NOTE for Wikipedia's notability requirements. Unfortunately, running a Google search doesn't yield a large coverage in form of potential reliable sources, some of which are these:
- It seems you found several older press-releases about the world's first 8 Gigabit DDR3 chips which were designed by Intelligent Memory. These chips make it possible to build unbuffered DIMMs and SO-DIMMs up to 16 Gigabyte, while ALL other manufacturers only have such modules up to 8 Gigabyte, because they only have maximum 4 Gigabit DDR3 components. Intelligent Memory uses their own (patent pending) method to make 8 Gigabit chips without having to wait for new manufacturing-technologies like 25nm. A 25nm DRAM manufacturing process would allow to put 8 Gigabit of memory onto a single die, but such processes cost billions of dollars and are about to go into mass production only by this year. Intelligent Memory thought "why wait? why spend so much money?" and invented a very unique method to use two conventional and readilty available 4Gb dies made in 30m process, interconnect them in a really tricky&specific way and put them into one chip-package. The fnal product looks/acts/works as if it was a monolithic 8 Gigabit chip. The very first samples were made in 2013, which is 2 years earlier than the big memory-manufacturers are able to release their 8 Gigabit memories in 25nm.
- And even more interesting: As soon as the big manufacturers have 25nm monolithic 8 Gigabit DRAM components (for example in DDR4), Intelligent Memory can take their technology to make 16 Gigabit chips from these! It would take at least another 5 years before other manufacturers can do the same by another process shrink as they would require processes smaller than 20nm to put 16 Gigabit onto a monolithic chip.
- While this technology of IM is also very interesting, it it not related to the topic of "ECC logic integrated into the DRAM" which we are dicussing here.
- The ECC DRAMs have been officially published and released on the Memphis booth at the Electronica show in November this year. News release: http://www.memphis.ag/fileadmin/newsroom/newsletter/Archiv/2014/Memphis_1410.html
- Also please take a look into this folder please: http://www.intelligentmemory.com/download/
- And I would like to refer to the FAQs where you find many questions/answers about ECC DRAMs: http://www.intelligentmemory.com/faq/
- I posted a comment about ECC DRAM on this page: http://thememoryguy.com/memory-issues-in-space-medical-applications/
- Another forum posting:http://www.tomshardware.co.uk/forum/id-2472284/hdds-ssds-issues.html
- But I know, there is a LOT more activity to be done to create an awareness for the ECC DRAM product series, for the simplicity of upgrading 'anything' to have ECC, but also for the 'need to have ECC' especially on all the industrial applications or anything that should run 24/7 like routers, HDDs, SSDs, access controls, Smart-Meters, POS systems, industrial controls, surveillance cameras, ATM machines, robot-controls, traffic-systems, networking devices, automation-systems, medical, military, automotive, etc.
- When you look at any electronics device, even those of which the manufacturers say they would be industrial, rugged, robust, high quality, reliable, stable, etc, you will rarely find ECC being used. The only exception is Servers, where people pay 10-20 times the price of a PC.
- Talking to the manufacturers of such products on the one hand creates a certain interest, but they do not even want to pay $1 more as they think they can't get that money back when selling and they would not be competetive any more.
- I am not expecting that a manufacturer of a settop box or tablet-PC wants ECC, but I am convinced that all those above mentioned electronics should at least match the quality of a server. The customers buy those products and pay a high price because they trust in their reliability, which can impossibly be guaranteed without ECC.
- If a manufacturer of such devices tells me 'we have no problems reported by customers and get no returns', I say 'Do you return your PC or Smartphone when it crashes and works again after a Reset?'. The big misunderstanding is that bit-flips are not permanent defects leading to an RMA, but they are randomly appearing and non-repeatable effects which customers do not want to have when buying a professional industrial electronics device.
- I am 100% convinced that the end-customers select the product they buy not only by price, but by reputation of the manufacturers brand/products for reliability, features, functions.
- If the manufactures add the ECC functionality for their products and promote it to the world, do press releases, point out the reliability features on the website and brochures, maybe let magazines review the product, then this manufacturer will become a market&technology leader. Customers buying such products will have to decide if they buy from company A) at lower price without ECC or from company B) with the 'server grade reliability by ECC' at a very little higher price. I am also sure that the expression 'ECC' is familiar to everybody buying electronics, but electronic-magazines can also be pushed to write more articles about its importance.
- Well, there is a lot to do to change the thinking. 80.156.59.106 (talk) 10:56, 15 January 2015 (UTC)
- Sure thing, I didn't mean to imply that integrated ECC and higher-density DRAM chips are directly related, but if Intelligent Memory would be created as a separate article, all aspects and products would have to be described there.
- Speaking of references for the separate article, this one would be good as it isn't a primary source; roughly speaking, all content residing on a manufacturer's website is considered as primary sources. In a few words, articles need secondary sources as that's how Wikipedia works; please see WP:USEPRIMARY for more information. Also, forum posts unfortunately can't be used as references.
- Please don't get me wrong, but I've been convinced that ECC memory is the way to go long, long time ago. :) That's why I'm now considering the creation of a separate Intelligent Memory article, which might help in increasing the overall awareness of the necessity for ECC memory. And for that article, we'd need a few more secondary sources that describe integrated-ECC DRAM as one of the IM's products. — Dsimic (talk | contribs) 11:41, 15 January 2015 (UTC)
- Yes, we need more people to talk about it, then there will be more secondary sources talking about it. All I can do is post into forums. To make others talk about the product and to write articles, it requires awareness of the product. Hen and egg problem. A really good article is this one that I just commented on http://www.zdnet.com/article/flipping-dram-bits-maliciously/#comments. 80.156.59.106 (talk) 12:28, 15 January 2015 (UTC)
- You're right, that one is a very good article. Speaking of secondary sources for IM's integrated-ECC products, may I suggest that you donate a few sets of integrated-ECC DIMMs and SO-DIMMs to the guys over there at phoronix.com? I'm sure they'll be more than happy to write a good article on their website, which is highly respected. Moreover, I'm sure they would use and mention those memory modules while creating more than a few articles later, for example when they test new models of motherboards or laptops so compatibility and performance can be assured. — Dsimic (talk | contribs) 12:39, 15 January 2015 (UTC)
- Just to make it clear, I have absolutely no affiliation with phoronix.com. — Dsimic (talk | contribs) 12:56, 15 January 2015 (UTC)
I don't mind sending out samples to them, but Phoronix is very much related to standard comsumer PC hardware, while the ECC DRAM makes most sense in the area of industrial, military, medical, automotive, avionics, networking and other electronic devices which use DRAM chips rather than modules. However, anything that helps creating an awareness will be fully supported by me. Do you know the people there and can brief them a bit and then ask them to contact me? Otherwise it becomes a 'blind call' which is less effective.
And if you have ideas for industrial markets, let me know as well. I like the Wikipedia idea generally, but it has to be carefully created in a way that 1) people searching for ECC technologies find it and 2) it does not appear as a promotion.
It could fit well as a new point 5.14 at http://en.wikipedia.org/wiki/Dynamic_random-access_memory and also mentioned in point 6 of the same entry. What do you think?
And it could fit into http://en.wikipedia.org/wiki/Hamming_code under point 5 ("see also") and point 7 (references). Maybe even a point "implementations" could be added referring to integrated ECC on DRAM by Intelligent Memory as well as to integrated ECC on SRAM memory by Cypress (they have done it for some of their SRAMs. Let me know if you need the link)
Do you dare to add/modify these Wikipedia entries? 80.156.59.106 (talk) 13:11, 15 January 2015 (UTC)
- You're right that Phoronix primarily deals with consumer-grade hardware, but many people who read their articles also work or deal with embedded devices. That way, starting the "buzz" in the consumer market should have a potential for spreading it much further. Also, I'd bet that many people want ECC memory for their laptops, but they have no idea that IM has a very good solution in that field; that's where Phoronix would fit the bill extremely well.
- Or, maybe you could buy a few popular Wi-Fi-enabled embedded devices that run Linux, replace their DRAM chips with IM's integrated-ECC chips, and send them off to Phoronix for a long-term reliability testing. Or, even better, send a few dozens of such modified embedded devices (possibly not all of the same device type) off to the developers at openwrt.org for another round of long-term reliability testing. Over time, that should almost surely create a snowball effect.
- I don't know the Phoronix or OpenWrt people, but I would be wiling to contact them – effectively being the one who makes blind calls and does the preparation for you. :) I'd also ask them which exact embedded devices or memory modules they would prefer to receive, so we make the whole thing as effective and productive as possible. Would you find something like that acceptable?
- Also, I hope that you might be willing to donate another few ECC-modified embedded devices to random Linux kernel developers that seek for them for various development purposes. They all perform reliability testing as well, and all "buzzing" should sum up over time. Unfortunately, I can't make a list of such developers right off the bat, but I stumble upon them from time to time; I'd also be willing to contact them and do the briefing/preparation – if you'd find something like that acceptable, of course.
- Speaking about expanding those Wikipedia articles – sure thing, I'm willing to do that, but IMHO it would be much better to create Intelligent Memory as a separate article first and link it from other articles (with brief context-supporting summaries, of course). That way, information wouldn't be duplicated around, and there would be a central place in which interested readers would be able to find a much better overview than it would be possible by just expanding other articles. Of course, nothing is allowed to look or sound like an advertisement, simply because that isn't the spirit of Wikipedia; also, that's strictly forbidden by the WP:NOTADVERTISING guideline. — Dsimic (talk | contribs) 14:30, 15 January 2015 (UTC)
- Replacing chips on WiFi Routers is not easy. It requires BGA soldering systems for that. It would then require to accelerate the bit-flips by radiation, heat or other disturbances. Not easy.
- Whenever Phoronix, OpenWrt or any others are interested to test the components or modules, I will be ready to sample. Eventually it will be done by 'loan' or if the value is not too high it will be just free samples. So please feel free to get in touch with some people or companies.
- Electronics magazines are also a good place, but they can just report, not test. Companies making routers, smart-meters or other electronics are very good targets, but they will not write reviews.
- That said, I am still thinking that the two WikiPedia entries I mentioned in my last message are a perfect place for the information in a brief way, but having it visible to a lot of people. The seperate Intelligent Memory page can be set up later, when there are more resources. 80.156.59.106 (talk) 07:31, 16 January 2015 (UTC)
- You're right that BGA (re)soldering is time-consuming and complicated. However, I don't see an easier way to give people some embedded devices they can use to test things out, and write or talk about them later. That said, an investment into BGA soldering equipment, or the cost to outsorce it to somebody else, could be seen as an investment into advertising – and, from my experience, effective advertising never comes cheap. :)
- Accelerating the bit flips might not be necessary, as the whole world of Wi-Fi access points is full of "misterious" lockups and misbehavior, which I've also seen myself countless times. Some of them are surely due to software bugs, but the majority has to do something with the close proximity between DRAM chips, radio interfaces and various pigtails hanging over the PCBs. Anybody who regularly deals with Wi-Fi access points should be able to easily see the difference in reliability after some time; it would be some kind of a real-world field study, but that's what counts most in the end – if you agree.
- At the same time, outdoor Wi-Fi access points are often mounted inside poorly ventilated enclosures, which in summer time create a much better environment for bit flips. :) All that makes it somewhat easier for people to "sense" a real-world level of reliabilty improvements.
- I know, giving things away might look ineffective, but that's how really big things became what they currently are. OpenWrt is a good example of such a project – it started small, but millions of people now use it or know what it is. Another example is the well-known Linksys WRT54 Wi-Fi device, which OpenWrt initially was made for: back at the time, Linksys was the only manfacturer to make the firmware source code easily accessible and in a complete form, effectively giving it away, and that snowballed making the WRT54 a legendary device that sold in who knows how large quantities.
- Please don't get me wrong, I'm not trying to convince you in any way; instead, I'm just providing some examples that might be related. :)
- Went ahead and expanded and clarified the Dynamic random-access memory article a bit; that's as much as can be added there without going against the WP:NOTADVERTISING guideline. Also, integrated-ECC DRAM wouldn't fit into the Dynamic random-access memory § Security section as it describes data remanence, which ECC has pretty much little to do with (maybe some more data could be extracted from powered-off DRAM by reconstructing it from extra bits, but that would require a strong reference anyway).
- Speaking of the Hamming code article, it describes the algorithm background while mentioning with very little of the actual products that use it; thus, adding product-related links as references unfortunately wouldn't make much sense. Also, "See also" sections can contain only links to already existing articles; once created, Intelligent Memory article might be added there. — Dsimic (talk | contribs) 10:16, 16 January 2015 (UTC)
- I highly appreciate all your input. And yes, I know a company having BGA soldering machines that could replace the RAM and I have no issues to do that for anybody that sends me a product to perform the testing and write about it on the web afterwards. But I can not buy routers or other products to rework them. If somebody wants to send us a router or other product to get it modified, I can arrange that.
- Especially if someone has such a Linksys WRT54 with known issues! Just buying a brandnew one can result in 'no issues at all even without ECC', because #1 not all DRAMs show up bit-flips, #2 most bit-flips only appear after some time of use, months, years or decades, #3 it is best to have a product that has known issues, although others have the same product with no such issues. If the problem-product gets fixed by ECC DRAM, we have even stronger proof! 80.156.59.106 (talk) 10:31, 16 January 2015 (UTC)
- Thank you, I also highly value our discussion. :) That's a very good point: replacing DRAM chips in an embedded device that's known to malfunction would be the best option! I'll see what can be done – finding people with such "bad" devices shouldn't be that hard. :) Of course, it would be necessary for the testing afterward to be publicly documented. — Dsimic (talk | contribs) 10:42, 16 January 2015 (UTC)
- I just found another article and had to post my comment to it right away ;-) http://smallformfactors.opensystemsmedia.com/articles/ruggedizing-ram-industrial-systems/ 80.156.59.106 (talk) 10:43, 16 January 2015 (UTC)
- Ah, they use mezzanine-style connectors to improve mechanical and electrical reliability, but with optional ECC. :) — Dsimic (talk | contribs) 10:53, 16 January 2015 (UTC)
- Did you also see my comment to it?
- FYI, the Linksys WRT54 seems to be quite old. It uses a 128Mbit DDR1 Hynix HY5DU281622FTP-J chip (very old and end of life). Today the DDR1 technology is rarely used and capacities are normally 512Mbit. I can hardly replace a 128Mbit with a 512Mbit, that might not work. Picture: http://dicks.home.xs4all.nl/wrt54gl-1.jpg 80.156.59.106 (talk) 10:58, 16 January 2015 (UTC)
{kind=link}
- Sure thing, I saw and read it; just wanted to say how irrational sounds to invest so much effort and funds into a brand new reliability-oriented memory module form factor without making ECC one of its mandatory features.
- You're right, WRT54 is an old design but still quite popular; though, due to its age we'll seemingly need to cross it off the list of potential candidates for "transplantation". How about some of the RouterBOARD embedded devices instead, they're also quite popular? For example, RB411, RB411AR, RB433AH, RB450, RB450G or RB493G models – are their memory chips available in integrated-ECC variants? It might be that even RouterBOARD as a manufacturer could be interested in using integrated-ECC DRAM chips, as they need reliability and RouterBOARDs are sold in really huge quantities, both as indoor/outdoor access points and CPEs. — Dsimic (talk | contribs) 11:14, 16 January 2015 (UTC)
- Hm, all of them must be over 5-10 years old. RB411 (DDR1 256Mb TSOP), RB411AR (DDR1 512Mb TSOP), RB433AH (DDR1 512Mb TSOP), RB450 (DDR1 256Mb TSOP), RB450G (DDR1 256Mb TSOP), RB493G (DDR1 512Mb TSOP). In DDR1 I have only 1 Gigabit in TSOP and 512 Megabit in BGA.
- I also looked at newer models like RB951G (DDR2 512Mb BGA), RB2011UIAS (DDR2 512Mb BGA). For these I have the right parts in stock
- The company behind Routerboard is Mikrotik. They are EXTREMELY price sensitive, which you can also see by the low sales prices they have for their routers!
- Their higher end routers use cheap Kingston memory modules (SO-DIMMs) without ECC. I could not find any outdoor product. 80.156.59.106 (talk) 11:39, 16 January 2015 (UTC)
- Those RouterBOARD models are relatively old; for example, RB450G was made available in February 2009, while RB493G was made available in November 2010. Well, at least it would be far easier to replace their TSOP-packaged DRAM chips, if their integrated-ECC variants were available. :) However, that's what RouterBOARD sells, and people buy a lot of them.
- You're right that RouterBOARD/MikroTik is price-sensitive, but those prices listed on routerboard.com in most cases aren't retail prices; for example, RB493G is listed with $199 as its MSRP, while its retail prices in Europe can be as high as 220 euros. To me, as well as to the majority of consumers, that price in euros is quite high for an embedded system with a 680 MHz CPU, 256 MB of RAM and 128 MB of flash. At the same time, they might want to shave $1–2 off their per-unit profits just to have "rock solid with ECC" as a selling point for their products: when such a board has 20–30 Wi-Fi customers associated on it, people usually want reliability. :)
- Regarding the outdoor products, well, all those models are also used that way. :) People just put those boards into outdoor boxes and that's it. There are some dedicated outdoor models, such as NetMetal 5, NetBox 5 or Groove 52HPn, but they're pretty much the same thing packaged in an outdoor box by the manufacturer. — Dsimic (talk | contribs) 12:20, 16 January 2015 (UTC)
- Well, if there is someone having any of those boards with random and 'always different' kinds of fails, and that board uses a 512Mbit TSOP, then I could put a 1 Gigabit TSOP on there and manually wire the address line A13 to ground. The chip will then behave like a 512 Megabit Chip.
- But for D-Link, Linksys, Netgear, Huawei, AVM and other routers, I see much more models using DDR2 or DDR3 memory. I can usually easily identify the DRAM by look at the PCB. And there are LOTS of pictures of opened routers on the web, so I can practically find out the DRAM-type on every router.
- Try to google for 'router sometimes stops working' or other word combinations. MILLIONS of entries! 80.156.59.106 (talk) 12:49, 16 January 2015 (UTC)
I'll try to find some "flaky" candidates for the "transplantation" of DRAM chips. You're right, there are countless other models of Wi-Fi access points / routers, and none of them is free of lockups and misbehavior; in other words, that's a huge market for ECC memory, with potentially huge benefits for the mankind. But, how to convince people that ECC memory is beneficial, that's the hard thing... :) That's why I've suggested all those steps for increasing the level of public awareness. — Dsimic (talk | contribs) 13:38, 16 January 2015 (UTC)
- Read this (and my reply): https://forum.openwrt.org/viewtopic.php?pid=261711#p261711
- This guy uses a TPLINK router and I can upgrade that! 80.156.59.106 (talk) 14:39, 16 January 2015 (UTC)
- Nice catch, that looks like a good candidate; let's see what will the original poster reply. — Dsimic (talk | contribs) 18:17, 16 January 2015 (UTC)
- No reply, yet. Maybe you can post a reply to animate the users to get some discussion going? 80.156.59.106 (talk) 11:33, 19 January 2015 (UTC)
- As we know, sometimes it takes more than a few days for people to respond. Providing some replies from my side in that forum thread would hardly be helpful, :) as I already know about the whole thing; to get it going, we need involvement and comments from actual people seeking for help or advice with their misbehaving embedded devices. — Dsimic (talk | contribs) 08:18, 20 January 2015 (UTC)
- Just saw your forum post, but for some reason the OpenWrt community seems not to be interested that much. Hm... Maybe the forum post was a bit too long, so it was perceived as a TL;DR? — Dsimic (talk | contribs) 00:05, 16 February 2015 (UTC)
- Yes, maybe. But I still think it is a topic that manufacturers of routers should be thinking of. Look at Cisco, they offer $1000+ routers which have ECC capable processors and use ECC memory modules on them. They offer them as business-class routers to companies and they sell lots of them. By simply replacing the DRAM on a normal router with ECC DRAM, the manufacturers like Netgear, D-Link, etc. could reach a similar reliability than Cisco at a fraction of the price, in fact just a very little more than a normal router.
- But anyway, the problem is to find a manufacturer who will adopt the technology and promotes it for his products. If they do, they will for sure sell a lot, win new customers, etc. It can impossibly be done by Intelligent Memory, because end-customers do not look at the chips, but they look at the features of the final product. 80.156.59.106 (talk) 08:52, 18 February 2015 (UTC)
- Well, Cisco already enjoys good reputation, and large customers looking for reliability will always go and buy Cisco products, no matter how good-looking are alternative products from other manufacturers. I had some experience with certain "business/enterprise-class" Ethernet switches made by an "el cheapo" manufacturer, and they simply don't work well despite looking great on paper – and the misbehavior was consistent, not intermittent. Thus, making a truly reliable product would require much more than just equipping the hardware with ECC memory – though, the ECC memory on its own would be playing a very significant role. — Dsimic (talk | contribs) 20:38, 18 February 2015 (UTC)
- Here's an update... A rather interesting RouterBOARD product equipped with 16 GB of ECC DRAM has been announced and should become available within a few months; here are a forum post and an article providing more details on Cloud Core Router CCR1072-1G-8S+, which is the announced product name. What's even more interesting is that the Tilera TILE-Gx processors used in the Cloud Core Router family of products seemingly support ECC memory, but the CCR1072-1G-8S+ should be the first actual product coming equipped with ECC SO-DIMM modules. Could it be that the manufacturers of embedded/networking equipment are slowly becoming aware of the importance of ECC memory? :) — Dsimic (talk | contribs) 08:44, 23 June 2015 (UTC)
Merry Christmas
Merry Christmas and Happy New Year! Password Saeba Ryo (talk) 12:59, 24 December 2014 (UTC)
- Thank you very much, best wishes to you too! :) — Dsimic (talk | contribs) 15:23, 24 December 2014 (UTC)
- Sorry, but I don't get it? Now you want to take back your good wishes? Changing your mood so quickly makes absolutely no sense, unless you've tried to use such stuff for campaigning related to the discussion taking place in Wikipedia:Articles for deletion/IA-32 (see also WP:CANVAS). — Dsimic (talk | contribs) 00:14, 25 December 2014 (UTC)
- This is not personal, but Merry Christmas and Happy New Year! Password Saeba Ryo (talk) 11:49, 25 December 2014 (UTC)
- Hehe, well, this is now really confusing and a bit weird. :)
- Please keep in mind that everything I wrote regarding IA-32 vs. x86 vs. x86-64 isn't judging you as a person but your statements, and all that has only improvements to the articles as the final goal. While working together on improving an article, the editors should judge only each other's contributions to the article and statements expressed on the talk page, and nothing more; that's what "it isn't personal" means.
- On the other hand, when we express good wishes related to holidays, there has to be at least some amount of personal involvement if the wishes are true. Such wishes show good will and positive feelings about an editor, while they aren't directly related to the articles we're working on or we have worked on.
- Hope it makes sense. :) — Dsimic (talk | contribs) 12:31, 25 December 2014 (UTC)
Hi. User:Password Saeba Ryo has been blocked indefinitely as a sock puppet of User:Janagewen. --Claw of Slime (talk) 12:13, 27 December 2014 (UTC)
- Hello! Thank you very much, Claw of Slime, for clarifying this somewhat awkward situation with Password Saeba Ryo. And, of course, Merry Christmas and best wishes for the around-the-corner 2015! :) — Dsimic (talk | contribs) 12:53, 27 December 2014 (UTC)
I invite you to this page to discuss that should the consistency of talk pages of IA-32, x86 and x86-64 should be kept! Because I've seen you as one of most active editors there. So thank you! Remover remover (talk) 15:14, 29 December 2014 (UTC)
- Thank you for bringing it to my attention, I've cast my vote there. — Dsimic (talk | contribs) 15:29, 29 December 2014 (UTC)
Nitpicking
Was this really necessary? To boost your edit count? I added the tag and reason; do we need to start nitpicking over a period? WP:OWN --82.136.210.153 (talk) 08:02, 28 December 2014 (UTC)
- Sorry, that probably came across too harsh. Didn't mean it like that. --82.136.210.153 (talk) 08:10, 28 December 2014 (UTC)
- Hello there! No worries, I'm not an overly thin-skinned person. :) Of course, removing that period wasn't absolutely necessary, but it should be better not to have it for two reasons: that isn't a complete sentence, and placing a period there effectively creates a "link" to a non-existing "GPL." section on the article's talk page. However, if you really prefer to have that period, please feel free to put it back. :) — Dsimic (talk | contribs) 08:32, 28 December 2014 (UTC)
Your revert of my changes in ZFS
Thanks for pointing me to WP:NOTBROKEN. I remember when people insisted to avoid all redirects but it was years ago and I see that things have changed since then. I'll keep that in mind. Thanks and best regards. —Rafał Pocztarski, Rfl (talk | contribs) 19:20, 4 January 2015 (UTC)
- Hello there! You're welcome, and I'm glad you're back to editing Wikipedia. :) Of course, it wasn't absolutely necessary to revert your changes, but that's simply how the guidelines mandate the usage of redirects. — Dsimic (talk | contribs) 19:28, 4 January 2015 (UTC)
Talk:Linux distribution—Third opinion request declined
Sorry I couldn't be of any help. @Chealer didn't seem to be interested in providing a concise viewpoint or participating in the process. With this being the case, I doubt a third opinion would have been any help.
I hope this can be resolved as you both continue to have a discussion. If not perhaps another route of dispute resolution would be more helpful.
Anyhow, I've enjoyed the correspondence I've had with you, and hope it all works out.
—Lightgodsy(TALKCONT) 09:54, 14 January 2015 (UTC)
- Lightgodsy, thank you very much for your good will and time invested into this, and I also really hope that Chealer and I will be able to reach some kind of a compromise soon, which I've already offered, avoiding that way the need to reach out for an official dispute resolution. — Dsimic (talk | contribs) 19:45, 14 January 2015 (UTC)
Edit warring

Your recent editing history at Linux distribution shows that you are currently engaged in an edit war. To resolve the content dispute, please do not revert or change the edits of others when you get reverted. Instead of reverting, please use the article's talk page. The best practice at this stage is to discuss, not edit-war. If discussions reach an impasse, you can then post a request for help at a relevant noticeboard or seek dispute resolution. In some cases, you may wish to request temporary page protection.
Being involved in an edit war can result in your being blocked from editing—especially if you violate the three-revert rule, which states that an editor must not perform more than three reverts on a single page within a 24-hour period. Undoing another editor's work—whether in whole or in part, whether involving the same or different material each time—counts as a revert. Also keep in mind that while violating the three-revert rule often leads to a block, you can still be blocked for edit warring—even if you don't violate the three-revert rule—should your behavior indicate that you intend to continue reverting repeatedly.
Suggesting that the behavior of other editors constitutes "trolling" may be interpreted as a personal attack. Working towards a resolution usually yields better results. Thank you for your contribution to Wikipedia. --Chealer (talk) 02:43, 15 January 2015 (UTC)
Thank you for nothing, and there you go. — Dsimic (talk | contribs) 02:51, 15 January 2015 (UTC)
PC/104
Hi Dsimic (whoever you are...)
The PC/104 Consortium's Specifications are FREE...- not like PICMG and others, but currently (and getting this changed is effort by the Board of Directors, as a change to the byelaws!) they require a REGISTRATION.
You have actually uploaded a document that you are not really allowed to share, but I can't be bothered to change this - AGAIN!
I also do not really agree that HyperLink to a HISTORIAL - for PC/104 - important person, like Rick is "SPAM", but then I am a newbie to Wiki edits.
I only landed on the PC/104 Wiki page by mistake. However, it would make sense to spend some more time on this. You seems to be interested in PC/104, so would you possible be interested in adding more information to this??
All the best
Flemming@Sundance (talk) 09:46, 15 January 2015 (UTC)
Flemming Christensen Flemming.C@Sundance.com Managing Director Tel: +44 7 850 911 417 Skype: Flemming_Sundance Web: www.sundance.com
Sundance Multiprocessor Technology is a limited company registered in England and Wales. Registered number: 2440991. Registered office: Chiltern House, Waterside, Chesham, Bucks, HP5 1PS, England
- Hello there! Well, please allow me to explain...
- Regarding this edit I've performed on the PC/104 article, I haven't uploaded anything anywhere; instead, I've used Google search to find that document. In general, references that require registration are dicouraged unless it's impossible to provide a directly accessible copy. Speaking of the particular PDF file, which is available as http://www.pc104.org/specifications/PCI104-Express%20v2_10.pdf, it resides on the same domain (pc104.org) as the registration page, http://www.pc104.org/pci104e_specs.php. Thus, it's clearly visible that I haven't uploaded anything. :) As you can see, the PDF file is actually directly accessible without a registration, and the registration lockdown isn't functioning properly for some reason. However, if you insist, reverting back to using registration page as a reference is perfectly doable.
- The other edit, as described in the edit summary, removed an external link to a LinkedIn profile and deleted an external link to a specification that didn't mention 2.10 as the latest PCI/104-Express version, and which also wasn't described as leading to further documentation that requires registration. In general, external links in article bodies are discouraged, and there's even a specific guideline against including links to LinkedIn profiles; please see WP:LINKSTOAVOID for more information.
- At the same time, just as a side note, people associated with an organization that an article describes should be (quoted from a guideline) "careful to make sure that their external relationships in that field do not interfere with their primary role on Wikipedia"; please see WP:EXTERNALREL for more information.
- Hope this clears the situation a bit. :) — Dsimic (talk | contribs) 10:58, 15 January 2015 (UTC)
A kitten for you!

I got all busy down a twisty road, in the cold, cold world of raw encyclopedic maintenance, and I forgot all about what a wonderful person you are. You deserve some kindness, and to never question whether your overall efforts are admired and appreciated.
— Smuckola (Email) (Talk) 11:53, 15 January 2015 (UTC)
- Thank you very much for kind words! Please don't get me wrong, but that might even sound just a bit too benevolent – or perhaps I'm overly humble. :) Knowing that someone somewhere cares about all the hard work creates a really warm and fuzzy feeling. :) — Dsimic (talk | contribs) 12:49, 15 January 2015 (UTC)
- Shaddap, ur overly humble. And you've got mail. <3 — Smuckola (Email) (Talk) 13:57, 15 January 2015 (UTC)
- Thanks. :) Will reply to the email with a delay, just so you know what's going on. — Dsimic (talk | contribs) 14:14, 15 January 2015 (UTC)
- Hm, how can you be so friendly and kind here, and so hostile and aggravated in the User talk:Smuckola § "External links" sections thread? If we disagree on something, that's perfectly fine and we're here to discuss it and find a solution with no need for personal attacks. Sorry, but the whole thing is somewhat confusing and doesn't make much sense. — Dsimic (talk | contribs) 10:42, 19 January 2015 (UTC)
- Smuckola, I'm still puzzled why have you reacted like that, especially as working with you later shows a completely different and friendly approach from your side? Please don't get me wrong, but I'd really appreciate if we could discuss it a bit. — Dsimic (talk | contribs) 01:40, 24 January 2015 (UTC)
List of distributed computing projects
I was glad to be able to help you the other day. If you don't mind returning the favor, I made a call for comments over at List of distributed computing projects. Thanks for any input you're willing to provide! – voidxor (talk | contrib) 05:59, 17 January 2015 (UTC)
- Hello! Sure thing, I'm already looking into it. That list really requires some attention. — Dsimic (talk | contribs) 06:06, 17 January 2015 (UTC)
Microcode
Hi. You asked why assembly language was delinked in Microcode. I gave the reason in my edit summary, WP:OVERLINK, because it already has a link further up the article in the "The reason for microprogramming" section. -Lopifalko (talk)
- Hello! Please, have a look at my edit, which linked it again and asked the question; it clearly shows that's the first occurrence of "assembly language" in the article. Moreover, that's the link in Microcode § The reason for microprogramming section you've unlinked earlier, probably by a mistake as that diff shows that Microcode had no other links to the Assembly language article. Hope it makes sense. :) — Dsimic (talk | contribs) 15:42, 17 January 2015 (UTC)
- Hi. Sorry to split hairs, I've double checked and the first occurrence appears to be "assembly" in Microcode#Overview. That's why I considered it WP:OVERLINK. -Lopifalko (talk)
- No worries, in my book being meticulous is a good thing. :) To me, it's Ok to have repeated piped links as they may appear completely different to the reader. That's somewhat similar to the deduplication between "See also" sections and piped links in the article body; you might want to have a look at an earlier discussion in Wikipedia talk:Manual of Style/Layout § "See also" and piped links. Hope you agree. — Dsimic (talk | contribs) 16:40, 17 January 2015 (UTC)
- Yeah, we're fine. Thank you for stopping by, it's always good to discuss anything that might seem like an issue. :) — Dsimic (talk | contribs) 02:36, 18 January 2015 (UTC)
Strange text in the dd article
Please have a look at Talk:Dd (Unix) § Non encyclopedical text in section Data recovery and check the remarks about the content about the "Data recovery" section as you have been a co-author of that section. Schily (talk) 15:07, 20 January 2015 (UTC)
- Hello there, and thank you for bringing it to my attention. I've adjusted the article a bit so it follows available sources as closely as possible, and provided my comment on the article's talk page. — Dsimic (talk | contribs) 05:27, 21 January 2015 (UTC)
Calling convention
The other OSes aren't listed below. The example is OS only, DOS is similar, but CMS is different, IIRC. Peter Flass (talk) 17:08, 21 January 2015 (UTC)
- Hello there! Thank you for pointing it out; if I got it right, you're referring to the edit I've performed on the Calling convention article? I haven't thought those are examples for other operating systems, that's pretty much obvious, :) but somewhow I've managed to make it read so. My bad, sorry, these changes should make it more clear by rectifying the mess I've made in the opening paragraph of Calling convention § IBM System/360 section. Please check it out. — Dsimic (talk | contribs) 07:18, 22 January 2015 (UTC)
- Sounds good. Peter Flass (talk) 12:10, 22 January 2015 (UTC)
- Thanks. — Dsimic (talk | contribs) 15:28, 22 January 2015 (UTC)
Transmeta processors
If you are not that busy, if you think it worthy answering me. So would please tell me why you think Transmeta should be sorted with Pentium 4? Of course I believe that you have enough reasons. Computerfaner (talk) 12:40, 23 January 2015 (UTC)
OK, I've return that table to its previous revision with modifications from Guy Harris. Yeah, this time is fare for everyone to make a new start. Thank you for your response, and you are free to deal with it on your own behalf. Computerfaner (talk) 12:58, 23 January 2015 (UTC)
- Hello! Well, I can't be that busy not to have enough time to respond in a timely manner. :) Regarding my response on Talk:x86, please have a look at pages 7 and 21 in this PDF file, for example. It confirms that Transmeta Crusoe and Efficeon are virtually compatible with the Pentium 4; thus, if we split the table by generations and associated architectural and ISA advancements, Transmeta processors should be in the same slot as Pentium 4. — Dsimic (talk | contribs) 13:07, 23 January 2015 (UTC)
- Yeah, you are right, and they are much more convincible. Thank you! Computerfaner (talk) 13:12, 23 January 2015 (UTC)
Neutral statements
Thanks for cleaning up my language. One thing I've seen done (required?): "[m]obile.." vs. "Mobile.." or "mobile".
"It might be better to leave out such comparisons and stay with as neutral statements as possible", I assume you mean ×4 and ×3. I'm just not sure people realize this. What I really want to include is someone saying Android's installed base is more than all others, not just more popular in a given year. Given these numbers it probably is but no one checks. Just comparing is not, not neutral I think, and allowed "basic calculations". Based on the next previous source. Not sure I should make a big deal of this, posting here and not at the talk page. comp.arch (talk) 11:14, 26 January 2015 (UTC)
- Hello! Yes, that's what I've meant by the edit summary of my edit on the Android (operating system) article. However, after having another look at the provided reference, I realized that it was my mistake to remove that statement. Sorry for that – I was under false impression that the reference provided some 2014–2016 market forecasts in that area, instead of a 2014 market analysis, and that misguided me into disregarding it as a reliable source for such a comparison. Thank you for bringing it here so I could see my mistake; I've re-added the shipment comparison back into the article, in a reworded form. — Dsimic (talk | contribs) 12:39, 26 January 2015 (UTC)
- And, I've fixed my addition a bit later. :) That was totally a brainfart but at least I've caught it. — Dsimic (talk | contribs) 13:02, 26 January 2015 (UTC)
A barnstar for you!

|
The Editor's Barnstar |
| For your numerous citation contributions to RAID, Standard RAID levels, Nested RAID levels, Non-standard RAID levels, and Non-RAID drive architectures, as well as your energetic copy-editing of those articles, I gladly award you the Editor's Barnstar! Way to go and keep up the good work! – voidxor (talk | contrib) 06:19, 2 February 2015 (UTC) |
- Thank you very much, voidxor! Receiving a barnstar from a fellow editor, after a significant amount of contributions we've made together to these articles, creates a true warm and fuzzy feeling. :) Let's keep making Wikipedia better! — Dsimic (talk | contribs) 06:35, 2 February 2015 (UTC)
Re: "Upright" parameter for images
Message added 01:23, 3 February 2015 (UTC). You can remove this notice at any time by removing the {{Talkback}} or {{Tb}} template.
- Thanks for the notification, but I've already seen your reply on my watchlist and will respond shortly. — Dsimic (talk | contribs) 02:07, 3 February 2015 (UTC)
New article help request
Hey Dsimic, I created the pages GNU Guix and Guix System Distribution. Do mind contributing to them when you get a chance? -- WikiTryHardDieHard (talk) 13:54, 4 February 2015 (UTC)
- Hello! Thank you for bringing it to my attention, I'll have a look at those a little bit later. — Dsimic (talk | contribs) 16:09, 4 February 2015 (UTC)
BIOS: acronym or initialism
You say that BIOS is "clearly an initialism." But the OED says that an initialism has "each letter...pronounced separately" which is not true of BIOS. Even if there are definitions of "initialism" that do not require that, there is still an ambiguity between those definitions and the OED definition. The word "acronym" has no such ambiguity and is thus superior. --Jtle515 (talk) 01:41, 5 February 2015 (UTC)
- Hello! Regarding my edit on the BIOS article, I stand corrected. Thank you for bringing it here; as described in Acronym § Nomenclature, the distinction between an acronym and initialism "hinges on whether the abbreviation is pronounced as a word or as a string of individual letters", meaning that, for example, "NATO" is an acronym, while "FBI" is an initialism. Thus, "BIOS" is clearly not an initialism. My bad, sorry. — Dsimic (talk | contribs) 21:58, 5 February 2015 (UTC)
Edits to PXE article
My friend; You might not like what I have added but (as I've said with my last edit). I appreciate very much if we discuss first at the talk page and you edit later. Please undo your last editing and lets discuss; That's how things are done here at WP right? ;-) Pxe 213 37 84 214 (talk) 14:36, 5 February 2015 (UTC)
- Hello! Regarding one of my edits on Preboot Execution Environment, if you agree it would be the best to keep the discussion within Talk:Preboot Execution Environment § PXE chosen for professional/large scale OS boot/Install deployment (References), so other editors can also provide their opinions. Sorry for my delayed response, I'll comment there in a few minutes. — Dsimic (talk | contribs) 21:39, 5 February 2015 (UTC)
ATX connector drawing fixed
I fixed File:ATX PS signals.svg drawing. It is shown in ATX and Power supply unit (computer) in English Wikipedia. It took me numerous hours to fix it, since it was the first time I used a SVG editor. I listed detailed changes in the photo upload history. Anyway, I noticed that you previously edited these articles, thus is why I'm letting you know. If you see any technical mistakes, please let me know. You don't need to reply nor contact me, unless there are problems. • Sbmeirow • Talk • 16:16, 5 February 2015 (UTC)
{kind=link}
- Hello there, Sbmeirow, and thank you for fixing the drawing! BTDT, so I know very well how time-consuming such seemingly simple changes can be, especially when they're one's first steps in editing SVG files. I've checked your updated version against page 26 in a reference and actual 24-pin and "P4" power connectors, and everything is now correctly oriented and labeled. Good job! — Dsimic (talk | contribs) 17:21, 6 February 2015 (UTC)
- Sbmeirow, I've just slightly adjusted the File:ATX PS signals.svg drawing so individual pins are square-shaped as they should be, what was the only remaining inaccuracy. Hope you're fine with that. — Dsimic (talk | contribs) 14:53, 8 February 2015 (UTC)
Office 2016?
Hi.
I think I should let a few (hopefully) interested editors, such as yourself, know about Wikipedia:Redirects for discussion/Log/2015 January 31 § Microsoft Office 2016 because the RfD tag was deleted and the discussion is about to be closed in a day.
Best regards,
Codename Lisa (talk) 04:40, 6 February 2015 (UTC)
- Hello! Thank you for bringing it to my attention, I've cast my vote there. — Dsimic (talk | contribs) 05:54, 6 February 2015 (UTC)
File:DHCP session en.svg
Hi, I noticed that a beginner user (Gelmo96) was edited the page Dhcp and now you are reverted his editing. Perhaps the procedure followed by Gelmo96 is not correct, but reading the textual content of the page Dhcp you can see that every DHCP message has the broadcast destination (Dest=255.255.255.255) although in the image file:DHCP_session_en.svg some messages are "unicast". Thanks for your kind help. Fabuio (talk) 20:28, 6 February 2015 (UTC)
{kind=link}
{kind=link}
- Hello there, Fabuio! Thank you for bringing here my revert of Gelmo96's edit on the Dynamic Host Configuration Protocol article. Actually, I've reverted the edit based on the fact that there's no "DORA protocol" as DORA is just an abbreviation for different DHCP stages, and back at the time I haven't compared the content of File:DHCP session.svg and File:DHCP session en.svg illustrations. My bad, sorry for that – let's analyze them now.
- Here are two excerpts from the section 4.1 of the RFC 2131 (titled "Constructing and sending DHCP messages"):
- If the 'giaddr' field in a DHCP message from a client is non-zero, the server sends any return messages to the 'DHCP server' port on the BOOTP relay agent whose address appears in 'giaddr'. If the 'giaddr' field is zero and the 'ciaddr' field is nonzero, then the server unicasts DHCPOFFER and DHCPACK messages to the address in 'ciaddr'. If 'giaddr' is zero and 'ciaddr' is zero, and the broadcast bit is set, then the server broadcasts DHCPOFFER and DHCPACK messages to 0xffffffff. If the broadcast bit is not set and 'giaddr' is zero and 'ciaddr' is zero, then the server unicasts DHCPOFFER and DHCPACK messages to the client's hardware address and 'yiaddr' address. In all cases, when 'giaddr' is zero, the server broadcasts any DHCPNAK messages to 0xffffffff.
- [...]
- A client that cannot receive unicast IP datagrams until its protocol software has been configured with an IP address SHOULD set the BROADCAST bit in the 'flags' field to 1 in any DHCPDISCOVER or DHCPREQUEST messages that client sends. The BROADCAST bit will provide a hint to the DHCP server and BOOTP relay agent to broadcast any messages to the client on the client's subnet. A client that can receive unicast IP datagrams before its protocol software has been configured SHOULD clear the BROADCAST bit to 0.
- And, here's a paraphrased excerpt from the section 2 of the RFC 2131 (titled "Protocol Summary"):
- ciaddr: Client IP address; only filled in if client is in BOUND, RENEW or REBINDING state and can respond to ARP requests.
- yiaddr: 'Your' (client) IP address.
- giaddr: Relay agent IP address, used in booting via a relay agent.
- Following the protocol descriptions above, DHCPOFFER messages in a typical non-renewing DHCP session with no relays (that is, both "ciaddr" and "giaddr" fields are zero) can be both unicasts and broadcasts (0xffffffff is the IP broadcast address), what depends on a particular DHCP client and its abilities to receive unicast IP traffic before its IP stack has been fully configured. Moreover, even DHCPACK messages can be unicasts. At the same time, even the DHCPDISCOVER and DHCPREQUEST broadcast messages may be replaced with unicasts in case the DHCP client already knows the DHCP server's IP address, as described in section 4.4.4 of the RFC 2131 (titled "Use of broadcast and unicast").
- With all that in mind, I went ahead and deleted all "unicast" and "broadcast" labels in the File:DHCP session.svg drawing and redirected File:DHCP session en.svg to it, and clarified it a bit in the article. Marking any messages as unicasts or broadcasts would require a lengthy explanation that simply wouldn't make sense in image captions. Hope you and Gelmo96 agree on that. — Dsimic (talk | contribs) 19:09, 7 February 2015 (UTC)
{kind=link}
- Thanks for the deep discussion and the excerpts from the RFC. I greatly appreciate your precise response. Perhaps we have to upload a new version of File:DHCP_session_en.svg (because it is also used in wikibooks.org, in wikiversity.org, etc.) and after we can remove File:DHCP_session.svg. What do you think? Fabuio (talk) 23:09, 7 February 2015 (UTC)
- You're welcome, and thank you very much for bringing the issue here so we can discuss it and make the article and drawings more accurate. :) I'd say that File:DHCP session.svg should be left as it has a shorter name, while File:DHCP session en.svg should be deleted, of course after all pages using it are modified to use File:DHCP session.svg. Currently, the File:DHCP session en.svg → File:DHCP session.svg redirect takes care of accuracy, but that makes File:DHCP session en.svg pretty much redundant. Hope you agree. — Dsimic (talk | contribs) 14:12, 8 February 2015 (UTC)
- I agree with you, but there is something that I don't understand, because in this page wikibooks I can still see the old image File:DHCP session en.svg. I suppose that currently still there is not automatic redirection. — Preceding unsigned comment added by Fabuio (talk • contribs) 19:38, 8 February 2015 (UTC)
- You're right, it really seems that the File:DHCP session en.svg → File:DHCP session.svg redirect doesn't work despite being placed as instructed in Help:File redirect – a quote from that Commons help page explains why:
- Technically, file redirects are ordinary redirects on
File:pages, and they can be created manually. However, this only works where there is no file of that name (if there is a file, any uses of the redirect show the redirect's file, and not the target file - Bugzilla:14928).
- Technically, file redirects are ordinary redirects on
- With that in mind, I've tagged File:DHCP session en.svg with a speedy deletion request and a note that it should be redirected to File:DHCP session.svg afterwards, what should yield the desired outcome. We'll see whether the admins on Commons will agree to that. — Dsimic (talk | contribs) 08:45, 9 February 2015 (UTC)
- You're right, it really seems that the File:DHCP session en.svg → File:DHCP session.svg redirect doesn't work despite being placed as instructed in Help:File redirect – a quote from that Commons help page explains why:
- Speedy deletion proposal for File:DHCP session en.svg was rejected, so I've instead tagged it with a note that a more correct version is available. Sorry, but I really don't have the time and energy for going into a lengthy discussion that would probably follow a nomination for deletion. — Dsimic (talk | contribs) 20:12, 10 February 2015 (UTC)
{kind=link}
{kind=link}
- Ok, thanks. If the deletion is too time consuming, after the next week I would try yo update the old image. Fabuio (talk) 19:30, 13 February 2015 (UTC)
- If you're willing to invest some time into it, maybe you could nominate the old image for deletion instead? The nomination itself isn't too complicated, as described in Commons:Deletion requests. The reason why I'm suggesting deletion instead of updating the old image is just to reduce the duplication of content in Commons; variety is a good thing in general, but the old and the new image are pretty much the same what can only create confusion and increase clutter – if you agree. — Dsimic (talk | contribs) 20:14, 13 February 2015 (UTC)
Thanks to User:Dsimic for the research. I removed the labels and uploaded a new version of the file. I object to deleting my original work because the proposed replacement slaps a CC-SA license over a minor modification of my PD-licensed original. While that is legally OK, I find it unethical (because of the attempt to remove the more liberally licensed original) and want to keep the PD-licensed file accessible. ~~helix84 14:21, 18 February 2015 (UTC)
{kind=link}
- Hello, and thank you for updating File:DHCP session en.svg! Unfortunately, I really haven't paid attention to the licensing of these two drawings, and my deletion proposal was based solely on used file names – File:DHCP session.svg is just simpler. Though, with your updates and explanation of different licensing, I'd say that there should be no reasons to delete File:DHCP session en.svg. — Dsimic (talk | contribs) 20:53, 18 February 2015 (UTC)
- Thank you. ~~helix84 10:25, 21 February 2015 (UTC)
- You're welcome, and thank you for creating the File:DHCP session en.svg drawing in the first place. :) Also, I've untagged the file as those tags no longer applied, and slightly improved the description at the same time. — Dsimic (talk | contribs) 18:29, 21 February 2015 (UTC)
{kind=link}
Request for comment (ARM cores)
Hi. I noticed that "Comparison of current ARM cores" is a subset of "Comparison of ARMv7-A cores", except for the ARM11 column, thus I consider it redundant and put in a request to DELETE the "Comparison of current ARM cores" article. If you are interested, please comment at "Wikipedia:Articles for deletion/Comparison of current ARM cores". Thanks in advance. • Sbmeirow • Talk • 20:40, 8 February 2015 (UTC)
- Hello! Thank you for bringing it to my attention, I've cast my vote there. — Dsimic (talk | contribs) 09:11, 9 February 2015 (UTC)
Manual of Style re: Shingled magnetic recording
Hi, I believe your recent edits to the article shingled magnetic recording go against the Wikipedia Manual of Style. Specifically:
- Text-source intergrity. The citations should not be bundled together at the end of the paragraph; instead, each citation should follow the sentence or paragraph it supports.
- External links. The two external links you included are technical discussions of SMR on the Linux storage subsystem. The article is not about the Linux storage subsystem, the external links are not useful in the context of the article.
I would like consensus to be reached about these edits. I side with the MoS as outlined above. IsaacAA (talk) 14:00, 10 February 2015 (UTC)
- Hello! Regarding my recent edits on Shingled magnetic recording, here are my comments on your concerns:
- Placement of references should be as you've described it, of course, but only in case when there's a clear distinction in what each reference covers. In this case, we have a few partially overlapping references, so none of them can (or should) be clearly selected for specific parts of the paragraph; if we wanted to do so, we'd end up with something like "...[1] ... ...[2] ... ...[1][2]", and reusing references like that really wouldn't be that much useful. On top of that, the paragraph is rather simple and short, so the readers should be easily able to see which reference covers what. However, this placement might be some kind of a compromise.
- Including a link to an LWN.net article is actually rather fine, as it shows how specifics of the SMR can be used (or better said, covered) in particular operating systems. The fact is that SMR as a recording technology isn't free of drawbacks, so it's rather important to cover those aspects as well. Right now we have that only as an external link, but in the future and as SMR gains more traction, the article actually should be expanded with more detailed descriptions of operating-system-specific handling of SMR's non-transparent features.
- Hope you agree. Of course, I'm more than open to discussing this further. — Dsimic (talk | contribs) 20:46, 10 February 2015 (UTC)
Edit war on page Android version history
There seems to be an edit war going on user. Kapibada is adamant that 5.1 is unofficial however does not give any significant proof that it is unofficial. I will re-add 5.1 segment. Looking for your advise as you seem to manage that page for long. Thank you. — Preceding unsigned comment added by Debasish Dey (talk • contribs) 21:46, 17 February 2015 (UTC)
- Hello! I wouldn't say that I've been "managing" anything – I've just spent a lot of time so far contributing to the Android version history article and cleaning it up. :) Regarding Kapibada's edit that removed Android 5.1 version from the article, I'd suggest that we start a discusson on Talk:Android version history and use it to decide whether there are enough WP:RELIABLE sources to have Android 5.1 as part of the article; many sources seem to treat 5.1 as not yet officially announced by Google, so we should seek for opinions from more editors. By the way, that isn't an WP:EDITWAR and there are no reasons for it to become one – we're all here to discuss things and find the best possible solutions. — Dsimic (talk | contribs) 02:20, 18 February 2015 (UTC)
- Hello! I understand you aren't managing things and thank you for your response. However there are many many sources out there which prove 5.1 does exist. There are no sources that disprove it's existence. The reason why I am asking for your help is because I was banned once for edit war and I don't want to start another one. Thank you for your understanding. best regards. — Preceding unsigned comment added by Debasish Dey (talk • contribs) 16:04, 18 February 2015 (UTC)
- Totally understood. With that in mind, why don't you just start a discussion on Talk:Android version history, and I'm sure there will be at least a few editors willing to provide their opinions on including Android 5.1 into the article? — Dsimic (talk | contribs) 20:57, 18 February 2015 (UTC)
Instruction set
Sounds better. Peter Flass (talk) 13:16, 21 February 2015 (UTC)
- Hello! Once again, sorry for reverting your edit, but the formatting was pretty much against MOS:BOLD, and the additional wording was slightly confusing. Of course, I'm glad that you like subsequent improvements I've made to the Instruction set article. :) — Dsimic (talk | contribs) 18:38, 21 February 2015 (UTC)
Kilometres per hour
Hello,
I reverted your edit again. As I explained in my previous edit summary, per MOS:SERIAL, articles should be internally consistent in their use (or disuse) of the serial comma. There's no ambiguity in the original wording that would necessitate a serial comma, so your change does not make the article "better" or "more readable" in any way. In essence, you're changing that sentence from one style to another based on nothing but your own personal preference, which is expressly forbidden by WP:MOS.
If you wish to make a case for the use of a serial comma in that sentence, please do so here (or on the article's talk page, if you wish). Re-doing an edit after it gets reverted is strongly discouraged (WP:BRD).
Regards, Indrek (talk) 23:28, 23 February 2015 (UTC)
- Hello! To me, having something like "in alpha, beta, and gamma slang and formal use" is significantly more readable than "in alpha, beta and gamma slang and formal use", simply because the additional comma adds a pause that distinguishes one "and" from another. Following the MOS:SERIAL blindly isn't what it or any of the guidelines suggests. Moreover, could you please explain why did you change the format of references in the Kilometres per hour article? That's also just a personal preference, this time yours, and also shouldn't be a practice – in case we want to follow the guidelines blindly. — Dsimic (talk | contribs) 00:42, 24 February 2015 (UTC)
- First, I'm not suggesting that we follow MOS:SERIAL blindly, and I'll thank you not to throw around such baseless accusations. I'm suggesting that we follow it because in this particular case there's no good reason not to.
- As for that edit you refer to, it mainly consisted of the following:
- changed a few freehand references to use citation templates
- changed a few citation templates from vertical to horizontal format
- changed the format of a few accessdates
- fixed a few broken parameters that were throwing errors
- added some missing parameters and changed a few others (e.g. to split the names of multiple authors)
- These are all fairly routine changes, done for the sake of consistency within the article (per WP:CITESTYLE and MOS:DATEUNIFY), not for personal preference. If you find any of those changes objectionable or think they actively harm the article, please provide some more details and I'll be happy to address any legitimate concerns you may have. Regards, Indrek (talk) 08:48, 24 February 2015 (UTC)
- Fair enough. Please don't get me wrong, but your initial description looked like it was following blindly the MOS:SERIAL guideline, without going into the actual content, meaning or readability. Though, I'd say we're on the same page after discussing it further on the article's talk page. Out of curiousity, why haven't you changed the citations from horizontal/compact to vertical/expanded format? Personally, I find the vertical/expanded format far more readable, and I'd always be investing my time into something that also makes the Wiki code more readable on top of improving the article-wide consistency. — Dsimic (talk | contribs) 23:31, 24 February 2015 (UTC)
- Re my initial edit summary, I guess I can see how it could have given the wrong impression, but rest assured I was considering the meaning and readability of the sentence. As you say, it turned out we were on the same page and simply interpreted the sentence differently. I appreciate the feedback, and will try to keep it in mind for future edit summaries.
- As for the ref formats, I changed to horizontal simply because there were far more refs already using that format. That's generally how editing for consistency works - you change the few outlying exceptions to use the same format as the majority of the article. Horizontal format does also happen to be my personal preference (I find vertical format somewhat wasteful and breaking the flow of text when reading an article's source), and in fact I've yet to see an article that uses vertical format consistently, but that's neither here nor there.
- I hope this clarifies my reasoning. Best regards, Indrek (talk) 05:30, 26 February 2015 (UTC)
- Thank you for the additional clarification, everything is fine. As a side note, this just demonstrated how much effort and time creating something like Wikipedia requires, and I bet that majority of the general population simply isn't aware of that. :) Speaking of the edit summaries, no worries, I do know how difficult is to be expressive enough in that limited amount of space.
- Yes, I know what you mean – making the article more consistent by converting style of various elements to what's already present in majority is fine, especially if there are only a few of such "irregular" elements. Back at the time, I've considered different formatting styles for references, and here's what I've concluded:
- Inline, horizontal formatting – it is very compact, but makes the Wiki code totally unreadble unless there are references only at the ends of paragraphs (what, as we know, isn't the best practice and as such usually isn't the case).
- Inline, vertical formatting – it wastes significant amounts of vertical space for sure, but makes the resulting Wiki code much more readable and much more easily editable at some later point in time.
- Separated at the end of article, whichever formatting – it is the best-looking style by far, making the resulting Wiki code super lean and very readable. Unfortunately, it has a fatal flaw – this style totally defeats the whole concept of editing sections.
- With all that in mind, I've spent some time choosing between (2) and (3), ending up with selecting (2). Speaking of articles that use vertical references format consistently, I happen to know more than a few, and I'll tell you which are those if you promise not to change their formatting. :) — Dsimic (talk | contribs) 06:44, 26 February 2015 (UTC)
Piped links (cont.)
Hi Dsimic, Re [4], you asked me to read User talk:Dsimic#Piped links. So your justification for making that edit is that both Chris Cunningham (user:thumperward) and I disagree with you, and there's no basis in policy or guideline?! (In fact, articles often suffer with unpiped links incorrectly using a capitalised link, so it is a common thing to fix when unpiped, and a piped one is no justification for using the incorrect case). Because it's so obvious there's no consensus for the principle you believe in, but it is too trivial to edit war over, I suggest you reflect on the sound justification for using the correct case for links that Chris and I agree on, appreciate that the tone is harsh but appropriate, and try to refrain. Keep up the other good work, regards Widefox; talk 11:12, 26 February 2015 (UTC)
- I started a discussion about undoing most of my edits (including this trivial issue) at Talk:CoreOS. Widefox; talk 12:17, 26 February 2015 (UTC)
- Hello! The case of piped links is one of the very few things I've disagreed on with other editors so far; however, it's a rather minor thing. As already explained in § Piped links discussion above, there isn't a single guideline that could turn it into something more than a personal preference; thus, no approach is either correct or incorrect. As a result, once they're placed, it would be the best simply not to change the case of piped links. Also, in the specific case of CoreOS article we could even pull the article-wide consistency argument that would pretty much demand uppercase piping as all other piped links are... uppercase. :) I saw your discussion on the article's talk page; my thoughts are available in my reply there, please have a look. — Dsimic (talk | contribs) 01:52, 27 February 2015 (UTC)
- Yes, let's keep that talk there. If thumperward (Chris Cunningham) would comment there it would also be appreciated, so I'll ping him. Widefox; talk 21:08, 27 February 2015 (UTC)
- Agreed, it's always better to keep specific "streams" of a discussion in one place. — Dsimic (talk | contribs) 03:26, 28 February 2015 (UTC)
Host card emulation – hijacking by some CardsApp company
Dsimic, I have noticed you were contributing to the post "host card emulation". So thank you as you have helped clean up the post. However, there has been a recent onslaught on the post by a few individuals that seem to really want to promote a company called "CardsApp". I am not as well versed in wikipedia posts as you so I was hoping you could help clear this page up and return it to a previous version where "CardsApp" is not doing self promotion.
Kindly, Theodore9dw (talk) 06:34, 1 March 2015 (UTC)
- Hello! I've reverted the Host card emulation article to its version from February 16, 2015 as it contains better wording, and major additions since then (which boil down to Host card emulation § "hCE+" or "hCE2" and Host card emulation § Security sections) were pretty much unsourced. Also, introducing the CardsApp thing was clearly an advertising attempt. — Dsimic (talk | contribs) 07:17, 1 March 2015 (UTC)
Wikiviewstats utility

Dear Dragan,
you use Wikiviewstats for calculating viewership of your articles. As I know, this tool is offline since months. How have you used it for Feb '15 data?--Kopiersperre (talk) 17:06, 3 March 2015 (UTC)
- Hello! You're right, unfortunately Wikiviewstats has been offline for months, but I'm still somewhat reluctant to delete links to it from the User:Dsimic § Created and started articles section of my user page, simply because it is (or was?) such a great utility. Hopefully someone is working on it, so it will become available again.
- Since Wikiviewstats became unavailable, and before is became available at all, I used to calculate views statistics by hand, using the statistics data available from stats
.grok .se, but that turned into a rather tedious job for 30 articles even when performed only once per month. :) Thus, about a month ago I wrote a PHP program that calculates required monthly statistics using the data available in JSON format from stats .grok .se. It's a rather simple PHP program, and here's an example of the output it generates:
Processing Address generation unit: done. (total 739 views) Processing UniDIMM: done. (total 1,580 views) Processing kdump (Linux): done. (total 861 views) Processing kernfs (BSD): done. (total 220 views) Processing kernfs (Linux): done. (total 649 views) Processing ftrace: done. (total 919 views) Processing Android Runtime: done. (total 10,933 views) Processing WebScaleSQL: done. (total 802 views) Processing HipHop Virtual Machine: done. (total 5,003 views) Processing kpatch: done. (total 1,314 views) Processing kGraft: done. (total 1,094 views) Processing CoreOS: done. (total 9,104 views) Processing ARM Cortex-A17: done. (total 2,167 views) Processing Port Control Protocol: done. (total 1,174 views) Processing zswap: done. (total 959 views) Processing Emdebian Grip: done. (total 324 views) Processing ThinkPad 8: done. (total 468 views) Processing Laravel: done. (total 9,352 views) Processing OpenLMI: done. (total 382 views) Processing Open vSwitch: done. (total 3,384 views) Processing Distributed Overlay Virtual Ethernet: done. (total 457 views) Processing Management Component Transport Protocol: done. (total 562 views) Processing Buildroot: done. (total 784 views) Processing dm-cache: done. (total 1,899 views) Processing bcache: done. (total 1,291 views) Processing SATA Express: done. (total 14,692 views) Processing OpenZFS: done. (total 1,511 views) Processing List of Eurocrem packages: done. (total 120 views) Processing M.2: done. (total 36,447 views) Processing Eurocrem: done. (total 702 views) Stats fetched for February 2015: total 109,893 views, 3,924 views per day (28 days in month).
- Of course, you're more than welcome to use this PHP program if it happens to fit your needs. :) — Dsimic (talk | contribs) 04:31, 4 March 2015 (UTC)
- This tool would be great. For my 750 stubs in german wikipedia I'm even less prone to do this by hand. May you send me the PHP script by mail?--Kopiersperre (talk) 09:41, 4 March 2015 (UTC)
- Just copy the PHP program code from the source of User:Dsimic/Traffic stats calculation page (what's between
<syntaxhighlight lang="php">and</syntaxhighlight>) and paste it into a file – that's the latest version of the actual program code. :) The current version might work too slowly when fetching statistics for 750 articles, so please let me know how fast it works once you get it going – it should be possible to make it much faster by using HTTP pipelining throughcurl_multi_exec(). — Dsimic (talk | contribs) 11:51, 4 March 2015 (UTC)
- Just copy the PHP program code from the source of User:Dsimic/Traffic stats calculation page (what's between
- My internet connection is quite slow, so I think parallelization is not necessary for me. I've ran 770 articles, which needed 596 seconds. My results:
- Stats fetched for February 2015: total 73,338 views, 2,619 views per day (28 days in month).
- -> Bitter to see, but predicteable, that your 29 english articles have more views than all my small german articles. But – as a german wikipedian wrote – Wikipedia is not for readers--Kopiersperre (talk) 22:14, 4 March 2015 (UTC)
- Actually, HTTP pipelining might help significantly when this program runs on slower Internet links, as the program would be reusing TCP connections instead of opening new one for each JSON data pull. Would you be willing to test a version with HTTP pipelining? I could make it available in a day or two. Speaking about how many page views are there, it all depends on the actual articles and how much people are interested in them; the essay you've linked above describes other involved aspects rather well. Oh, and it's 30 articles, and two more should be there soon. :) — Dsimic (talk | contribs) 02:55, 5 March 2015 (UTC)
- Went ahead and implemented a much faster way of pulling statistics data, together with producing more verbose results that now also include timing information and additional summary in case fetching data failed for some articles. The old version took about 20 seconds to fetch the data for 30 articles, while the new version takes... Well, have a look at the actual output:
Fetching statistics data: ... done. - Address generation unit: total 739 views - UniDIMM: total 1,580 views - kdump (Linux): total 861 views - kernfs (BSD): total 220 views - kernfs (Linux): total 649 views - ftrace: total 919 views - Android Runtime: total 10,933 views - WebScaleSQL: total 802 views - HipHop Virtual Machine: total 5,003 views - kpatch: total 1,314 views - kGraft: total 1,094 views - CoreOS: total 9,104 views - ARM Cortex-A17: total 2,167 views - Port Control Protocol: total 1,174 views - zswap: total 959 views - Emdebian Grip: total 324 views - ThinkPad 8: total 468 views - Laravel: total 9,352 views - OpenLMI: total 382 views - Open vSwitch: total 3,384 views - Distributed Overlay Virtual Ethernet: total 457 views - Management Component Transport Protocol: total 562 views - Buildroot: total 784 views - dm-cache: total 1,899 views - bcache: total 1,291 views - SATA Express: total 14,692 views - OpenZFS: total 1,511 views - List of Eurocrem packages: total 120 views - M.2: total 36,447 views - Eurocrem: total 702 views Done, February 2015 statistics for 30 articles fetched in 1 second. Total 109,893 views, averaging in 3,924 views per day (28 days in that month).
- Isn't that bad, right? :) Could you please test the new version, which is, as usually, available on User:Dsimic/Traffic stats calculation? — Dsimic (talk | contribs) 08:42, 5 March 2015 (UTC)
- With CURLMOPT_MAXCONNECTS = 10 I got too many failures:
Done, February 2015 statistics for 144 articles fetched in 14 seconds. Fetching the views statistics failed for 618 articles.
- With 2 parallel connections, I still get 478 failures. Cool feature, but useless for me, I live with high ping.
- I've sorted my results with sort -n, because I want to know, which are my top articles. Could you sort the JSON before outputting?--Kopiersperre (talk) 14:31, 5 March 2015 (UTC)
- Thank you very much for testing! I'll see if there's something that might improve the reliability when dealing with slow connections. By the way, which version of PHP are you using? I'm asking that because HTTP pipelining is supported since PHP 5.5. Sorting the output by total views is a good suggestion, will get that implemented and let you know when it's available. — Dsimic (talk | contribs) 14:47, 5 March 2015 (UTC)
- PHP Version => 5.6.6--Kopiersperre (talk) 15:00, 5 March 2015 (UTC)
- Hm, that makes HTTP pipelining supported. Here's a new version, which adds some more timeout-related runtime configuration, and sorts the output by the total article page views. Could you please test this version, both in its original form and with
curl_multi_setopt($handles, CURLMOPT_PIPELINING, 0);andcurl_multi_setopt($handles, CURLMOPT_PIPELINING, 1);on line 72? — Dsimic (talk | contribs) 15:56, 5 March 2015 (UTC)
- Hm, that makes HTTP pipelining supported. Here's a new version, which adds some more timeout-related runtime configuration, and sorts the output by the total article page views. Could you please test this version, both in its original form and with
CURLMOPT_PIPELINING=true:
[..]
> Russian Chemical Reviews: fetching data FAILED!
> Tricyclazol: fetching data FAILED!
Done, February 2015 statistics for 246 articles fetched in 16 seconds.
Fetching the views statistics failed for 516 articles.
CURLMOPT_PIPELINING=0:
[...]
> Josiphos: fetching data FAILED!
> Carteolol: fetching data FAILED!
Done, February 2015 statistics for 263 articles fetched in 20 seconds.
Fetching the views statistics failed for 499 articles.
CURLMOPT_PIPELINING=1:
[...]
> Chevron Phillips: fetching data FAILED!
> 2-Methylbenzylchlorid: fetching data FAILED!
Done, February 2015 statistics for 263 articles fetched in 13 seconds.
Fetching the views statistics failed for 499 articles.
Mysterious--Kopiersperre (talk) 16:27, 5 March 2015 (UTC)
- Quite mysterious indeed. Thank you very much for the testing, I'm thinking about what could be an efficient way to debug this further, as there must be something trivial preventing it from working faster and reliably even on slow uplinks. Sorting works well, by the way? — Dsimic (talk | contribs) 16:37, 5 March 2015 (UTC)
- Got the PHP program expanded so it now additionally fetches and displays the cURL runtime errors, improving at the same time the way outputs are stored internally (what isn't important for the debugging). Here's an example of what a few simulated failure messages look like, they're also sorted by grouping together the same error types:
> ftrace: failure (Could not resolve host: staats.grok.se) > OpenZFS: failure (Could not resolve host: staats.grok.se) > kernfs (Linux): failure (Could not resolve host: staats.grok.se) > Eurocrem: failure (Protocol "hhttp" not supported or disabled in libcurl) > dm-cache: failure (Protocol "hhttp" not supported or disabled in libcurl)
- Could you please test this version, which is, as usually, available on User:Dsimic/Traffic stats calculation? With the additional debug information now available, we should be able to see what's exactly causing data pulls to fail. — Dsimic (talk | contribs) 09:31, 6 March 2015 (UTC)
- For debugging I constrained on my first 100 articles. With 100 articles the script runs fine. Problems begin with more than ~180:
[..] - Leptophos: total 10 views - Journal of Polymer Science: total 7 views PHP Notice: Undefined offset: -1 in /tmp/run/verboseviewstats.php on line 597 PHP Notice: Undefined offset: -1 in /tmp/run/verboseviewstats.php on line 597 > Dimepiperat: failure () PHP Notice: Undefined offset: -1 in /tmp/run/verboseviewstats.php on line 597 > Maleimid: failure () PHP Notice: Undefined offset: -1 in /tmp/run/verboseviewstats.php on line 597 > Nicosulfuron: failure () > Tetraethylenpentamin: failure () PHP Notice: Undefined offset: -1 in /tmp/run/verboseviewstats.php on line 597 > Dichlon: failure () [many undefined offsets] PHP Notice: Undefined offset: -1 in /tmp/run/verboseviewstats.php on line 597 > Chanda: failure () > 10,10′-Oxybisphenoxoarsin: failure (Connection timed out after 10002 milliseconds) > Dichlormid: failure (Connection timed out after 10002 milliseconds) > Benoxacor: failure (Connection timed out after 10002 milliseconds) > International Journal of Medical Microbiology: failure (Connection timed out after 10002 milliseconds) > Thidiazuron: failure (Connection timed out after 10002 milliseconds) > Refratechnik: failure (Connection timed out after 10001 milliseconds) [other 10001 ms timeouts] > Befehl Nr. 227: failure (Connection timed out after 10000 milliseconds) [other 10000 ms timeouts] > Dimethylchlorsilan: failure (Connection time-out) > Lothar Kühne: failure (Connection time-out) > Cytec: failure (Connection time-out) > Tributylmethylammoniummethylsulfat: failure (Connection time-out) > Alexander Tamanjan: failure (Connection time-out) [..]
- Sorry for my late reply.--Kopiersperre (talk) 21:13, 6 March 2015 (UTC)
- For debugging I constrained on my first 100 articles. With 100 articles the script runs fine. Problems begin with more than ~180:
- No worries about the slight delay, there's no hurry. :) Thank you very much for detailed testing, now it's much more clear what's happening. Here's an improved version of the program: the statistics data is now fetched in chunks while pausing between two chunks, as fetching data for a large number of articles at once causes stats
.grok .se to start refusing or delaying HTTP connections. The bug resulting in "Undefined offset: -1" error messages was caused by a silly mistake I've made and haven't caught during the testing on my side; that's also fixed now. - Could you, please, test this version? Based on the test results on your side, we'll decide whether further changes in the program logic are required; what's left to be modified/improved is to keep retrying to fetch statistics data until that succeeds (or goes over a predefined number of retries, of course). — Dsimic (talk | contribs) 10:39, 7 March 2015 (UTC)
- No worries about the slight delay, there's no hurry. :) Thank you very much for detailed testing, now it's much more clear what's happening. Here's an improved version of the program: the statistics data is now fetched in chunks while pausing between two chunks, as fetching data for a large number of articles at once causes stats
- Works very nicely. You could improve this tool further with fetching someone's articles from http://tools.wmflabs.org/sigma/created.py?name={USERNAME}&server={lang}wiki&max=2000&ns=,,&redirects=none .--Kopiersperre (talk) 22:39, 7 March 2015 (UTC)
- Great news, thank you very much for testing it out! :) How long does fetching the statistics take in the end, for your large list of articles? Anyway, I'm still thinking about implementing the retrying of failed HTTP requests, as that would be a pretty much "bulletproof" approach. Would you be willing to test (another :) new version, if I make it available in a day or two?
- Your suggestion for fetching the list of created articles automatically is great, and actually I've already thought about something like that. Though, the trouble is that the above linked utility from tools.wmflabs.org provides only HTML results, not "raw data" in some kind of a "machine-parseable" format such as JSON. HTML could be parsed as well, but that's a somewhat pointless exercise as even slight changes in the page design would completely break the parsing "engine". However, I'll give it a second thought later today. — Dsimic (talk | contribs) 09:18, 8 March 2015 (UTC)
- Done, February 2015 statistics for 760 articles fetched in 3 minutes and 22 seconds.
- Fetching the views statistics failed for 2 articles. (Articles which have brackets in their title)--Kopiersperre (talk) 10:01, 8 March 2015 (UTC)
- That's a rather good result, compared to about ten minutes we had before with a completely sequential approach. :) Could you, please, send me those two article titles that have brackets in them? — Dsimic (talk | contribs) 10:12, 8 March 2015 (UTC)
- de:Verordnung (EG) Nr. 440/2008 and de:Verordnung (EU) Nr. 517/2014 über fluorierte Treibhausgase give failure (Parsing JSON data failed).--Kopiersperre (talk) 11:30, 8 March 2015 (UTC)
- Thank you! Fetching the statistics data for these two articles failed because their titles contain slashes, and stats
.grok .se expects /not to be URL-encoded as%2F. Got that fixed in a new version, I'd appreciate if you could test it out. Also, this version implements easier selection of the encyclopedia/language for all specified articles. — Dsimic (talk | contribs) 15:56, 8 March 2015 (UTC)
- Thank you! Fetching the statistics data for these two articles failed because their titles contain slashes, and stats
Yahoo! requested move
I created a proposal for moving Yahoo! to Yahoo. If you have a minute, we'd appreciate your input. – voidxor (talk | contrib) 09:56, 5 March 2015 (UTC)
- Hello, and thank you for bringing it to my attention. Sure thing, I've just provided a comment on the article's talk page. — Dsimic (talk | contribs) 10:22, 5 March 2015 (UTC)
Broadwell memory
Hi Dragan, remember Intelligent Memory and the ECC DRAM discussion we had?
Now I just noticed you also handle the Wikipedia entey for the Broadwell architecture. Per Intel specs the Broadwell-U only supports max 16GB of memory by two memory slots (8GB per memory module). But there is an internal Intel document that explains how this can be doubled. The memory has to fulfill special requirements for that, because the Broadwell-U internal memory controller has a little "bug". A standard memory module with 16GB could be unstable. Intelligent Memory has the first 16GB modules that work in all the new notebooks and laptops that are now coming to the market and use the i3/i5/i7-5xxxU CPUs.
On the Wikipedia page about the Broadwell I find nothing about the memory-support, but maybe you have good reason for that!? One reason could be that the Broadwell-U has the chipset and the CPU together on one SOC, while other Broadwells separate that. The memory support depends on the chipset. Am I right? If that is correct then adding something about the memory-support of the Broadwell-U might be too complex or confusing for readers. Twmemphis (talk) 16:17, 7 March 2015 (UTC)
- Hey Thorsten! Sure thing I remember our earlier discussion. :) Now you have an account on the English Wikipedia? Regarding the Broadwell-U SoC variant, there actually is a brief description of its memory support – here's what the Broadwell (microarchitecture) § Expected variants section currently says about it (emphasis added):
- Broadwell-U: SoC; two TDP classes – 15 W for 2+2 and 2+3 configurations (two cores with a GT2 or GT3 GPU) as well as 28 W for 2+3 configurations. Designed to be used on motherboards with the PCH-LP chipset for Intel's ultrabook and NUC platforms. Maximum supported memory is either 16 GB of DDR3L-1600, or 8 GB of LPDDR3-1600. The 2+2 configuration is scheduled for Q4 2014, while the 2+3 is estimated for Q1 2015.
- Do you have some references regarding the availability of supported 16 GB DIMMs, allowing for a total of 32 GB of DDR3 DRAM? If so, the article can be easily expanded to provide that information as well. By the way, memory support depends primarily on the CPU itself, as all modern Intel (and AMD) CPUs have integrated memory controllers (IMCs). The situation is a bit different with ECC memory, in which case support from the chipset is also required; however, that doesn't affect the Broadwell-U CPUs as they have no native support for ECC memory. — Dsimic (talk | contribs) 10:03, 8 March 2015 (UTC)
Ice Cream Apps article – evaluation of complaint
If you have time, can you offer an opinion or evaluation about the 209.6.201.191's message in User talk:Donner60 § IceCream Apps is spam. I replied about general editing guidelines but I really don't have the expertise to evaluate the complaint about the existing article as being spam. I had reverted the edit because the IP user had replaced general language with extremely negative language. Perhaps some of the complaint has merit but the language and type of edit needed to be reverted. If you don't have time or interest for this, no problem. Donner60 (talk) 01:21, 9 March 2015 (UTC)
- The exact link to the Wikipedia article is IceCream Split & Merge. Donner60 (talk) 01:23, 9 March 2015 (UTC)
- Hello! As far as I can see, short of trying out the software myself, the application is marketed in the same way IceCream Split & Merge article currently describes it, so the article follows the sources closely. Though, the problems arise from relying on sources that are pretty much advertisements for that application, what would require at least one or two more sources such as independent application reviews.
- With that in mind, the edit performed by 209.6.201.191 might totally be the right thing to do (though, in a different style); however, as you've already noted, we'd need sources for that as well. If there are reliable sources confirming what 209.6.201.191 says about the nature of the application (I was unable to find any such sources), the article should be edited accordingly or maybe even deleted; otherwise, the article needs to stay as-is, but should be tagged with
{{Third-party}}. — Dsimic (talk | contribs) 08:38, 9 March 2015 (UTC)
[sic] in a quote in Docker article
Hi. You reverted some changes to Docker (software) where " [sic]" was removed from after "on premise" in a quote. I wanted to justify the removal and see if it might change your mind. (It's a small thing and doesn't matter to me either way, so feel free to ignore me.) Checking Google Ngram Viewer, the use of "on premise" seems on the rise. A cursory glance at books using "on premise" shows it's used in the same sense as "on premises". It's also a common phrasing in cloud computing contexts. Yes, I'm aware prescriptivists say it's not grammatically correct, but that's beside the point. " [sic]" is used to proactively deny a transcription error has occurred, but is unnecessary if there's no reason for that assumption. I'm trying to argue that (given the context and rising usage of the phrase) there is no reason for readers to assume there has been a transcription error, and thus " [sic]" may be safely removed. 128.205.39.37 (talk) 16:02, 10 March 2015 (UTC)
- Hello! Ah, by no means I'd choose to ignore your suggestion – IMHO, nobody's suggestion should ever be ignored, no matter how small or insignificant it might seem, simply because there's always something new to learn.
- Regarding my edit and your explanation, please let's compare Google Ngram results for "on premise" and "on premises": the former is for sure on the rise since the 1980 (peaking at around 0.0000008% in 2000), but the latter is still far more used (averaging at around 0.000016% between the 1940 and 2000, with no large fluctuations). Very roughly speaking, that makes "on premises" at least 0.000016 / 0.0000008 = 20 times more used than "on premise" (just by comparing the 2000 values, and many more times if we'd calculate the exact ratio for, say, last 40 years), what just confirms which of the two forms is more correct. As we know, every language tends to become less strict over time, just as every system naturally tends to have its entropy increased, but that simply isn't the reason for less correct forms to be supported. Hope you agree. — Dsimic (talk | contribs) 17:50, 10 March 2015 (UTC)
- Thanks for the cordial response. Point taken; best leave the " [sic]". 128.205.39.37 (talk) 20:20, 11 March 2015 (UTC)
- Thank you for bringing it here in the first place. :) I'm glad that we're on the same page. — Dsimic (talk | contribs) 20:24, 11 March 2015 (UTC)
- By the way, just had a look at Google Ngram results for 1800–2008 (we've used 1800–2000 results above, leaving out eight most recent years): "on premises", "on premise", and a comparison. It's quite interesting to see that "on premises" increases significantly after 2000, while "on premise" dips at the same time. — Dsimic (talk | contribs) 06:14, 17 March 2015 (UTC)
My reverts of 108.73.114.110
This is a very-long-ongoing issue of a banned user. It's a wp:deny effort. No issue here with you or others undoing my reverts. See User:Arthur Rubin/IP list and the current discussion on Arthur Rubin. Many edits are OK, though often strange, if not bizarre, such as linking the British Pound symbol "£", or New Zealand while ignoring other countries. It's OCD v. OCD! Cheers Jim1138 (talk) 07:46, 19 March 2015 (UTC)
- And now blocked again: Special:Contributions/108.73.114.110 Best Jim1138 (talk) 07:52, 19 March 2015 (UTC)
- Hello! Thank you for a detailed explanation, I was quite surprised to see those reverts (and, maybe, even the actual edits by 108.73.114.110) on the Firmware and Trusted Platform Module articles. Speaking of the OCD, well, it all depends on how one channels such issues. :) — Dsimic (talk | contribs) 08:13, 19 March 2015 (UTC)
- I suspect the set of "sane" is fully a subset of "insane". It's interesting that s/he links only one item a time. And, typically adds the linked article to the edit summary enclosed with parens. It would be nice to 'turn' the IP into a grammar nazi or such. Could be highly useful. Cheers Jim1138 (talk) 09:25, 19 March 2015 (UTC)
- That's quite interesting. Have you tried to discuss the whole thing with the IP address? I know, such attempts usually end up as pretty much futile endeavors, but it might be worth a try. — Dsimic (talk | contribs) 09:40, 19 March 2015 (UTC)
Brogrammer
I consistently see you around computer related articles (and that one third opinion) and would be interested in your opinion on this deletion discussion, if you'd care to give one there. —Lightgodsy(TALKCONT) 23:06, 19 March 2015 (UTC)
- Hello! Thank you for bringing it to my attention, after having a look at the Brogrammer article I've cast my vote on the article's deletion nomination page. — Dsimic (talk | contribs) 04:34, 20 March 2015 (UTC)
Is Linux an operating system?
Well, most of people refers to the operating systems based on Linux kernel as Linux. however Linux is just a kernel, a piece of code written by a finnish guy with contributions of many people around the world, to make any OS able to use a lot of devices. it is true that the operating systems based on Linux belongs to the Linux family of operating systems as cited there: https://en.wikipedia.org/wiki/MOS:LINUX#Linux_vs._GNU.2FLinux, but that doesnt mean that Linux is a real entire OS. many geeks know that Linux is a kernel and dont say that it is an OS. for example GNU is the most free OS used today which missed a kernel and than gets combined with Linux: https://www.gnu.org/gnu/linux-and-gnu.html.
When you say that you use Linux when you use a Linux based system like GNU or Android, you mean then that the Linux developers has written the entire OS and released its binaries and all the applications running in the system, which is wrong. Debian GNU/Linux is an OS, Android is too, Chromium also. Please stop writing wrong informations about operating systems, that affects the knowledge of many people which is not nice. — Preceding unsigned comment added by Kb333 (talk • contribs) 14:22, 27 March 2015 (UTC)
- Hello! What I've reverted back isn't wrong information; however, my user talk page isn't the right place for discussing this ever-recurring Linux vs. GNU/Linux thing. I'll provide my feedback on an appropriate article talk page, while pinging you so you can know where to reply. — Dsimic (talk | contribs) 14:33, 27 March 2015 (UTC)
GNU/Linux distribution
Can you have a look at this redirect. We have an editor who seems to be trying to turn it into a very COI/POV article against consensus. - Ahunt (talk) 14:45, 27 March 2015 (UTC)
- Hello, and thank you very much for bringing it to my attention! GNU/Linux distribution, as a redirect, should never be expanded into a separate article, and the content you've reverted was a clear example of what's known as WP:POVFORK. I've added this redirect to my watchlist, and, following the MOS:LINUX guideline, tagged it with
{{R from incorrect name}}. Hope you agree with the tagging. — Dsimic (talk | contribs) 15:25, 27 March 2015 (UTC)
Linux article and edit warring
By my count you haven't broken 3RR but you should be aware of the report I filed at ANEW. BethNaught (talk) 18:58, 28 March 2015 (UTC)
- Hello! Thank you for letting me know, and for filling the report in the first place. As you've probably seen it yourself, unfortunately it was (and still is) almost impossible to discuss the whole thing about the Linux article with Kb333. However, I've tried as much as possible to stay away from reverting the edits, and especially to stay away from breaking the WP:3RR rule – but the range of choices was pretty much limited, if you agree. — Dsimic (talk | contribs) 19:19, 28 March 2015 (UTC)
- My thanks to you also. I'll continue to keep an eye on the page. BethNaught (talk) 20:49, 28 March 2015 (UTC)
- That would be great. I've also thought about filling the report myself, but it's much better when not filled by an editor directly involved in a discussion. — Dsimic (talk | contribs) 20:53, 28 March 2015 (UTC)
Art and artificial intelligence
Dear Dragan, you probably already know about this, but when you have a chance, please check out the additions to the "Criticism and comment" section of Deep learning and the article referenced therein -- I would rather that my friends take the first shots at all of this! And be sure to take a look at the first footnote of the article proper. Synchronist (talk) 23:59, 28 March 2015 (UTC)
- Hello! It's been a while, how are you? :) Regarding your recent edits on the Deep learning article, unfortunately there may be some issues with the proivided reference (which is surely an interesting read). In a few words, additional care should be applied when referencing one's own work, especially when it's published on a blog; please see WP:NEWSBLOG, WP:BLOGS and WP:ATT for further information on related guidelines. — Dsimic (talk | contribs) 06:02, 29 March 2015 (UTC)
- Dragan, your concerns are well taken, and in fact I am not unhappy to have the chance to defend the reference to my own article and its validity as a source.
- The underlying point is that artificial intelligence represents a quite extraordinary topic. One the one hand, like nuclear physics, it is a topic which has the possibility of affecting all of our lives, even unto the existential level; but unlike nuclear physics -- to which, realistically speaking, only physicists and mathematicians can contribute -- artificial intelligence has the potential of becoming the most democratic of all sciences, i.e., if we are to craft the ideal intelligence, which discipline would we willing to ignore? History? Medicine? Literature? Furthermore, I note that AI is a relatively young science, and therefore -- like the aeronautics of 1903 -- capable of benefiting from the input of the non-academic. So, all in all, I think Wikipedia has ample justification for offering greater than usual latitude in its scrutiny of AI sources.
- In respect to the particulars of my case, Wikipedia states, in "Citing yourself", that "you may cite your own publications just as you would cite anyone else's, but make sure your material is relevant and that you are regarded as a reliable source". As to the relevance aspect, you have not made this an issue, not to mention that I expended a great deal of care and thought as to how the reference to my article was integrated into the larger Wikipedia article, even to the extent of writing an introductory paragraph for the section in which it appears and slightly enlarging its focus, from "Criticisms" to "Criticism and comment".
- As to my reliability as a source (and here allow me to apologize for having to bring up some subjects with which you have had to deal ad nauseam as an experienced Wikipedia editor), there are of course two basic questions apart from the testimony of the cited article itself: first, my own qualifications in respect to the article in question, and second, the qualifications, if you will, of the media outlet which has made the decision to publish it. In regard to the former -- i.e., my qualifications to write an article on the intersection of computing and society -- I am tempted to get up on my high horse and talk about computing as another young discipline, and about Bill Gates not having graduated from college, blah, blah, blah; but instead, I will let the biographical sketch published on my user page speak for itself. In regard to the latter -- i.e., the authority of the publishing process at "ArtEnt.net"., where my article appeared -- let me say, first, that this is one of those "blogs" which is really more like an on-line journal or review in that it is published by two PhD mathematicians employed by Penn State University and features some quite technical coverage of the AI arena; and second, that they gave my article a thorough critique, and the substantiality of which can be demonstrated by comparing the article as published to that which was submitted to them, and to the latter of which a link has long since been available on my user page.
- Having said all of the above, I would be delighted, were you or another Wikipedia editor to find favor with my article, to have my edits reverted and the article plugged in by another hand -- this to avoid the very real stigma of self-reference; but I suspect that it will be difficult to avoid duplicating to some extent the manner of its integration. Synchronist (talk) 18:05, 29 March 2015 (UTC)
- Ah, please don't get me wrong, I've read your article before writing anything and to my knowledge it's all fine regarding the factual accuracy – just wanted to present you with a few Wikipedia guidelines so you can be prepared if anyone challenges its validity. I haven't challenged your competence or validity of the article as a reference, and it's probably a mishap that the website publishing the article has "blog" in its name at all. In other words, and if you agree, it should be better to have me point out those guidelines, rather than having someone else do that later. :)
- Speaking of blogs in general, it's really tough to say which of them are good as references and which aren't – perhaps the related Wikipedia guidelines should be slightly adjusted in that regard, but that would be a highly debatable topic and probably wouldn't reach consensus required for the changes to take place. On the other hand, printed books and "officially" published papers seem to be simply too slow to keep up with the rapid pace of advancements in recent years. As soon as a book is printed, chances are high that it's already slightly obsolete.
- Artifical intelligence (AI), as you've described it very well, is a highly specific area that has very high impact potential. I'd just add that AI's greatest aspect (or danger?) comes from almost anyone being able to work on it, with pretty low requirements regarding the equipment etc. To build a nuclear reactor, one needs rare materials, a lot of space, huge amouns of power, etc. – pretty much unapproachable by an individual. On the other hand, even a medium-class modern computer, which isn't that expensive, allows almost anyone to do whatever he or she wants with exeperimenting in the broad area of AI. Isn't that fascinating?
- Please allow me to return to using self-authored texts as references – I've also used an old published paper as a reference in one of the Wikipedia articles, guided by the fact that it's been published, peer-reviewed, and co-authored by two more individuals. Exactly those precautions—making sure it's good enough to serve as a reference—are what I've referred to as "additional care". :) — Dsimic (talk | contribs) 06:55, 30 March 2015 (UTC)
- I copy, Dragan. And of course I was just kidding about the whip thing!
- On a more serious note, your point about anyone being able to experiment with AI is quite sobering, and not as unlikely as it might seem at first. That "anyone", for example -- as I'm sure you have anticipated -- would not need to have created an entire AI system on his own; to make mischief, he would merely need to download an AI code set and tinker with some of the parameters -- like reversing the polarities of the "good" and "bad" indices. Synchronist (talk) 12:28, 30 March 2015 (UTC)
- Exactly, almost anyone can do such "script kiddie" AI-related things, to call them that way. Moreover, a smaller number of people should be capable of modifying existing AI implementations, and, why not, writing their own implementations. Of course, there aren't many people capable of modifying existing or writing new AI implementations, but the fascinating thing is that all they need fits into a backpack – there's no need for acres of space, tons of concrete, rare materials, etc. — Dsimic (talk | contribs) 13:02, 30 March 2015 (UTC)
- Wow -- I had never really thought about AI as a weapon, but you present a very compelling scenario. Dragan, let's think about how to raise the profile of such concerns on Wikipdia -- and our first problem will be breaking through all the clutter surrounding "hacking", "cybercrime", and so on. (Although computer viruses is a closely related topic.) But I have just been selected as a jury member for a second-degree murder trial (not kidding, unfortunately), so I am going to be pinned down for a week or so. Synchronist (talk) 01:44, 31 March 2015 (UTC)
- Well, yes, AI is a quite dangerous thing, and I always recall Isaac Asimov's short story "Breeds There a Man...?" in which it's nicely described how humans play with something that's above their actual mental capacities. Something like that is dangerous, as—beside the possibility to use AI as a weapon—we might be releasing an uncontrollable self-improving entity; there's no need to mention any of numerous science fiction movies plotting various disastrous scenarios. Speaking of raising public awareness, I'd say that's an already lost race, simply because the whole thing around the AI is already ridiculed enough in various movies so people simply don't take it seriously. Also, people are quite busy with posting stupid statuses and revealing their lives on social networks, or filming their cats in HD or, even better, in 4K. Or maybe killing some zombies in video games. All that unfortunately doesn't leave much time for thinking – sad, but true.
- Good luck with the jury duty! Maybe there will be no need for juries and trials in general once the AI advances enough. :) — Dsimic (talk | contribs) 19:26, 31 March 2015 (UTC)
ARMOR – row hammer
Hi Dsimic,
First of all thanks for editing my post. I am fairly new to wikipedia so accept my apologies if what I am asking is obvious. Can you please let me know why did you change the title of my post "ARMOR: A Hardware Solution to Prevent Row Hammer Error" to "A Run-time Memory hot-row detectOR"? I believe the first title gives more information to the user who is looking for a solution to this phenomenon. Also, you changed the link directly to the solution page rather than home page. Can you please explain the reason?
Regards, Mohsen Ghasempour (talk) 19:35, 30 March 2015 (UTC)
- Hello! No worries, all kinds of questions are more than welcome.
- Please let me start from the second question. I've changed the link so it points to the solution page, which provides information not contained in the Row hammer article, because the originally linked home page provides only what's already covered in the article. The purpose of external links is, in general, to go beyond what the article already covers, and the home page simply doesn't fit the bill.
- Speaking about the link description, explaining "ARMOR" as an acronym seems to fit better, while staying a bit on the neutral side; if we describe it directly as a solution that prevents curruption caused by the row hammer effect, that might be slightly on the advertising side. With a rather neutral acronym description, it's up to the readers to find more about what ARMOR does; also, anyone who reaches that external link after digesting the whole article, will clearly conclude that ARMOR prevents errors caused by the row hammer affect.
- By the way, after reading the solution page, I'm still rather unclear what ARMOR actually is internally, and how is it supposed to interface with existing DRAM solutions? Or is it supposed at all? In other words, the whole thing seems to resemble a commercially oriented "an awesome black box, call for prices" description, to a certain degree of course. Are there maybe any further in-depth descriptions available? — Dsimic (talk | contribs) 21:15, 30 March 2015 (UTC)
- Many thanks for your clear explanation. Yes, ARMOR is a research project so there will be more in-depth description available to the public soon. Mohsen Ghasempour (talk) 08:27, 31 March 2015 (UTC)
- You're welcome, and thank you for bringing the questions here in the first place. Looking forward to in-depth papers about ARMOR, please let me know when they become available. — Dsimic (talk | contribs) 18:57, 31 March 2015 (UTC)
LAMP (Laser-Aided-Mechano-Predators)
Hey man maybe you can give me your opinion on this clarity/redundancy goal on an edit, see Talk:LAMP (software bundle)#Discussion of how to refer to LAMP. makeswell (talk) 01:01, 3 April 2015 (UTC)
- Hello! Sure thing, I'm already looking into it, and will provide my feedback there. — Dsimic (talk | contribs) 01:06, 3 April 2015 (UTC)
- Done, here's what seems to me like a slightly better proposal for the lead section; looking forward to your comments on it. By the way, Makeswell, I'm really glad that we're working on improving the opening paragraph of LAMP (software bundle), which certainly needed some work. — Dsimic (talk | contribs) 01:36, 3 April 2015 (UTC)
- Beautiful! Yes, very well-written. I am glad too to help. :) makeswell (talk) 02:15, 6 April 2015 (UTC)
- Thank you, went ahead and propagated the changes into the article's lead section, while incorporating some minor further cleanups into the original proposal. — Dsimic (talk | contribs) 02:41, 6 April 2015 (UTC)
Wikipedia:Manual of Style/Computing (3)
You obviously have good ideas but I'd say this time, it didn't quite cut it. IMHO, "Required sources" is not a suitable title for a subsection of "Avoid common mistakes". It implies that providing sources is the mistake; but we should say the reverse: Forgetting to provide sources is the mistake. (The original title was "not providing sources".)
But one of your other edits was so good that I imitated it in another section. And your edit in the x86 was in fact good, even though I changed the section, because it made me realize new things. Cheers. Fleet Command (talk) 08:03, 17 April 2015 (UTC)
- Hello! Thank you, I'm glad that you like one of my edits. :) Also, thank you for reverting back changes introduced in my other edit – as you've described it, "required sources" doesn't go well within a list of suggestions against common mistakes. Though, how about using "often-neglected sources" or maybe "unsupplied sources", instead of "oft-neglected sources"? To me, "oft-neglected sources" seems to be somewhat uncommon.
- The table you've introduced into the Wikipedia:Manual of Style/Computing § x86 versus IA-32 section looks nice and provides a good overview; I've just touched it up a bit. At the same time, IA-32 clearly isn't what may cause ambiguity, as you've already pointed out. Well done, if I may notice. :) — Dsimic (talk | contribs) 05:42, 18 April 2015 (UTC)
My recent edits you undid
You recently undid some of my edits removing ipsec.pl references. The references are being used as a form of self promotion, the site in question is operated and written by the editor that added them to the articles. The links he is adding the write ups to notability and frankly the information he is linking to is poorly done, hence my reasons for removing them. Offnfopt(talk) 06:53, 23 April 2015 (UTC)
- You haven't really read WP:SELFCITE and WP:SELFPUB, did you? These citations and articles do not violate any of the policy statements, there's nothing there to promote myself, only hard data which was the sole reason why I added them. Pawel Krawczyk (talk) 07:14, 23 April 2015 (UTC)
- Hello to both of you! Well, using self-written material as references isn't strictly prohibited, it's just that additional care should be exercised to make sure there's the required level of content quality and neutrality. For example, this writing isn't that bad at all – sure thing, it isn't one of the absolutely hard-core low-level descriptions of Heartbleed, but it also isn't one of the "just for clicks" webpages. This one, providing a high-level overview of web application attacks, also isn't that bad to be simply deleted. Let's discuss this further, if you agree.
- Just for later reference, here are the diffs for Offnfopt's initial reference removals in the OpenSSL, Heartbleed and PHP articles, which I've reverted. As a brief reminder, edit summaries should always be provided, especially when deleting content; the exceptions are clear vandalisms, but that obviously wasn't the case here. — Dsimic (talk | contribs) 08:12, 23 April 2015 (UTC)
- Plus the reference linking to my article IPsec.pl on Heartbleed was not even added by myself but by User:Petter Strandmark [5] which makes Offnfopt's link spamming accusation unsubstantiated. Pawel Krawczyk (talk) 12:49, 23 April 2015 (UTC)
PC home Advanced?
Hi.
Do you know of any computer-related publication called "PC home Advanced"? I suspect it is a typo but I don't know what could be the correct form.
If you want a little background, this is mentioned in Wikipedia:Articles for deletion/IZArc (2nd nomination) as an evidence to keep the article.
Best regards,
Codename Lisa (talk) 17:51, 25 April 2015 (UTC)
- Hello! Unfortunately, I've never heard of or seen any publication (or anything else) named exactly "PC home Advanced". That's probably a typo as you've assumed, but I've unsuccessfully tried to Google out a few possible alterations. Sorry I couldn't help. — Dsimic (talk | contribs) 22:37, 26 April 2015 (UTC)
Big Foot
Dragan, it's me, Glenn! (BTW, I read your article on distributed data base systems -- some solid work!! -- and have gleaned from it your gmail address, which I am obviously not using at the moment.) At any rate, I have set a trap for Big Foot! See my user page for the fun . . . Synchronist (talk) 05:24, 28 April 2015 (UTC)
- Hello! How did the jury duty go? Hopefully everything went fine.
- Yeah, that old paper about web applications and distributed databases tried to cover a few real-life usage scenarios, and it would be rather interesting to perform the benchmarking again after all the changes MySQL had experienced over time. Also, I'd probably copyedit the paper extensively, as I'd say that my English had improved in all those years. :) By the way, that's just the short version of the paper, and there's the much more detailed non-English version that has about 8–9 times more pages.
- I've seen the joke you've added to your user page – it's a good one and it took me some time to figure it out on my own... The key is to know that "paw" is a homophone to "pa", which, in turn, is shortened from "papa". :) — Dsimic (talk | contribs) 12:04, 28 April 2015 (UTC)
PC PSU
Thank You, this edit requires to click the diagrams. I suggest to undo it to keep the diagrams visible without a click. See the German version "Deutsch" of the article where it was possible to lineup 2 images or a gallery with the option called "floating" at the right side. The help:gallery_tag and help:pictures do not address how to do this. --Hans Haase (有问题吗) 20:02, 1 May 2015 (UTC)
- Hello! Yeah, I'm aware of the available options for the multiple image layouts, for example what's achievable by using the
{{Multiple image}}template. The reason why I've moved all images into a gallery is simply because there are four images in the relatively short Power supply unit (computer) § Functions section, and that's pretty much the only way to keep the section layout reasonably clean. However, this layout change should present some kind of a compromise, increasing the size of thumbnails while keeping all four images in a gallery. Hope you agree. — Dsimic (talk | contribs) 22:40, 1 May 2015 (UTC)
{{Multiple image}}was exactly what I was looking for. Thank you! I guess, it is soved[6] and You have a higher resolution on your screen than my one, so please review. --Hans Haase (有问题吗) 11:22, 2 May 2015 (UTC)
- Unfortunately, it doesn't look good, especially on higher-resolution screens... The trouble, beside the fact that it made the section look cramped, is that images spill far into the next section, making the whole thing quite unreadable. How about this change instead? IMHO, it looks worse than having smaller thumbnails (especially after subsequent tweaks that brought all thumbnails in the article to a consistent state), but I'm more than willing to compromise. :) — Dsimic (talk | contribs) 06:16, 3 May 2015 (UTC)
- Those standalone thumbnails and galleries totally looked too large, so here's the take three, please have a look. To me, it looks great now, especially after additional tweaks for the sizes of remaining thumbnails. — Dsimic (talk | contribs) 06:36, 3 May 2015 (UTC)
- Good job, everything is visible and it looks fine. Thank you! --Hans Haase (有问题吗) 14:17, 3 May 2015 (UTC)
- Great, I'm glad that you like it! :) — Dsimic (talk | contribs) 12:22, 4 May 2015 (UTC)
Python infobox example for a template documentation
Hi, Dsimic. I was wondering what reference errors the Python example that I added to the documentation for Infobox programming language introduced. Because I didn't see any reference errors when I was changing the infobox, and I'm pretty sure I would've spot them if there were any reference errors. Also, the Scheme example felt kind of outdated, and I just thought that the example needed an update. Thanks. Kamran Mackey (talk) 01:25, 8 May 2015 (UTC)
- Hello, KamranMackey! As I've noted in my edit summary, I'm not sure what was actually wrong with the Scheme infobox example in the
{{Infobox programming language}}'s documentation? However, if you insist, I can live with the Python infobox example. Speaking of the reference errors, as you've already noted in your edit summary (and what's nicely visible in this diff), it was about having undefined named reference tags that caused a number of messages in red at the bottom of the page, which are clearly visible in this revision. — Dsimic (talk | contribs) 02:07, 8 May 2015 (UTC)
File:IO stack of the Linux kernel.svg
Hi Dragan, after updating the Linux Storage Stack Diagram, I've found now that you put quite much effort in correcting typos in the former old version of the diagram (I've found the discussion at Wikipedia:Graphics Lab/Illustration workshop/Archive/Apr 2015 § A high-level overview of the Linux kernel's I/O stack). Thank you for your work here! We plan to update the diagram to Kernel 4.0 in the next 2 weeks, I'll include your feedback there. Best regards, Wfischer (talk) 09:06, 8 May 2015 (UTC)
{kind=link}
- Hello, Werner! You're welcome, and thank you for creating such a great high-level overview in the first place! The least I could do was to improve the diagram's wording, and it would be awesome if you would incorporate all those improvements into the next version. I hope you'll also upload the next version to File:IO stack of the Linux kernel.svg. :) — Dsimic (talk | contribs) 09:41, 8 May 2015 (UTC)
{kind=link}
- Your're welcome, too ;-) Of course we will include your valuable feedback (I didn't read through all the feedback yet, but will do so when we update the diagram). And yes, we will upload the next version to File:IO stack of the Linux kernel.svg afterwards ;-) Wfischer (talk) 11:38, 8 May 2015 (UTC)
- Sounds great, thanks! — Dsimic (talk | contribs) 11:51, 8 May 2015 (UTC)
- We have updated the diagram to version 4.0 and updated the SVG File:IO stack of the Linux kernel.svg. I hope we have catched all of your hints. If you have any further feedback, let me just know. Wfischer (talk) 10:49, 8 June 2015 (UTC)
- Thank you very much, the diagram looks much better with its slightly cleaner layout and all of the wording cleanups. However, I'd have at least a dozen more suggestions on how to improve the wording, and I'm willing to prepare a complete list if you're willing to incorporate all of them. :) Also, having some kind of a credit on your web page would be nice. — Dsimic (talk | contribs) 21:20, 8 June 2015 (UTC)
Parallel ATA
Peripheral devices do not "primarily interact with humans". Anything outside of the CPU and main memory is considered a peripheral device. This includes hard disk drives and tape drives. Note the wording in the standard, quoted in the section on ATA-2. Jeh (talk) 19:15, 17 May 2015 (UTC)
- Hello! As far as I've been taught about it, peripheral devices collect and present information in human-readable form, and that's what I've referred to in my edit. Surely, I'd need references to cover that, but some of the available online sources go as far as describing RAM as a peripheral device, what's an absolute nonsense (like this one, for example, but I've seen another one that explicitly calls RAM a peripheral device). RAM should be a peripheral device, while a PSU isn't? Then what about laptops and small-form-factor computers having their PSUs as power bricks? — Dsimic (talk | contribs) 19:32, 17 May 2015 (UTC)
- While looking at the quotation in Parallel ATA § EIDE and ATA-2 section, it's clear that the ATA-2 standard defines a device as "a storage peripheral". However, I'm not sure how much is that enough for the general definition of peripheral devices, as other available sources don't make much sense by putting almost everything into that category. — Dsimic (talk | contribs) 19:47, 17 May 2015 (UTC)
- A PSU is not a peripheral device. Nor is RAM. By what I was taught about it, backed by numerous computer makers' product literature from which I've spec'd major installations, storage devices are peripherals. Recent marketing trends have been to list human interface devices as "peripherals" and not e.g. hard drives, but that is a recentism. If you write data to it or get data from it with I/O commands, it's an I/O device and therefore a peripheral, whether or not the device presents or accepts data in human-compatible form. Jeh (talk) 19:58, 17 May 2015 (UTC)
- Hm, but you can also use I/O commands to communicate with a fan speed controller or a SATA controller, for example, which are part of a modern computer motherboard. Furthermore, you can even use I/O commands to talk to a CPU's integrated memory controller. That should classify those few examples as peripheral devices, but I'm not sure how much they are. Of course, all this isn't that much important, but I'd say it's an interesting thing to be discussed. :) — Dsimic (talk | contribs) 20:33, 17 May 2015 (UTC)
USB type-C redirect
Why did you revert my change at USB Type-C when a section named "USB Type-C" of the redirect's target exists? Someone added the section to page USB last month. At the time you created USB Type-C as a redirect, it was not there. I redirected to USB#USB Type-C so that readers could focus directly on USB Type-C. I also moved the anchor TYPE-C to the section, in which I placed {{Anchor|USB Type-C}} inside. I have already checked the edit history of the redirect page before I updated the redirect. Give reason for reverting other than to repeatedly say Explicit anchors are preferred, as they stay effective even if sections are renamed in your edit summary. --24.6.161.63 (talk) 23:29, 18 May 2015 (UTC)
- Hello! As explained in my edit summary you've quoted above, I've reverted it because explicit anchors (those introduced by the
{{Anchor}}template) are much better in redirects than section titles. If the article sections are renamed later, split into two or more (sub)sections or altered in another way, explicit anchors are moved to appropriate new positions in the article (exactly as you did it after USB § USB type-C subsection has been split off from USB § USB 3.1), with already existing redirects still working without requiring any changes to them. - Furthermore, there are more redirects pointing to the same position in the USB article, including the USB Type-C, USB type-C and Type-C redirects, and all of them simply continue to work as expected after the explicit "TYPE-C" anchor is moved to a new position within the USB article. With all that in mind, there should be no reasons not to use explicit anchors in redirects. Hope you agree. — Dsimic (talk | contribs) 07:25, 19 May 2015 (UTC)
- I am sorry for errors in my above message. Actually, what I meant is "USB Type-C", which is intentional. I incorrectly redirected the page USB Type-C to the anchor USB Type-C as the subsection's title is case-sensitive, but the anchor worked naturally. The actual formatting header where I modified is
====={{Anchor|TYPE-C}}USB type-C=====. The "TYPE-C" anchor seems to be customary by you, but you are not only one that prefers this. I notice that another editor created a redirect as USB#TYPE-C at page Type-C. I mean the text USB#TYPE-C. - The subsection at the USB article was added when the new Apple MacBook, which has only one USB 3.1 Type-C port, was out for sales. (See the article MacBook (2015 version).) The "TYPE-C" text had remained inside a parameter of the {{Anchor}} template for about another month, until I edited and then saved the page. It is now inside the sub subsection header.
- As for your edits to USB Type-C, you have used the same edit summary twice. What do you mean, "explicit" you use to modify noun "anchor"? I assume most editors redirect a page to a native anchor like "USB type-C", rather than "customary" anchors like "TYPE-C" that do not exactly match title of any section header. Native anchors in wiki are tags that render an exact title's section link naturally.
- I have to disagree with your version. Do you think they do the same or redirect a page to a section title naturally? --24.6.161.63 (talk) 22:37, 19 May 2015 (UTC)
- I am sorry for errors in my above message. Actually, what I meant is "USB Type-C", which is intentional. I incorrectly redirected the page USB Type-C to the anchor USB Type-C as the subsection's title is case-sensitive, but the anchor worked naturally. The actual formatting header where I modified is
- I just checked your recent contributions, and noticed you changed "Type-C" to "type-C" across the USB article. That confused me at the time of my previous writing above. --24.6.161.63 (talk) 22:52, 19 May 2015 (UTC)
- No worries about the errors. Everything I wrote above is based on my experience here – I've seen numerous broken redirects because the sections they have pointed to got renamed etc. Moreover, people tend to create redirects to sections, and place comments such as
<!-- Some redirects point here, do not modify. -->right below the sections such redirects point to. That's simply wrong, as nobody knows later how many such redirects are there in case such sections need to be renamed, and that requires digging through the "what links here" to keep such redirects working. In other words, IMHO things people do naturally are not necessarily the best things to do. - Speaking about the "explicit anchors" in my edit summaries, "explicit" modifes "anchor" so it refers to anchors explicitly added to articles, by using the
{{Anchor}}template, instead of the anchors implicitly created as a result of placing section headings. Maybe that wouldn't be everyone's choice of a modifier, but it seems logical to me: implicitly means that something hasn't been required explicitly. — Dsimic (talk | contribs) 22:55, 19 May 2015 (UTC)
- No worries about the errors. Everything I wrote above is based on my experience here – I've seen numerous broken redirects because the sections they have pointed to got renamed etc. Moreover, people tend to create redirects to sections, and place comments such as
- The template is not needed because the
{{Anchor|TYPE-C}}text would appear between /* and */ (which renders section linking) in edit summaries. It is undesirable, unlike tags such as <this>. The page should redirect directly to a section currently named "USB type-C", not "TYPE-C", which I think is too broad. It is unclear to me whether the capitalized term most commonly refers to a new type of USB. --24.6.161.63 (talk) 23:28, 19 May 2015 (UTC)
- The template is not needed because the
- Why should it be important how it looks in edit summaries offered by default when editing sections? It's about the redirects, not about edit summaries. — Dsimic (talk | contribs) 23:33, 19 May 2015 (UTC)
- Because it breaks a section link in an edit summary, just like removing the template from a section header while an explicit anchor is linked from a redirect, it breaks the anchor link as well. --24.6.161.63 (talk) 00:05, 20 May 2015 (UTC)
- There are no actual section links in edit summaries. — Dsimic (talk | contribs) 00:20, 20 May 2015 (UTC)
- Yes, they do. For example,
/* {{Anchor|PD|PD-R1.0|PD-R1.0V1.1|PD-R1.0V1.2|PD-R2.0V1.0}}USB Power Delivery */ The devices have increased power requirements, not increased energy requirements, fixed error.generates "→{{Anchor|PD|PD-R1.0|PD-R1.0V1.1|PD-R1.0V1.2|PD-R2.0V1.0}}USB Power Delivery: The devices have increased power requirements, not increased energy requirements, fixed error." in edit summary. Clicking the "→" will take us to that section, but there is no such section called "{{Anchor|PD|PD-R1.0|PD-R1.0V1.1|PD-R1.0V1.2|PD-R2.0V1.0}}USB Power Delivery" in the USB article. (diff link) That is what it is broken if the section is in fact "USB Power Delivery". Regarding one of your edits to the USB article, did you actuallly delete the part of "{{Anchor|TYPE-C))" in edit summary when you edited the section "USB Type-C", in this diff? --24.6.161.63 (talk) 06:02, 22 May 2015 (UTC)
- Yes, they do. For example,
- That's a good point, I've never examined those right arrows available in edit summaries. However, IMHO that slight inconvenience isn't a good enough argument against using explicit anchors. Yes, I always trim section "hints" offered by default in edit summaries so they contain only the section titles, as that makes them much more readable in edit histories. — Dsimic (talk | contribs) 18:57, 22 May 2015 (UTC)
PCI Express article illustration
I added this cause it is not a simple closed 1x connector and the photo quality is better than the present one. Somebody disrupted the description and the you removed it. --Hans Haase (有问题吗) 21:22, 20 May 2015 (UTC)
- Hello! As I've described it in my edit summary, positioning of the File:PCIe J1900 SoC ITX Mainboard IMG 1820.JPG picture looked rather bad in the lead section, and there's already a picture of different slots in the PCI Express § Form factors section. Though, unfortunately I've missed the fact that the picture shows an open-end ×1 connector, sorry for that and thank you for pointing it out! Thus, I've readded the picture into the PCI Express § Physical layer section, where it should fit rather well. Hope you agree. — Dsimic (talk | contribs) 21:46, 20 May 2015 (UTC)
{kind=link}
Multitasking for newbies
Not to discredit your efforts, you totally missed the point, i.e., education of newbies. The frames of a motion picture were included to explain the multitasking concept to newbies who are likely to misconstrue the term multitasking, said term often being interpreted as simultaneous, e.g., texting and driving, in the popular media. The CPU, no matter how configured, must interleave chunks of multiple processes. Just as a camera switching back-and-forth between incomplete scenes will.
Note: My object is to make the concept clear and comprehensible, not to impress fellow IT professionals with recondite distillations of fact. For a professional who does not need it, your definition suffices. However for a newbie, it's too tight, and self-contradictory, even. That said, I'm butting out, as you've made quite a spectacular effort at various corrections, and I honestly don't have the time to engage. We'll go with your edit. But it, no offense, could be better. 99.246.121.36 (talk) 00:16, 22 May 2015 (UTC)
- Hello! Regarding my edit on the Computer multitasking article you're referring to, I still think that such analogies are rather redundant. True, Wikipedia articles should be written in a way that requires no prior knowledge, but how far should that be stretched? If stretched far enough, each article could be started with an introduction of the English alphabet. :) Also, the rest of the Computer multitasking article provides a rather good further overview, so everyone going all the way through the article should end up with a solid grasp of the concept of multitasking. — Dsimic (talk | contribs) 00:46, 22 May 2015 (UTC)
- Here's an attempt at making the Computer multitasking's opening paragraph more readable and understandable; IMHO, any further "dumbing" of the initial description would be rather pointless. — Dsimic (talk | contribs) 01:12, 22 May 2015 (UTC)
Arduino official website
Thank you for diff 663477834. Please, check the global edits of the user, this was massive change in several wikis (I fixed ru: and de:) - [7] a5b (talk) 02:28, 22 May 2015 (UTC)
- Hello! You're welcome, and IMHO only including both arduino.cc and arduino.org is as neutral as possible. If there's a later resolution of the currently ongoing legal dispute, we can update the Arduino § External links section so it contains only one link to the official website. — Dsimic (talk | contribs) 19:03, 22 May 2015 (UTC)
Hack of {{n/a}}
Hi Dsimic! I did partially revert your changes to Standard RAID levels and Nested RAID levels. I do not see that use of the {{n/a}} template as being the intended use, since in neither table are the cells actually not applicable.
If your concern is that the {{Depends}} and {{Unknown}} templates are too boldly formatted, I happen to agree with you. However, I don't agree that the appropriate fix is hacks or manual cell formatting on the article side; rather, the template should be changed (with discussion, of course) so that your concern is addressed globally, and consistently. – voidxor (talk | contrib) 20:44, 22 May 2015 (UTC)
- Hey, Voidxor! On second thought, I agree that using
{{Depends}}and{{Unknown}}templates is much better than "customizing" the{{n/a}}template. However, those two templates might benefit from a modification that would make them stand out less, which applies especially to the{{Unknown}}template that makes the table in Nested RAID levels § Comparison section look almost funny. Though, that might be just up to the table being almost empty? Perhaps the{{Unknown}}template actually looks good in tables with only a few empty cells, where its visual appeal is actually desirable, so it shouldn't be modified at all? — Dsimic (talk | contribs) 21:06, 22 May 2015 (UTC)
| Current look | — | ? | Unknown | Depends |
|---|---|---|---|---|
| Proposal #1 | — | ? | Unknown | Depends |
| Proposal #2 | — | ? | Unknown | Depends |
- Thank you, switching to
{{Dunno}}makes the table look much less "busy". I've been thinking more about those templates, and it might actually be good to have a little bit more "flashy"{{Unknown}}template so it actually draws attention of people who might actually fill in the voids. That way, once the empty cells in Nested RAID levels § Comparison section lose their majority status, we might actually want to go back to{{Unknown}}. - However, in my opinion it might be good to make all those templates a little more uniform. A small comparison I've prepared here contains two proposals: #1 turns the text color into gray in all templates, while #2 turns it into black. IMHO, having them all in gray looks better as more subtle, but there are numerous other templates (such as
{{Yes}},{{No}},{{Good}}or{{Bad}}, as visible in Template:n/a § Templates, for example) so turning the text in the only exception (which is{{n/a}}) into black might be actually more feasible. Thoughts? — Dsimic (talk | contribs) 11:39, 24 May 2015 (UTC)
- Thank you, switching to
| Proposal #3 | — | ? | Unknown | Depends |
|---|
- Sorry for the delay in responding; I've been off wiki. In my opinion, non-answers to table cells should indeed use gray text. If you think about it,
{{Depends}}is actually a possible answer, whereas{{Dunno}}and{{Unknown}}are for cells in need of answers, and{{n/a}}is for cells that will never receive an answer. Therefore, I would vote for graying-out{{Dunno}}and{{Unknown}}as is shown in proposal #3, yet leaving{{Depends}}and{{n/a}}as is. We might make{{Dunno}}and{{Unknown}}<small>to further lessen their busyness. - Also,
{{Dunno}}and{{Unknown}}serve the same purpose. I would support a merging these redundant templates. One would simply be redirected to the other to keep existing code working. – voidxor (talk | contrib) 23:22, 28 May 2015 (UTC)
- Sorry for the delay in responding; I've been off wiki. In my opinion, non-answers to table cells should indeed use gray text. If you think about it,
| Proposal #4 | — | ? | Unknown | Depends |
|---|---|---|---|---|
| Proposal #5 | — | ? | Unknown | Depends |
| Proposal #6 | — | ? | Unknown | Depends |
- No worries about the slight delay, there's no hurry. That's a very good point – with such color-coding in place, gray and black colors would clearly indicate whether a cell is a fill-in request or not. The only thing I'd add to your proposal is that
{{n/a}}should have its label in black (as visible in the proposal #4), as that template represents pretty much a definitive answer: "not applicable" or "not available" (for the latter, in the sense of "no such thing", not "unknown"). How about that? Of course, I'd support the merger between{{Dunno}}and{{Unknown}}templates. — Dsimic (talk | contribs) 23:54, 28 May 2015 (UTC)
- No worries about the slight delay, there's no hurry. That's a very good point – with such color-coding in place, gray and black colors would clearly indicate whether a cell is a fill-in request or not. The only thing I'd add to your proposal is that
- Since "not applicable" means the cell doesn't apply, I still regard it as a non-answer. The difference between it and
{{Dunno}}/{{Unknown}}is that the latter can be answered. However, I don't really care if{{n/a}}uses black text or gray. I feel much more strongly that{{Dunno}}and{{Unknown}}could stand to be merged, grayed out, and made<small>. The appropriate place for such a discussion appears to be Template talk:Table cell templates. I'll let you make the proposals, after which I will vote. It might be wise to reference this discussion in your proposal, so that we disclose our working together and brainstorming beforehand. – voidxor (talk | contrib) 05:17, 29 May 2015 (UTC)
- Since "not applicable" means the cell doesn't apply, I still regard it as a non-answer. The difference between it and
- Speaking about merging
{{Dunno}}and{{Unknown}}, a thought about why the merger might not be favorable just crossed my mind: different cell widths. In other words, having two templates that produce "fill me in" cells with labels of completely different widths might actually be good so the narrow one can be used where the space is tight, and the wide (and more descriptive) one where the space isn't an issue; that's somewhat similar to how MOS:DATEFORMAT allows month names to be abbreviated in tables. Also, here are the proposals #5 and #6 above, which show how those two templates look with<small>, and to me they look much better that way. - I had pretty much the same thoughts about starting a discussion on an appropriate template talk page by putting up a few proposals while referencing our work done so far in this discussion. I'll go ahead with that. — Dsimic (talk | contribs) 07:00, 29 May 2015 (UTC)
- Speaking about merging
- Just got the discussion started, please see Template talk:Table cell templates § Less busy-looking templates. — Dsimic (talk | contribs) 07:57, 29 May 2015 (UTC)
ShareSpace foundation
Dear Dragan: given my established interest in a re-integration of art and technology, I've started an article on the ShareSpace foundation. Should be interesting to see how it's received.Synchronist (talk) 04:39, 23 May 2015 (UTC)
- Hey Glenn! The article looks fine and it's quite interesting, thumbs up for creating it; it's also well-referenced, what's very important. I just did a few small cleaups, hope you're Ok with that. Just as a note, page views statistics for the article are available from stats.grok.se/en/latest90/ShareSpace_foundation, allowing you to see how much traffic the article receives over time. — Dsimic (talk | contribs) 05:03, 23 May 2015 (UTC)
- Speaking of which, Dragan, there don't seem to have been any updates on the page view statistics for this article, nor for several others I've checked, since May 23rd (and today being the 31st). I realize that these stats are described as "very much" a beta feature, but can you comment? Or is there somewhere I should have looked first for this internal Wikipedia news? Peace, brother. Synchronist (talk) 22:26, 31 May 2015 (UTC)
- You're right, unfortunately there's no page views data on stats
.grok .se for the last seven days. Those statistics are unofficial and there's history of data missing for a few days from time to time, which is usually generated retroactively; however, in the last two years or so I haven't seen the data missing for that long, so something strange must be happening. Well, at least it's free so we can't complain too much. :) — Dsimic (talk | contribs) 22:47, 31 May 2015 (UTC)
- You're right, unfortunately there's no page views data on stats
- @Synchronist: Just as a note, stats
.grok .se is now back to its fully operational state, working much faster than before. It must have been migrated to more powerful hardware. — Dsimic (talk | contribs) 07:15, 6 June 2015 (UTC)
- @Synchronist: Just as a note, stats
- I did notice, Dragan, and I've been closely following the page view statistics for ShareSpace foundation -- they are quite curious, and, if you have the time, and if it does not seem too politically incorrect, I'd like to know what you make of them. (I have my own theory, but I don't want to bias your interpretation.) Synchronist (talk) 01:25, 12 June 2015 (UTC)
- The initial May 23–24 spikes on stats.grok.se/en/latest90/ShareSpace_foundation may freely be attributed to various web crawlers hitting a new Wikipedia article. Later statistics are simply page views, counting how many times the article has been accessed on each day, excluding all of the possibly existing redirects. Some kind of a rule of thumb I'd apply is that halving the daily page views gives the number of different people accessing the article. Of course, I'd really like to hear your theory, if possible. :) — Dsimic (talk | contribs) 06:02, 12 June 2015 (UTC)
- Dragan, you may well be right about the bots. My theory focuses on the inner circle of Sharespace and its new affiliate, Destination Imagination: word spread quickly among this inner circle that a Wikipedia article had been started on the foundation; but preoccupied with the mention of Aldrin's environmental apostasy, they did not pass on the word to their thousands of rank-and-file members. BTW, the phrase "On the downside" was that used by Qwertyus to introduce a negative finding to my article on the BLAST protocol. Much more I could say about all of this -- Wikipedia is indeed a fascinating phenomenon! -- but enough for the moment. Synchronist (talk) 23:06, 13 June 2015 (UTC)
- Right, it could be very easily an inrush of page visits initiated by the ShareSpace foundation itself – it seems that people like to see somebody else creating a Wikipedia article about something they're or have been working on. :) Another fact supporting your theory is that the initial peak spanned two days, while the crawlers usually get their work done within a few hours. I agree, Wikipedia is almost the eighth wonder of the world, especially because it's a volunteer effort, which might be attributed to the overall positive attitude of the humans as a whole, and the fact that many hands make almost any job easy. :) — Dsimic (talk | contribs) 12:43, 15 June 2015 (UTC)
Open vSwitch performance improvements
I noticed my input on performance improvement was undone. Could you please clarify and advise so I can update it so that it is acceptable? Thanks Rob — Preceding unsigned comment added by Robpater (talk • contribs) 01:45, 27 May 2015 (UTC)
- Hello! Regarding your edits on the Open vSwitch article, they haven't been undone; instead, I've extracted valuable parts from them and integrated those into the article. Please don't get me wrong, but the way you've described it sounded like some kind of a PR campaign, instead of remaining neutral and presenting significant facts about Open vSwitch.
- For example, Wikipedia articles shouldn't present that being "fast and efficient" is important for the "market success of Open vSwitch"; at the same time, weasel words such as "high overhead needs to be resolved to significantly improve throughput", "there have been a number of initiatives to accelerate OVS performance", or "efficient use of computing resources [...] without compromising performance predictability" add very little value to articles.
- What I've incorporated into the Open vSwitch § Features section, based on the references you've provided, should cover the facts about performance improvements well enough without going into unnecessary details. Hope you agree. — Dsimic (talk | contribs) 02:16, 27 May 2015 (UTC)
- Thanks! I did not notice your additions at first. What I was trying to convey is the move to carrier virtualization from IT virtualization, requires enhancements to OVS to become carrier-grade in terms of performance and scalability in order to meet the needs of the public network (ie for NFV). Do you think adding something along this line would be useful for the OVS page? If so your advice would be v helpful. Thanks Rob Robpater (talk) 01:15, 28 May 2015 (UTC)
- You're welcome. IMHO, for now it might be better to leave such descriptions to the Network functions virtualization article, as the Open vSwitch article in its current form doesn't go too deep into various aspects. Also, recent "hot" work on improving the performance of Open vSwitch seems to be taking place in a couple of commercial products that keep their descriptions rather blurry and at the level of PR announcements. At the same time, PR announcements in general border with what's considered reliable sources as companies almost always tend to be a little biased in their PR announcements. Hope you agree. — Dsimic (talk | contribs) 03:27, 28 May 2015 (UTC)
Init, runlevels and modern Linux distributions
There are no run levels in most modern Linux anymore so the "Default runlevels" should be trimmed down (the edit you reverted) or marked as historical. Please let me know your thoughts.--Tim (talk) 14:35, 27 May 2015 (UTC)
- Hello! In my opinion, it should be better to mark those descriptions (the one in the Init article, and, perhaps, the other one in the Runlevel article) as tied to particular Linux distribution versions instead of simply deleting them. Older versions of those distributions, which don't use systemd, are still supported and used in different environments; for example, CentOS 5 is still widely used and it comes with the traditional init. Thoughts? — Dsimic (talk | contribs) 03:45, 28 May 2015 (UTC)
A side note related to {{Official website}}
I am sorry for the edit conflicts caused. I need to be offline for a while. I'll catch up with the discussion later. -- Magioladitis (talk) 23:50, 31 May 2015 (UTC)
- Hello here as well! :) No worries, having a few edit conflicts is perfectly fine and that's always to be expected in an active discussion. See you later. — Dsimic (talk | contribs) 23:55, 31 May 2015 (UTC)
Flexible array member in g++
The value is: it avoids people telling "but it _does_ work in c++!!!" (because their gcc accepts it). Sources? Well, I just found something about "zero length arrays" as a GNU extension for pre-99 C. It does not mention C++ for this feature. :-( --RokerHRO (talk) 15:00, 4 June 2015 (UTC)
- Hello! As we know, everything in Wikipedia needs to backed by reliable sources and none of them were provided in this case, which is the reason why I've removed that content from the Flexible array member article. If you could provide sources, which I've been unable to Google out, adding that content back to the article would be more than welcome; otherwise, it's better not to include unsourced information. — Dsimic (talk | contribs) 22:16, 4 June 2015 (UTC)
Your recent additional HDD external links
Hi Dismic: U recently added to the HDD External Links section three articles covering quite low level HDD technical details. There are hundreds of such articles going back many years so I wonder if such detail is appropriate for Wikipedia? If so, where do we stop? Didn't want to just revert without talking - yr call. Tom94022 (talk) 17:34, 6 June 2015 (UTC)
- Hello! That's a very good point about the three external links I've added as part of some of my latest edits on the Hard disk drive article. Believe me or not, I had similar thoughts as yours while adding those three entries, and here's what my thoughts looked like:
- See, those are rather fine papers describing some of the modern HDD technologies...
- ... but why don't we have those technologies already described in Wikipedia?
- Well, maybe those aren't encyclopedic enough, but hey, they're widely used so even a formal notability check would pass.
- However, I'll add links to those papers, they're really nice.
- But hey, what it somebody else continues that and adds twenty more of such papers?
- Well, if that happens, then we'll trim the Hard disk drive § External links section; until then, it's rather safe and not growing out of control.
- Hope you agree. Of course, as always, I'm more than open to discussing this further. — Dsimic (talk | contribs) 22:15, 6 June 2015 (UTC)
- Hi! As HDD technologies go these three are really trivial points and the articles cited border on advertisements. Other vendors do or have done the same thing, just different names or not named at all. Furthermore, the three "technologies" linked are far less significant than other HDD technical areas such as, off the top of my head, perpendicular recording, carbon overcoated multilayer sputtered media, negative air pressure heads, thermal flying height control, TMR transducers, sector servos, dual stage actuators, PRML channels, headerless sectors, split sectors, fluid dynamic spindle bearings, dc spindle motors, etc. I could probably find an external article on each and more (some already have Wikipedia articles) but wouldn't that clutter up the article, and probably trim your three links as relatively unimportant. So let's just trim the three now and be done with it. Tom94022 (talk) 06:41, 8 June 2015 (UTC)
- Hm, why don't you instead add external links for some or all of the technologies you've listed above (as always, you've provided a rather impressive list)? Providing more information, even only in form of external links, can only add more value to articles. Also, no matter how relatively unimportant RAFF, TLER and PowerChoice may be, those are few of the terms consumers and enthusiasts use a lot, so we should provide at least some coverage of them – if you agree. — Dsimic (talk | contribs) 06:56, 8 June 2015 (UTC)
- I have other things to do, but I happened to stumble onto two such articles recently published by HGST so I put them up. IMHO, these two subjects are more notable, that is, far more concern to customers and enthusiasts and far more in common usage than RAFF, TLER and PowerChoice; the latter is a trademark of Seagate and not used much at all other than on Seagate products. Actually now that I think about it, it seems to me that RAFF, TLER and PowerChoice are not notable. The HDD industry participants have been publishing white papers for decades, some now on current webpages but many many more in the internet archive and still relevent but probably not notable. How many external links will it take for us to come to some sort of agreement? Tom94022 (talk) 17:33, 10 June 2015 (UTC)
- The two links you've added are perfectly fine, thank you. However, I'm slightly confused why RAFF, TLER and PowerChoice shouldn't be notable? Sure thing, they might not be notable in an academic or professional way, but they're widely used and there are numerous Google hits for them. Moving forward, I've moved the TLER entry to the Error recovery control article, and linked that article in the Hard disk drive § See also section; hopefully, that could be some kind of a compromise. — Dsimic (talk | contribs) 18:21, 10 June 2015 (UTC)
- RAFF has little usage outside of WD and descriptions thereof. Technically HDD servo mechanisms have used feed forward for many years to control vibration. Usage of HDDs in RAID cabinets causes somewhat more vibration but so what. This is WD marketing hype of no consequence to the reader of this article.
- PowerChoice is a trademarked term of Seagate's and technically should not be used without the TM symbol. Like RAFF it has little usage outside in this case Seagate and describes something that HDDs have been doing for years. This is Seagate marketing hype of no consequence to the reader of this article.
- I suppose my fundamental argument against these two is Wikipedia does not promote. — Preceding unsigned comment added by Tom94022 (talk • contribs) 20:48, 15 June 2015 (UTC)
- Well, then the mentioning of Helium-filled drives could also be seen as some kind of promotion, as currently only the WD's HGST division produces such devices. Furthermore, they're filled with Helium, "so what"? Why would readers benefit from such Helium-filled knowledge, which may also be seen as some kind of marketing hype? Please don't get me wrong, but the "so what" approach can easily be extended to the point where the whole Hard disk drive article is pretty much irrelevant. What I'd say is that every bit of information counts, even in form of such external links; though, it would be much better to have some prose in the article, for which those external links would be converted into references. — Dsimic (talk | contribs) 08:26, 16 June 2015 (UTC)
- Well, I agree Helium is also not notable, just a little bit more notable than the others because it is an Engliish word, not a marketing concoction and there was at least one other prior helium filled drive. I'm happy to delete all three. :-) Tom94022 (talk) 23:50, 18 June 2015 (UTC)
- Any chances, please, for you to introduce some prose into the article and use those three links as references? I still think that countering the vibrations (RAFF), power management mechanisms (PowerChoice etc.), and advances in platter counts (Helium) deserve to be covered at least briefly. Having that as part of the article should really help the readers seeking for such information. — Dsimic (talk | contribs) 05:46, 19 June 2015 (UTC)
Hack (programming language)
Deleting OCaml software category wasn't justified IMO. Look here: https://github.com/facebook/hhvm/tree/master/hphp/hack/src. It's almost entirely written in OCaml and that category is specifically for such cases. 89.42.64.133 (talk) 10:26, 11 June 2015 (UTC)
- Hello! As noted in my edit summary, though not clearly enough which I apologize for, Hack isn't something that is "written" using another programming language. As we know, Hack is a programming language specification so its reference implementation, the HipHop Virtual Machine (HHVM), may be added into the Category:OCaml software, which is now the case. In more detail, it's that a few Hack's type-checking utilities bundled together with the HHVM are written in OCaml; see the build instructions and a description of those utilities for further information. Moving forward, I've explained the whole thing further in the HipHop Virtual Machine article. Also, Category:Facebook software doesn't apply to Hack, which I've replaced with Category:Facebook – as a programming language specification, Hack isn't software per se.
- Thank you very much for pointing this out, and I hope that you agree. — Dsimic (talk | contribs) 08:09, 12 June 2015 (UTC)
- Ok, thanks.
- While what you are saying is true - it's somewhat a simplification. When there is only one implementation exists - it is an implementation and the language itself. The specification is tied to the implementation unless it's maintained by some independent body. BTW, HHVM can be used without Hack, but not vice versa. And the only significant novelty of Hack is its' use of types IMHO. 93.117.158.8 (talk) 10:57, 12 June 2015 (UTC)
- You're right to a certain degree, but what's written in OCaml are only a few Hack's type-checking (hh_server and hh_client) and code-formatting (hh_format) utilities, which are only helpers and completely non-vital for executing Hack programs inside HHVM. In fact, these utilities don't particiate at all in the execution of Hack programs, they just analyze the source code to help programmers. In other words, Hack's reference implementation works perfectly fine without the helper utilities written in OCaml. Furthermore, HHVM ships together with some Emacs plugins written in a dialect of the Lisp programming language, but those are also non-vital – otherwise, we could also say that small parts of Hack are written in Lisp. — Dsimic (talk | contribs) 18:43, 12 June 2015 (UTC)
- I was actually referring to the statement that a specification can't be written in a programming language. The role of OCaml is not important here.
- As for importance of the helpers. Well, without them Hack turns from a statically typed language to basically PHP. 89.37.46.114 (talk) 22:06, 12 June 2015 (UTC)
- Sorry, I don't get what do you mean by "a specification can't be written in a programming language"? Formally it can't, but the official implementation of a programming language can serve as its specification, that's been the case with PHP for years, for example. Hack's helper utilities should be there to aid programmers, nothing more, while the gradual typing nature of Hack is what's to be implemented within the HHVM. HHVM executes the code, helper utilities merely do preflight checks to make it easier for programmers; if it's instead that HHVM actually ignores the typing information (unfortunately can't verify that at the moment), then it would be a total piece of crap. — Dsimic (talk | contribs) 01:38, 13 June 2015 (UTC)
- Here's what the Hack's documentation says on how to go through the process of converting existing PHP code to Hack:
- Make as much PHP code visible to the type checker as possible.
- Guess type annotations with a global inference tool, but log when they fail instead of failing hard.
- Parse error logs and remove annotations that do not match at runtime.
- Make the remaining annotations fail hard at runtime.
- Here's also a quotation from the same documentation page on how to "harden" type annotations, that is, turn them from
@-prefixed warning-generating "soft" parameter or return type annotations into regular annotations that generate recoverable errors:- Once annotations have been added, the logs from the "soft" failures can be automatically parsed to remove the annotations that mismatch at runtime, and to turn the annotations that match into hard failures. Good places to collect such logs include unit test runs and even from production.
- With all that and the additional descriptions in the above linked documentation page, it can be confirmed that HHVM does perform type checking at runtime. As a result, type-checking utilities are just helpers non-vital to the actual code execution. They do help a lot, though. :) — Dsimic (talk | contribs) 02:29, 13 June 2015 (UTC)
- Here's what the Hack's documentation says on how to go through the process of converting existing PHP code to Hack:
Enlist your help to make U.2 (SFF-8639) page great!
Hello, we noticed you have edited lots of the storage pages (M.2, SATA Express) and wanted to give you the inside scoop on U.2 and enlist your help to make the wikipedia page great! I started a draft U.2 (SFF-8639) page that is in review by Wikipedia. I don't really know what I'm doing on Wikipedia though. I am the product marketing manager for Intel's data center SSDs, and have been driving the direction of the storage market. You can see my knowledge of storage ecosystem here: http://www.nvmexpress.org/presentations/
News on U.2: http://www.tomshardware.com/news/sff-8639-u.2-pcie-ssd-nvme,29321.html
Any way to expedite the process of review so we can start editing it up? I also have no clue how to upload pictures.
You can reach out to me on LinkedIn if that works for my email. — Preceding unsigned comment added by Jmhands (talk • contribs) 00:21, 18 June 2015 (UTC)
- There are a few things on the SATA Express page that are incorrect. I regularly meet with the board of directors of SATA-IO and NVM Express, and personally know the authors of the spec. :) I can help you clean them up. — Preceding unsigned comment added by Jmhands (talk • contribs) 00:13, 18 June 2015 (UTC)
- Hello, and thank you very much for reaching out! I'll be more than happy to see a great new U.2 article, and I'm more than willing to help in making that happen. However, the current U.2 (SFF-8639) draft has some issues, please let me name a few that stick out:
- The draft doesn't include enough good references (for example, the PCIe 3.0 reference is rather out of place), and at the moment pretty much doesn't satisfy the article notability requirements.
- The writing style doesn't comply to the Wikipedia's Manual of Style in a few places, which isn't a major issue but would still require some work.
- Being employed by Intel, especially in its marketing department, :) puts your contributions to Wikipedia on the conflict-of-interest side of things, which may complicate everything a lot.
- The article name should be "U.2" instead of "U.2 (SFF-8639)" as the parenthesis would indicate some kind of disambiguation that doesn't exist in this case.
- Based on my Wikipedia experience so far, my suggestion would be to wait a week or two with turning the U.2 draft into an article, so the U.2 gets more coverage in third-party sources. With just a tad better coverage in reliable sources, the notability and other requirements should be satisifed and we'll make it a great article. Here are a few more good references I've found, and we need just a few more of them:
- In the meantime, I'd suggest that we work on correcting the SATA Express article, and I'll be so happy to incorporate all of the fixes you have in mind. Speaking of that, I'd recommend that you point out factual mistakes, provide better sources, etc., and have me review and incorporate them; that way, we'll make the article better while avoiding any possible conflict of interest and maintaining the article neutrality, which is one of the Wikipedia's file pillars. Hope you agree.
- Speaking of uploading images, that's somewhat complicated so please allow me to explain. In order to have images uploaded, you need to make sure they aren't copyrighted in any way or published somewhere else; some copyrighted images may be uploaded as well, but numerous imposed restrictions effectively make such images unsuitable for the SATA Express, M.2, U.2 and NVM Express articles. The simplest thing would be taking a few product pictures by yourself, which Wikipedia refers to as "own work"; for example, two better pictures of M.2 cards, one with a few different M.2 types and another showing a side-to-side comparison with an mSATA card, would be really great. If you're Ok with that, I'll walk you through the uploading process that isn't complicated per se – what's slightly complicated is making sure uploaded images comply with various guidelines. :) — Dsimic (talk | contribs) 05:34, 18 June 2015 (UTC)
- Hello, and thank you very much for reaching out! I'll be more than happy to see a great new U.2 article, and I'm more than willing to help in making that happen. However, the current U.2 (SFF-8639) draft has some issues, please let me name a few that stick out:
- Here's an update... In the last two weeks or so I've collected a few good references, and I'll be writing the U.2 article in the next few days. It should be rather good and informative. :) — Dsimic (talk | contribs) 06:51, 8 July 2015 (UTC)
- That would be fantastic! Can you reach out to me via email or LinkedIn and I can provide you with the latest sources? Intel will be presenting lot of new information at the Intel Developers Forum in Aug on U.2. — Preceding unsigned comment added by Jmhands (talk • contribs) 13:02, 30 July 2015 (UTC)
- Also there isn't a conflict of interest here, I just have the history on the name. U.2 will not be trademarked in any way. Intel proposed the U.2 name to both the SSD Form Factor Working Group and SCSI Trade Association, and will soon be adopted by the PCI-SIG as well. I just wanted to you to get the definitions correct. A U.2 drive (either SSD or HDD) has a link of PCIe x1, x2, or x4 as defined in the SSD form factor spec: http://www.ssdformfactor.org/docs/SSD_Form_Factor_Version1_a.pdf. They will soon be updating the spec to reflect the U.2 name changes. The spec does not dictate the max power or z-height of the drive (common ones will be 2.5inx15mm and 2.5inx7mm). A U.2 connector can support either PCIe, SAS, or SATA and can be at the end of a cable or on a backplane (common in server and workstation). A U.2 cable is anything used to connect a U.2 drive. The first U.2 cables will be using SFF-8643 (minSAS HD) to connect to the motherboard. We will call these U.2 connectors. Sorry I suck at wikipedia, hopefully you can reach out to me. Thanks!! Jmhands (talk) 13:22, 30 July 2015 (UTC)
- Just as a note, I do remain committed to writing the U.2 article, but in the last week or so I'm bogged down with reviewing an increased amount of changes to the articles on my watchlist. A few times per year there are significant spikes in the editing activity on computing-related articles, and now it seems to be one of those spikes. It would be great to have even more sources on U.2; is this your LinkedIn profile?
- Moreover, I've researched virtually everything that's publicly available about the Intel's current U.2 product line, and here's an interesting observation: why no U.2 cables are included with the DC P3500, P3600 and P3700 U.2 SSDs? Of course, those U.2 SSDs are primarily intended to be plugged into U.2 backplanes, so no need for cables has been projected, but many desktop people (myself included) would prefer a DC P3500 instead of a 750 series U.2 SSD. Though, finding a separate U.2 cable seems to be pretty much an impossible mission, so the choice of desktop people is limited to one of the 750 U.2 series SSDs, which come bundled with U.2 cables. — Dsimic (talk | contribs) 14:03, 30 July 2015 (UTC)
- For the sake of completeness, and to move them out of my to-do notes, :) here are the other sources I've collected so far:
- http://rog.asus.com/415802015/asus-gaming-motherboards/intel-750-2-5-inch-ssd-with-nvme-and-asus-hyper-kit/
- https://pcdiy.asus.com/2015/04/asus-z97-x99-motherboards-intel-750-series-nvme-ssds-all-you-need-to-know/
- http://www.servethehome.com/4-solutions-tested-add-2-5-sff-nvme-current-system/
- http://web.archive.org/web/20150730174117/https://forums.servethehome.com/proxy.php?image=http%3A%2F%2Fstatic4.ithome.com.tw%2Fsites%2Fdefault%2Ffiles%2Fimages%2FSFF-5.png&hash=2e800814bba6396a5bfa37b14e9251db
- http://www.intel.com/content/dam/www/public/us/en/documents/product-specifications/ssd-750-spec.pdf#page=14
- http://www.tomshardware.com/reviews/intel-750-series-ssd,4096-2.html
- They're quite informative. — Dsimic (talk | contribs) 17:42, 30 July 2015 (UTC)
- For the sake of completeness, and to move them out of my to-do notes, :) here are the other sources I've collected so far:
{kind=link}
- Here are more sources, showing that some Z170-based computer motherboards are announced to have U.2 connectors available directly on their PCBs, beside regular SATA and SATA Express connectors:
- By the way, got distracted with writing the Stagefright (bug) article in the meantime, which is still under construction for another few days, but the U.2 article is next on the list. :) — Dsimic (talk | contribs) 13:42, 6 August 2015 (UTC)
Welcome to the AfC team!
Hi, and welcome to WikiProject Articles for creation! We are a group of editors who work together on the Articles for creation and Files for upload pages.
A few tips that you might find helpful:
- Please take time to fully read the reviewers' instructions before reviewing submissions.
- The reviewers' talk page is the best place to ask for help or advice. You might like to watchlist this page, and you are encouraged to take part in any discussion that comes up.
- Article submissions that need reviewing can be found in Category:Pending AfC submissions and there is also a useful list which is maintained by a bot.
- You might wish to add {{AFC status}} or {{AfC Defcon}} to your userpage, which will alert you to the number of open submissions. There is also a project userbox. If you haven't done so already, please consider adding your name to the list of participants.
- Several of our members monitor Wikipedia's help IRC channel, and you are welcome to join in to ask Wikipedia-related questions.
- The IRC channel #wikipedia-en-afc connect is used occasionally for internal discussion regarding the Articles for Creation process, and also serves as a recent changes feed, displaying all edits made in the Articles for Creation namespace.
- The help desk is the place where new editors can ask questions about their submissions. You are welcome to help in answering their questions.
Once again, welcome to the project. Anastasia [Missionedit] (talk) 21:56, 19 June 2015 (UTC)
Deep learning article
Dragan, the entirety of my contribution to Deep learning was removed two days ago (see https://en.wikipedia.org/wiki/Special:Contributions/99.42.64.25 ), and the only reason I mention it to you is because I'm not sure this action was on the "up and up". But if you don't have the time to take a look, I'll see if maybe QWERTYUS can step in. Ironically, this removal of material linking art and AI comes at a time when there is a huge new burst of interest in the subject; see, for example http://www.theguardian.com/technology/2015/jun/18/google-image-recognition-neural-network-androids-dream-electric-sheep. Synchronist (talk) 03:23, 20 June 2015 (UTC)
- Hello! You shouldn't be worried too much about that edit on the Deep learning article, such content deletions happen from time to time. Above all, if that edit were honest and performed by someone really knowledgeable, would he or she use such language for the edit summary? Maybe, but that usually wouldn't be the case. Here's my suggestion how to handle the whole thing:
- Restore the deleted content by undoing the edit, describing briefly the reasons in your edit summary.
- Start a discussion on the article's talk page, referring to the content removal and describing the used reference, mentioning another source you've linked above (which contains quite amazing and at the same time a tad disturbing depictions, by the way), etc. That way there should be more editors from the field to discuss the whole thing, review the content and possibly improve it, etc.
- You may also want to ask one of the administrators (perhaps Acalamari would be willing to have a look) to check whether hiding the slightly offending edit summary would be appropriate, as there's no need for even low-level incivility.
- Again, "don't panic", as it stands on the cover a well-known fictious book. :) — Dsimic (talk | contribs) 04:18, 20 June 2015 (UTC)
- Done as per your guidelines; can't thank you enough for rescuing my weekend! Synchronist (talk) 03:03, 21 June 2015 (UTC)
- You're welcome, and I'm glad it helped. :) If I may provide another suggestion, it would be good to include a link to the article diff you're referring to in the Talk:Deep learning § Art and AI discussion; that way, other editors joining the discussion will know immediately what is it about. You may simply use a complete link to the diff page (such as this one), or even better use the
{{Diff}}template to have a link like this one. It is also advisable to always provide brief edit summaries; for example, this edit would benefit from a brief description. Hope you agree. — Dsimic (talk | contribs) 05:11, 21 June 2015 (UTC)
- You're welcome, and I'm glad it helped. :) If I may provide another suggestion, it would be good to include a link to the article diff you're referring to in the Talk:Deep learning § Art and AI discussion; that way, other editors joining the discussion will know immediately what is it about. You may simply use a complete link to the diff page (such as this one), or even better use the
- Gotcha in respect to identifying the offending edit on the article talk page; but in respect to the missing edit summary, I was a little afraid of retroactively adding such due to all of the scary warning messages -- it might be like going back in time and stepping on a mushroom! Synchronist (talk) 15:08, 21 June 2015 (UTC)
- Furthermore, edit summaries belong to the small "one-off" category of things here at Wikipedia: they can be specified only when an edit is made, can't be added or edited once an edit is saved, and existing ones can only be hidden. Sure thing, edit summaries aren't carved in stone by some magic, :) they're database records as everything else while there are simply no web interface elements allowing their modification. In fact, changeable edit summaries would introduce a rather endless recursion as there should be a revision history for the summaries themselves, and then second-level edit summaries should be provided while editing original edit summaries, etc. :) — Dsimic (talk | contribs) 17:41, 21 June 2015 (UTC)
Your Two's complement edits
Can you read what your placing Not only inaccuracies but anything true stated in devious misleading manner. Did you just copy it from somewhere? If you are not intentionally doing what I have stated above. Slow down and Read what I have summited and see if you really have understood how to state what's going on When represent signed numbers (grade school + or - integers) by what are integers in this S_N_R. Michael Ali theturk (talk) 07:43, 20 June 2015 (UTC)
- Hello! Regarding your edits on the Two's complement article, please do realize that they pretty much haven't introduced improvements to the article – just see what the article looks like with your edits in place. See all that broken formatting? Furthermore, could you please, for example, explain why have you removed the tables containing examples of three- and eight-bit integers? — Dsimic (talk | contribs) 07:55, 20 June 2015 (UTC)
- (talk page watcher) @Michael Ali theturk: When discussing an articles content, it is generally best to do so on the articles talk page. That way, other interested editors can see the discussion and participate. —Godsy(TALKCONT) 07:58, 20 June 2015 (UTC)
- Totally agreed. This could be seen as an initial discussion regarding the brief back and forth on a few reverts between Michael Ali theturk, ArnoldReinhold and myself, but further article-related discussion should continue on Talk:Two's complement. — Dsimic (talk | contribs) 08:05, 20 June 2015 (UTC)
SO-DIMM article
Thanks for planning on adding more references! I appreciate it, it'll measurably improve the article. --Yamla (talk) 19:23, 25 June 2015 (UTC)
- Hello! You're welcome, and thank you for bringing up the lack of references. Having that list as part of the SO-DIMM article is actually very usable, will get the references added later today as promised. :) — Dsimic (talk | contribs) 19:55, 25 June 2015 (UTC)
- Done as promised – added a total of eight new references, rescued an already existing one by using its archived version, and did some smaller wording cleanups. Please check it out. — Dsimic (talk | contribs) 04:03, 26 June 2015 (UTC)
Virtual machine article split
Hi Dragan,
The Virtual machine was a mash of 2 distinct concepts, with essentially no overlap: system virtual machine (OS virtualization etc.) and process virtual machine (JVM etc.). Thus I split them into two articles, and was in the process of cleaning them up. Shall we discuss at the article talk page? — Preceding unsigned comment added by Nbarth (talk • contribs) 17:21, 28 June 2015 (UTC)
- Discussion started at Talk:Virtual machine#Split into separate pages for systems and process? —Nils von Barth (nbarth) (talk) 17:30, 28 June 2015 (UTC)
- (edit conflict) Hello! I'd say that leaving the Virtual machine article as-is might be better than turning it into some kind of a disambiguation and moving its content to the System virtual machine and Process virtual machine articles. The way Virtual machine article describes those two concepts is rather understandable to the readers, so it should be better to leave them together – that way, readers can grasp both concepts rather well without the need to shuffle through three articles. However, I'd suggest that you start a discussion on Talk:Virtual machine following the WP:SPLIT guideline, so we hear opinions from more editors. — Dsimic (talk | contribs) 17:33, 28 June 2015 (UTC)
HDD article reverts without discussion on talk page
Discussion on the talk page could improve the article (better than reverting mindlessly). If you find that quality adjusted price information from the Federal Reserve Board is in wrong section, I thing that moving it to the right section would help.71.128.35.13 (talk) 22:27, 7 July 2015 (UTC)
- Hello! You're right and I apologize for not starting the discussion earlier. Please have a look at my reply in Talk:Hard disk drive § Editing reliable information and removal of speculation; hopefully, we'll reach an acceptable compromise. — Dsimic (talk | contribs) 22:37, 7 July 2015 (UTC)
Patrolled user page
Hello - I got a notice that said User:217IP was patrolled by Dsimic. Could you clarify what this means? I am unfamiliar with it in the context of users - normally people patrol pages for changes. Thanks! 217IP (talk) 15:49, 9 July 2015 (UTC)
- Hello! Patrolling new pages is nothing out of ordinary, ;) it's a Wikipedia's "quality control" mechanism ensuring that new pages are checked against major issues, such as insulting material, copyright violations, obviously misleading stuff, or unsatisfied notability criteria. In this particular case, a few hours ago I had a look at your user page, saw that it hasn't been patrolled yet while having no issues, so had it marked as patrolled. See Wikipedia:New pages patrol for further information. — Dsimic (talk | contribs) 16:13, 9 July 2015 (UTC)
- I guess I'm still confused - why would a user's page need to be quality controlled? It doesn't seem like user pages ever have contentious material and don't have issues with notability or reliable sources. I am not very familiar with user pages, but isn't it just a space to talk about myself if I wished to do so? 217IP (talk) 16:59, 9 July 2015 (UTC)
- User pages are technically no different than other page types, and some people put all kinds of stuff there. In the end, that's how MediaWiki works and treats them, despite the fact that the content of user pages is almost entirely each user's discretion. See Wikipedia:User pages for futher information (WP:UPNOT describes what isn't allowed on user pages, for example). — Dsimic (talk | contribs) 17:13, 9 July 2015 (UTC)
- Please correct me if I'm wrong, but it seems to me that by patrolling my user page, you are singling me out and saying "I am going to keep a close eye on you" and attempt to exert control over what I decide to include on my user page. Considering user pages very rarely seem like a point of contention for anyone, this sort of comes across to me as WP:WIKIHOUNDING: "with an apparent aim of creating irritation, annoyance or distress to the other editor". I am not accusing you of this, and I assume good faith, but this is sort of how it looks to me (admittedly a novice). If patrolling user pages, especially those which you are in disagreements with on other articles, is normal for Wikipedia, then I apologize for insinuating bad faith. 217IP (talk) 17:20, 9 July 2015 (UTC)
- No way. I even haven't added your user page to my watchlist. All I care about is the content of articles, and that's what the Wikipedia:No personal attacks guideline clearly says. — Dsimic (talk | contribs) 17:28, 9 July 2015 (UTC)
- I do sincerely apologize then - you are welcome to remove this from your talk page if you like. I asked another person and patrolling user pages seems like a totally normal thing. I appreciate your patience and civility. 217IP (talk) 17:37, 9 July 2015 (UTC)
- No worries. There's no need for removing this discussion as everything on Wikipedia happens with no concealment. Also, it's always the best to clearly and as early as possible express and discuss any concerns – that's what keeps a work environment healthy. Welcome here! :) — Dsimic (talk | contribs) 17:44, 9 July 2015 (UTC)
Intel microarchitectures (July 2015)
Hello,
You have deleted several mentions of Kaby Lake because it is a rumor. However, you have not deleted all the additions of 670221421 ("Cannonlake ... put on hold indefinitely") and 670668783. Please be consistent. Also, I do not understand the comment of 670598820. What is the complete sentence? Especially, what "doesn't fit" with what? Visite fortuitement prolongée (talk) 19:17, 9 July 2015 (UTC)
- Hello! Thank you very much for pointing out what I've somehow managed to miss in the Skylake (microarchitecture) article, got it fixed now. Sorry for that, but I'm still only a human, and humans tend to make mistakes. :) Regarding the Intel processor roadmap template, it simply wasn't on my watchlist so I haven't seen its recent changes; however, got it fixed as well so everything is now in a consistent state.
- Speaking of my edit on the Intel HD and Iris Graphics article, it's about whether the Intel microarchitectures category applies or not. As we know, "microarchitecture" is a term coined by Intel for referring to the way a processor architecture (which boils down to either IA-32 or x86-64) is implemented in a specific processor generation. With that in mind, there's no architecture to which Intel HD and Iris Graphics would be a specific implementation. That might be debatable with the recent trend toward integrating GPUs and CPUs into the same package, but they're still rather independent units (even in the HSA, a GPU is still only a better-integrated separate unit).
- Sorry for not describing it in more detail in my edit summary, which pretty much wasn't possible in such a limited amount of space, and I hope you agree with the category removal. — Dsimic (talk | contribs) 01:00, 10 July 2015 (UTC)
- Thanks for fixing Skylake (microarchitecture) and Template:Intel processor roadmap. Case closed for now.
- "Microarchitecture is a term coined by Intel for referring to the way a processor architecture [...] is implemented in a specific processor generation." → With this definition, all pages in Category:Graphics microarchitectures should be un-categorized from Category:Microarchitectures, and Category:Graphics microarchitectures should be deleted. Please be consistent. Visite fortuitement prolongée (talk) 19:37, 10 July 2015 (UTC)
- Right, things are in a consistent state now, until (and if) Intel confirms the Kaby Lake rumors. Also, please be aware that I can't do everything in advance before replying on my talk page, so I'm really having difficulties to understand what do you exactly mean by "please be consistent"?
- Just had a look at those categories you've referred to, and it seems that we might be having larger issues than the categorization under Graphics microarchitectures category. In particular, it seems that articles such as Fermi (microarchitecture) or Kepler (microarchitecture) might not be describing GPU microarchitectures; instead, they seem to be describing GPU architectures. For the Fermi to actually be a microarchitecture, we'd need to know which exact ISA or GPU architecture it implements (even Nvidia refers to Fermi as an architecture, see this whitepaper, for example). However, I'm not sure whether the Parallel Thread Execution (PTX) could be seen as the actual ISA/architecture, especially because it has multiple versions; if that's the case, calling Fermi a microarchitecture would be perfectly fine, and that should be clarifid in the article(s). Thoughts? Perhaps Jesse Viviano could give us a hand here? — Dsimic (talk | contribs) 22:40, 10 July 2015 (UTC)
- "Please be aware that I can't do everything in advance before replying on my talk page" → Of course.
- "I'm really having difficulties to understand what do you exactly mean by "please be consistent"?" → I mean applying the same treatement to similar pages. For example, both Intel GMA and Intel HD and Iris Graphics pages are about "a series of Intel integrated graphics processors", both had Category:Graphics processing units, Category:Graphics microarchitectures, Category:Intel microarchitectures, but you removed the later only from Intel HD and Iris Graphics. Consistency say that both or none should have Category:Intel microarchitectures.
- "Even Nvidia refers to Fermi as an architecture" → Indeed, and Google find much more "Maxwell architecture" and "Graphics Core Next architecture" than "Maxwell microarchitecture" and "Graphics Core Next microarchitecture". Now I am confused. Visite fortuitement prolongée (talk) 19:51, 11 July 2015 (UTC)
- I totally agree that the same "structural" changes should be applied to all related articles and templates, but the problem is that I don't have all of them on my watchlist, and I'm even unaware of all of them. Though, that's why Wikipedia is a true team effort, and working together we'll do everything consistently and as accurately as possible. Hope that you agree.
- The primary trouble with architecture vs. microarchitecture is that "microarchitecture" is a term that has been pretty much coined by Intel, so it might be that the other manufacturers are avoiding to use it even if that would be the right choice, finding its use potentially confusing etc. Perhaps we should seek for other editors' opinions, but I'm not sure which talk page would be the right place? Any ideas, please? — Dsimic (talk | contribs) 23:53, 11 July 2015 (UTC)
- Sorry, I am not familiar with the talk pages. Visite fortuitement prolongée (talk) 19:18, 12 July 2015 (UTC)
- Kaby Lake has been confirmed. Visite fortuitement prolongée (talk) 19:05, 16 July 2015 (UTC)
- Thanks for the reminder, I'll review all changes made to the related articles a bit later. — Dsimic (talk | contribs) 00:09, 17 July 2015 (UTC)
Blade (templating engine) listed at Redirects for discussion
An editor has asked for a discussion to address the redirect Blade (templating engine). Since you had some involvement with the Blade (templating engine) redirect, you might want to participate in the redirect discussion if you have not already done so. Compassionate727 (talk) 19:00, 10 July 2015 (UTC)
- Thank you for bringing it to my attention, I've cast my vote there. — Dsimic (talk | contribs) 20:51, 10 July 2015 (UTC)
Run-time polymorphism
A tag has been placed on Run-time polymorphism, requesting that it be speedily deleted from Wikipedia. This has been done under the criteria for speedy deletion, because it is a redirect from an implausible typo, or other unlikely search term.
Please do not remove the speedy deletion tag yourself. If you believe that there is a reason to keep the redirect, you can request that administrators wait a while before deleting it. To do this, affix the template {{hangon}} to the page and state your intention on the article's talk page. Feel free to leave a note on my talk page if you have any questions about this. Compassionate727 (talk) 19:56, 10 July 2015 (UTC)
- First of all, you're not supposed to remove speedy deletion tags for pages you've made. Also, I see that neither "run-time polymorphism" nor "run-time" are mentioned on polymorphism (computer science). What makes the redirect worth having? Compassionate727 (talk) 20:01, 10 July 2015 (UTC)
- Hello, Compassionate727! I'm confused, what's going on here? This redirect is perfectly fine, there's essentially nothing wrong with it; will explain in more detail a bit later. Also, why are you tagging a whole bunch of redirects with
{{R with possibilities}}when there simply isn't enough encyclopedic content available to justify separate articles? That isn't helpful. — Dsimic (talk | contribs) 20:03, 10 July 2015 (UTC)
- Hello, Compassionate727! I'm confused, what's going on here? This redirect is perfectly fine, there's essentially nothing wrong with it; will explain in more detail a bit later. Also, why are you tagging a whole bunch of redirects with
- Ok, got the redirect improved by changing the redirect link from Polymorphism (computer science) to Polymorphism (computer science) § Static and dynamic polymorphism. Please don't get me wrong, but checking the suitability of a redirect with a simple Ctrl+F usually isn't enough. — Dsimic (talk | contribs) 21:17, 10 July 2015 (UTC)
Talk:Virtual disk
Hi. This is Codename Lisa! I missed you during my absence. How do you do?
If it isn't much trouble, could you please take a look at the move discussion in Talk:Virtual disk? I feel it needs more contributors and I have already tried all channels of notification short of inviting interested parties. (Hopefully, you count as a potentially interested one.)
Best regards,
Codename Lisa (talk) 07:40, 18 July 2015 (UTC)
- Hello! I've noticed that you haven't been too active recently, it's really good to have you back! :) Speaking about myself, well, I'm chuggin' along as always... Just had a look at Talk:Virtual disk § Requested move 11 July 2015, and I need to think a bit more about the whole thing, including how it goes along with the Disk image, Logical disk, RAM drive and other articles. Will come back with an update later. — Dsimic (talk | contribs) 09:08, 18 July 2015 (UTC)
- Sorry for the delay, my opinion is now part of the move discussion. — Dsimic (talk | contribs) 12:09, 19 July 2015 (UTC)
- Hi again. Never mind the delay; looks "delay" is going to be middle name soon. "Codename Delay Lisa"!
 But you did well to invite additional editors. Thanks. Best regards, Codename Lisa (talk) 09:50, 25 July 2015 (UTC)
But you did well to invite additional editors. Thanks. Best regards, Codename Lisa (talk) 09:50, 25 July 2015 (UTC)
- Hi again. Never mind the delay; looks "delay" is going to be middle name soon. "Codename Delay Lisa"!
- Haha, it surely hasn't reached the point of becoming your middle name. :) You're welcome, and thank you for inviting me in the first place; hopefully, we'll reach a good compromise with the input from more editors now available in Talk:Virtual disk § Requested move 11 July 2015. — Dsimic (talk | contribs) 10:01, 25 July 2015 (UTC)
ipkg article and the NOTHOWTO guideline
What's the general or your personal gain, if you remove example use paragraphs such as mine from the ipkg article? It was far away from being a HOWTO. And is it really, really necessary to eliminate such paragraphs? I personally find it really convenient to have almost everything I need in a wikipedia article. You are not going to cut down the wikipedia to exactly your need, are you? --johayek (talk) 12:08, 21 July 2015 (UTC)
- Hello, and sorry for the slight delay in responding. Regarding my edit on the ipkg article, I've already described in the edit summary what's it about. In a few words, it isn't some kind of my own "crusade" as you've called it; instead, it's only about following the guidelines, out of which WP:NOTHOWTO clearly says the following (emphasis added):
- While Wikipedia has descriptions of people, places and things, an article should not read like a "how-to" style owner's manual, advice column (legal, medical or otherwise) or suggestion box. This includes tutorials, instruction manuals, game guides, and recipes. Describing to the reader how people or things use or do something is encyclopedic; instructing the reader in the imperative mood about how to use or do something is not. Such guides may be welcome at Wikibooks instead.
- Please don't get me wrong, I know that seeing someone delete your contributions creates unpleasant feelings, and I've experienced exactly the same myself. Though, the guidelines are there to be followed, no matter how convenient a disobedient approach might be. Furthermore, other articles have seen much larger deletions of howto-style content, please see this edit (or this one) on the mdadm article, for example, and Talk:mdadm § Purge for the associated discussion. — Dsimic (talk | contribs) 02:53, 22 July 2015 (UTC)
- The question remains, why you are making this your task, and also how you are selecting your targets. And do you also have constructive goals on your list? --johayek (talk) 10:41, 22 July 2015 (UTC)
- Quite frankly, I don't see the reasons for your obvious unfriendliness. As we know, we're all here do discuss everything and find the best possible solutions, but such abrupt Q&A sessions usually don't converge. However, here are the exact answers to your questions:
- "Tasks" like this one are every editor's obligation, simply because all articles are required to follow the guidelines and the Manual of Style as closely as possible. Thus, whenever an editor comes across an article that isn't as good as it could be, it's their duty to make appropriate improvements. Of course, any arising differences in opinions are to be discussed on talk pages.
- One part of my work here consists of reviewing changes made to the pages on my quite large watchlist, which is over 3200 pages long. Speaking of how I came across the ipkg article, I've seen it linked in one of the edits made to the Package management systems template I'm watching, so I had a look at the article to verify that it's linked in a correct context.
- Yes, I have many goals on my to-do list, but I'm really (and unfortunately) not sure whether your and my definition of "constructive" are compatible. My primary goal is to make Wikipedia better by writing new and improving already existing articles; those improvements may involve copyediting for better wording, new content additions, sourcing improvements, or changes toward better compliance with various guidelines.
- As already noted above, we're here to discuss and find solutions, but the discussion is the key. — Dsimic (talk | contribs) 02:34, 23 July 2015 (UTC)
- Quite frankly, I don't see the reasons for your obvious unfriendliness. As we know, we're all here do discuss everything and find the best possible solutions, but such abrupt Q&A sessions usually don't converge. However, here are the exact answers to your questions:
- Johayek, could having this description as part of the article be some kind of a compromise? By the way, the article could use some additional references. — Dsimic (talk | contribs) 15:58, 26 July 2015 (UTC)
Redirects and formatting
Minor redirects aren't bolded in WP:R#PLA. Widefox; talk 23:33, 24 July 2015 (UTC)
- Hello! Obviously, we had a not-so-smooth start here, so let's try to make things better. As I've already said in other discussions, if you remember that, I highly respect the gnoming work you're doing here, but please keep your common sense turned on instead of following the guidelines blindly.
- Applying some kind of formatting to the redirect terms is beneficial to the readers, and I've seen numerous articles that had redirect terms italicized. Moreover, what is a minor redirect and what isn't, is up to one's personal judgment and background; as a result, I find the "software licensing description table" redirect to be a major one, while you don't. Such a disagreement is somewhat acceptable and not a major issue, but please keep an (IMHO) important thing in mind: there are very few active contributors to the computing-related articles, so other editors should try to help them and promote friendliness, instead of focusing on nit-picking and aggravating whenever possible.
- If there's a disagreement about anything, we're here to discuss it and find a compromise, but the "guidelines-clad high-gliding bean counter" attitude I'm sensing from your side isn't the best possible approach. Please don't get me wrong, nobody's perfect, but that's why teamwork produces good results. — Dsimic (talk | contribs) 04:48, 25 July 2015 (UTC)
- Hi Dsimic, agree we all have to get along, and there's several overlapping articles. One way is to follow consensus which the guidelines are a written form of (so MOS, BRD, AGF). Going against consensus can be not very enjoyable here. It is a learning experience when an edit is challenged (undone). For instance, the original italic has no basis in MOS that I can see, so I undid that edit. The judgement of a minor or major redirect is somewhat subjective but it appears more minor than the MOS example in my opinion, you're welcome to gather more opinions which is preferable to edit warring. So that edit has two reasons not to be there. Taking a guess, the level of importance of the redirect would be something like a redirect with possibilities. Maybe it's worth taking it up with the MOS to make it explicit (so not subjective at all)?
- You've indicated above that you wish to connect with me and resolve for future. Welcome, no problem.
- It would help if you could re-read what you wrote above from my perspective, imagining that I had written it to you. I'd be interested in any comments. Regards Widefox; talk 08:59, 25 July 2015 (UTC)
- Believe me or not, I've already read my own words from your perspective while writing the reply above, and my additional comments would be that making small compromises as we go is the key. I can't recall exact examples at the moment, but I've disregarded more than a few guidelines while working together with other editors so we can reach a compromising solution, instead of blindly insisting on having the guidelines implemented. As we know, WP:IGNORE is also one of the policies, and keeping good relations with other editors is what actually makes Wikipedia better – we're all humans, and humans stay around while the guidelines change over time. Moreover, the same humans may alter the guidelines.
- Speaking of italicizing redirect terms, I've seen numerous articles that apply such formatting, and that pretty much makes it some kind of a de facto unwritten standard. Thus, I'd suggest that we start a discussion on Wikipedia talk:Redirect that would propose changes to the WP:R#PLA guideline so redirect terms are:
- Formatted in bold for major redirects, which additional instructions on how to decide if a redirect is major or not
- Formatted in italics for non-major redirects, which would help readers navigate visually upon a redirection
- Thoughts? Please, let's make things better, and let's smooth out our relationship here. Making small compromises is the key, IMHO. — Dsimic (talk | contribs) 09:30, 25 July 2015 (UTC)
- Come on, you know how it works here. There's nothing personal in my undoing your edit, the fact is that the edit isn't based on MOS or any consensus at all is it? Per WP:BRD you should have discussed rather than continue. Sorry you feel it's an improvement, I disagree. Suggest you get more opinions else it's one on one. Your style change suggestion may be a good idea, I'm skeptical as it would involve italicising many minor items based on navigation rather than worth per se.
- You've characterised my editing in a certain light above (it is pejorative, rather than I assume your intended aim to connect with me). I'm waiting for you to appreciate how that comes across, especially when you're still sticking to what amounts to a minor style departure of yours WP:DROP seems appropriate at this point. Widefox; talk 12:10, 26 July 2015 (UTC)
- If you show me the other italic redirects, I will review and possibly fix. Without links I can't comment. Widefox; talk 12:13, 26 July 2015 (UTC)
- Your skepticism about the style changes is perfectly fine, as I might be totally wrong with the whole idea about italicizing redirect terms. Though, the only way to see if that's a bad or good idea is to start a discussion on Wikipedia talk:Redirect, together with proposing more clues to be added for deciding what is a major redirect and what isn't.
- Regarding my "portraiting" of your Wikipedia work, well, you're publicly declaring yourself as a WikiGnome, and I've already told you that I also do a lot of "gnoming" myself, but I primarily contribute new content and do quite a lot of copyediting. Thus, it's clear that I do appreciate "gnoming" – otherwise, why in the world would I be doing that? Moreover, I've pointed out that new content contributors are very rare here, at least for computing-related articles, so the "gnomes" should try to keep good relationships with those few editors, instead of blindly following the guidelines. "Gnoming" is important for sure, but if there's no new content flowing in, there soon will be nothing to be broomed, "gnomed", or whatever.
- Let me tell you what would I've done if I were a "gnome", coming across a significant contributor that doesn't agree with some of my "gnoming": I'd friendly help him or her to start a new MOS discussion about the disagreement in style or formatting, instead of blindly insisting on following the guidelines. That's what I see as the basic principle of teamwork, especially when it's about a bunch of volunteers.
- Speaking about the examples of italicized redirect terms, I don't think that providing them here would be helpful. You'd just grab a red pencil and go over them removing all of the formatting, and that would just deepen this slight disagreement. — Dsimic (talk | contribs) 13:55, 26 July 2015 (UTC)
- WP:WORDSASWORDS "A technical term.." may indicate italics are useful in this case, although I'm not convinced. (Code) doesn't seem useful for this term. Bold really doesn't fit per above. Stylising due to a minor redirect is completely unconvincing per above.
- Just so you are aware, it's not "gnome", it's "keep your common sense turned on instead of following the guidelines blindly" (I do have common sense thank you) ""guidelines-clad high-gliding bean counter" attitude" (assuming an "attitude" is AGF, "bean counter" is pejorative), "other editors should try to help" (nobody has exclusivity on errors or helping). For the record, I didn't check/know MOS first so I couldn't have applied it "blindly", it was a common sense challenge to the edit that it looked unusual. Being as it is factually incorrect that I objected based on following rules, that whole logic is flawed and even if I had done the comments above are an AGF / civility. Now that's spelled out, I'll leave you to ponder why you didn't WP:BRD...Discuss when Reverted. That's enough on this from my perspective, OK. Widefox; talk 21:49, 26 July 2015 (UTC)
- On second thought, a reason to go with no additional formatting for the "software licensing description table" redirect could be that BIOS § Identification section starts with "Some BIOSes contain a software licensing description table (SLIC), a digital signature placed inside...", so the readers shouldn't be confused when redirected there. Though, such an arrangement (in which the redirect term is very close to the beginning of section) isn't always the case.
- Well, Ok, this should conclude our discussion. Moving forward, I'll make sure to exercise the WP:BRD guideline more strictly. — Dsimic (talk | contribs) 04:47, 27 July 2015 (UTC)
- Good stuff. Widefox; talk 09:08, 27 July 2015 (UTC)
A barnstar for you!

|
The Half Barnstar |
| For your cooperation with other editors while contributing to Wikipedia. I have seen many editors squabbling over minor edits. You are different. It seems to me that you focus your energy on improving Wikipedia rather than socializing. We need more people like you here. Keep up the good work. Chamith (talk) 12:30, 26 July 2015 (UTC) |
- Hello, and thank you very much! :) As you've described it, my primary goal is to make Wikipedia better, and every single edit counts no matter how minor it might seem. Surely, I also love to have good relationships with other editors, but the primary goal remains unchanged. — Dsimic (talk | contribs) 12:51, 26 July 2015 (UTC)
Booting article and the code for references
Hello, I've undone your undo of my edit. Please stop doing that. I've unified the reference style on that article. I can assure you that no one is reading the references in the source of the articles. Thank you, Dawnseeker2000 14:23, 31 July 2015 (UTC)
- Hello! Regarding your edit on the Booting article and the explanation above, well, I can assure you that the assessment of "no one is reading the references in the source of the articles" simply isn't true. :) I read the source code and there are surely more people doing the same thing (even you obviosly do that), and I find the source code for references much more readable in the "expanded" form. Unification is a good thing for sure, but a unification toward an inferior layout pretty much isn't. Moreover, if nobody reads the source code, why would the unification be important at all? Thus, your explanation seems to be slightly contradictory, if you agree. :) — Dsimic (talk | contribs) 14:36, 31 July 2015 (UTC)
- Of course we read them. I said that because references are often neglected in articles (drive by editors add whatever text that they want without them, for example) so please don't think that that was a serious comment. You may say it's inferior, but haven't given an explanation. I just don't think having the refs expanded like that scales well. For small or starting articles, fine, but as they get larger, it becomes unwieldy. You didn't expand all the references in the article; you only undid what I had done. If having them "more readable" is important (they're readable just fine inline) to you, I would expect that you would have changed all of them to the expanded view, but you didn't. Because of that, it doesn't seem to me that this is that important to you. It's not that important to me either, except in the articles that I care about. This one is not, and I'll remove it from my AWB runs, as I did the Android article. If it were an important issue to fix, I suppose there'd be hundreds of thousands of articles to "fix". Have a great day (morning here) Dawnseeker2000 15:08, 31 July 2015 (UTC)
- Well, you're right that it would've been much better if I had expanded all references in the article, but the whole Wikipedia was built one improvement at a time. "Inferior" in my explanation above referred to my opinion that the expansion makes source code of references much more readable, no matter how long or short an article is. However, I'll refrain from dwelling on just because you've already expressed no intentions to discuss this further. — Dsimic (talk | contribs) 15:28, 31 July 2015 (UTC)
PU2RC listed at Redirects for discussion
An editor has asked for a discussion to address the redirect PU2RC. Since you had some involvement with the PU2RC redirect, you might want to participate in the redirect discussion if you have not already done so. Sanpitch (talk) 14:41, 8 August 2015 (UTC)
- Thank you for bringing it to my attention, I've cast my vote there. Let's also ask Guy Harris to participate in the discussion, as he actually added the explanation of the "PU2RC" acronym into the Multi-user MIMO article. Moreover, whatever we decide on PU2RC should be also applied to the Per-user unitary and rate control redirect. — Dsimic (talk | contribs) 15:07, 8 August 2015 (UTC)
Shellshock – undid revision 675603800
Hi Dsimic,
I saw that you undid 675603800 on the Shellshock article:
Undid revision 675603800 by Regagain (talk) Those capable of producing patches and applying them on their own would be rather advanced developers, not ordinary users
I agree with you, however, I still think the current wording of this sentence is misleading, and even wrong. For the record, here's the quote from the source:
If you're an advanced enough user to have enabled the types of services that can be exploited by Shellshock, you're also likely advanced enough to turn those services off for now, or to patch bash yourself using Xcode.
Compare that with the sentence as it is right now:
Such advanced users are typically capable of turning the services off until a patch built using Xcode can be implemented.
It does not mean the same thing at all. I think we should update it to something like:
Such advanced users are typically capable of turning the services off until an updated is available.
Do you agree (or do you have a better suggestion? :-))
Regagain (talk) 17:47, 11 August 2015 (UTC)
- Hello! I've briefly thought about the whole thing further, and I'm really glad that you've brought it here for further discussion. Though, I'm not entirely sure that the referenced source is the best available, so let's have a look at a (lengthy) quote from another source that provides some much-more-to-the-point information:
- If your Mac shipped with Mountain Lion or Mavericks (i.e. you bought it in the last two years), it's highly unlikely your Apache web server is turned on. It also probably got turned off if you upgraded to a current OS X edition, so if you didn't take steps to reactivate it, your potential attack surface for Shellshock is smaller than it would be otherwise. [...]
- First, you need to make sure that you have Apple's Xcode development environment installed (the command-line tools alone are not sufficient). If you don't have Xcode, you can grab it for free from the Mac App Store – but be prepared to wait for a while, it's a 2.5 GB download. [...]
- You'll need my bash-fix script which you can download from GitHub, and you'll need to be logged into your Mac as an OS X administrator (if you're the only user of your Mac, your account is the administrator account). [...] The script will download the source to bash, patch it, compile it, install it, and replace the old instances of the bash and sh executables; it will prompt you for your password along the way, so keep an eye out for that.
- Apple will eventually issue an official fix for this problem (and these steps should not interfere with that in any way), but if you don't want to wait for Apple's fix, you can get started now.
- With all that in mind, you're totally right that the sentence in Shellshock (software bug) article is misleading as-is, and IMHO this should be a better wording (together with adding the above-linked source):
- Thoughts? :) — Dsimic (talk | contribs) 18:49, 11 August 2015 (UTC)
- Wow!! Sounds great! Please go ahead and update the article. :-) Really appreciative of your work! Regagain (talk) 20:23, 11 August 2015 (UTC)
- Thank you very much! Went ahead and propagated the changes from above into the article. — Dsimic (talk | contribs) 21:10, 11 August 2015 (UTC)
Bay Trail (August 2015)
Hello. You created Bay Trail (microarchitecture) sometime ago. According to the current version of Atom (system on chip), Bay Trail is a platform for the Valleyview chip. Visite fortuitement prolongée (talk) 12:32, 16 August 2015 (UTC)
- Hello! I'm glad that you've brought this issue here, thank you very much and let's see what to do. After having a more detailed look, it seems that the Bay Trail SoC family is built using the Silvermont microarchitecture, so I've corrected it that way in the Intel HD and Iris Graphics article. Could you, please, confirm that, and I'll ask for the Bay Trail (microarchitecture) redirect to be deleted as misleading? — Dsimic (talk | contribs) 12:47, 16 August 2015 (UTC)
- Here are a couple of sources confirming that:
- Please have a look. — Dsimic (talk | contribs) 12:58, 16 August 2015 (UTC)
- The misleading redirect is deleted now. — Dsimic (talk | contribs) 13:12, 16 August 2015 (UTC)
Preserved date stamps? Confused...
About this edit, I just used a script that does this all the time.. Must be ok? If you're right the script needs to be changed. Unless I'm sure you're right, I'll not be cleaning up after the script.. I might if I heard a logical/good reason.. Doesn't seem to matter much. comp.arch (talk) 09:11, 17 August 2015 (UTC)
- Hello! There might be something wrong with the script you're using, as the tag date stamps need to be preserved and that should apply to the {{Use mdy dates}} tag as well. That way, it's known since when the tag is in effect, for example when the article switched to a particular date formatting scheme (in case of {{Use mdy dates}}), or when additional references were requested (in case of {{More references}} or {{Citation needed}}). In the latter example, it's even essential to know when the tag was placed, so the unreferenced content may be removed if nobody provides references for an extended period of time. I'm having troubles to find a specific guideline covering this, but here's a quotation from {{Refimprove}}:
- If you decide to change the tag from Unreferenced to Refimprove, don't forget to update the date stamp in the tag.
- However, I've seen more than a few editors switching the date stamps back to initial values if they're changed by someone, and that's IMHO perfectly logical because it supports the actual purpose of the date stamps. Hope you agree. Thinking more about the script you're using, maybe it changed the date stamp because it actually cleaned up the date formatting in Chrome OS article? — Dsimic (talk | contribs) 10:01, 17 August 2015 (UTC)
- After reading the documentation of {{Use mdy dates}} template further and more carefully, it seems that the script you're using is perfectly fine. Those are actually the visit dates of script or bot runs and should be updated if any corrections were made since the last visit; here's a quotation from the template documentation:
- After being tagged, and bearing in mind article evolution, periodic script or bot runs clean up formats, correcting any new introductions since its last visit, and updating the visit date on the {{Use dmy dates}} template.
- With that in mind, I've reverted my edit on Chrome OS. Thank you for bringing this issue to my talk page! — Dsimic (talk | contribs) 10:12, 17 August 2015 (UTC)
- After reading the documentation of {{Use mdy dates}} template further and more carefully, it seems that the script you're using is perfectly fine. Those are actually the visit dates of script or bot runs and should be updated if any corrections were made since the last visit; here's a quotation from the template documentation:
Shellshock: afl-fuzz edit revert
https://en.wikipedia.org/enwiki/w/index.php?title=Shellshock_(software_bug)&oldid=676626126&diff=prev - actually, the reference is right after this sentence - just press ctr+f and enter "american" or "afl-fuzz". Do you still have anything against this edit? Deetah (talk) 10:39, 18 August 2015 (UTC)
- Hello! Just checked the source you've referred to, and yes, it covers the content you've added to Shellshock (software bug) article very well. With that in mind, I'd say that you should reintroduce the mentioning of american fuzzy lop, but this time with more context so the addition doesn't look like it's there just to serve as something justifying the linking to American fuzzy lop (fuzzer) article. :) Hope you agree. — Dsimic (talk | contribs) 11:00, 18 August 2015 (UTC)
- Got it described slightly better, so the readers can more easily understand what's it about. Looking good? — Dsimic (talk | contribs) 15:44, 18 August 2015 (UTC)
Renaming "Dynamic linker" to "Dsimic's article on dynamic linking"
You are one of the most extreme editors on Wikipedia. Instead of shortening the exteneded list a little (and not just to your own need) you are inconsiderately and simply reverting my contribution a little like a tyrant. Why don't you rename the article to "Dsimic's article on dynamic linking"? Who are you? A ingenious smart-ass professor in Computer Science?--johayek (talk) 12:24, 18 August 2015 (UTC)
- Hello! Well, I'm rather surprised with your reaction, despite the fact I've already explained my revert further in User talk:Johayek § Dynamic linker article and the "See also" list, opening myself for discussion while offering possible alternatives, etc. Please have a look at WP:SEEALSO for more information on how long "See also" sections should be, and I'll be more than happy to work together with you on shortening the list in Dynamic linker § See also (as it should be shortened further), or on creating a new navbox (which would be great). Furthermore, please let's focus on the content, not on the background of editors, just as WP:NPA clearly says. — Dsimic (talk | contribs) 12:44, 18 August 2015 (UTC)
- Got the Dynamic linker § See also section trimmed down to a reasonable size by removing what's already linked in the article body. Please have a look. — Dsimic (talk | contribs) 16:36, 23 August 2015 (UTC)
- @Johayek: Could you, please, explain why do you write stuff like this post on your Google+ profile, and this post on your blog? That's pretty much bordering with a personal attack, which is senseless. If you have any open questions regarding your and my work on Wikipedia, why aren't you discussing them in the proper place, which is various Wikipedia talk pages? The key is in discussing things and finding compromising solutions. — Dsimic (talk | contribs) 06:32, 26 August 2015 (UTC)
Signature changes
Could you please see bottom of those pages:
- User talk:McGeddon#Changing signatures
- Wikipedia talk:Courtesy vanishing#Problems with old signatures after vanishing accounts
— Preceding unsigned comment added by 31.223.130.175 (talk) 14:22, 23 August 2015 (UTC)
- Hello! Regarding one of your edits and one of my reverts on Talk:Computer data storage, I understand the overall intention of vanishing an abandoned account, but here's what WP:VANISH says about talk page signatures:
- References in the history of pages to the former username are replaced with references to the replacement username. Note that signatures (on user talk pages, article talk pages and project discussion pages) will not be changed, and will, by default, be redirected to the new user name. You can ask for this redirect to be removed.
- The above-linked discussion you've started on WP:VANISH should answer the question whether such changes to the signatures would be acceptable. In general, talk page posts shouldn't be edited in that way, especially not by an IP address – how do we know that behind the IP address is actually the owner of the to-be-vanished account? Hope you understand. — Dsimic (talk | contribs) 15:23, 23 August 2015 (UTC)
- See also WP:SUPPRESS, which describes the possibilities for hiding one's personal information. However, the name you're supposedly trying to hide is almost a generic name in Serbian language, pretty much like John Smith is a generic name in English, for example. :) Thus, IMHO you shouldn't be concerned too much about the possibilities for having "problems in next time", whatever that may refer to. — Dsimic (talk | contribs) 15:41, 23 August 2015 (UTC)
- You might want to redact that name: perhaps it's an idiosyncratic spelling, but I only get 279 google results for that "pretty much like John Smith" name, and they're mostly Wikipedia mirrors. --McGeddon (talk) 20:17, 23 August 2015 (UTC)
- Makes sense, deleted the name in my earlier post. It's really surprising to see such a low number of Google results, I would've expected a much higher one. — Dsimic (talk | contribs) 20:35, 23 August 2015 (UTC)
- "In general, talk page posts shouldn't be edited in that way, especially not by an IP address – how do we know that behind the IP address is actually the owner of the to-be-vanished account?"
- Do you have any Wikipedia references to support what you declared?
- I don't know how Wikipedia should prove that vanished account was acctualy mine. Maybe in this way: I have saved e-mail conversations with Fumitaka Joe who vanished (now we can say - partly) my accounts. And my name is mentioned there. — Preceding unsigned comment added by 31.223.130.241 (talk) 09:15, 24 August 2015 (UTC)
- Please read the WP:TPOC and WP:VANISH guidelines, they clearly say that talk page posts in general aren't to be edited once they're saved, especially the other people's posts (except for certain layout fixes), and that vanishing an account requires establishing one's identitity ("this will send a secure e-mail from your Wikipedia account so that the bureaucrats can verify that it is a legitimate request", "to verify you own the account", etc.). — Dsimic (talk | contribs) 09:29, 24 August 2015 (UTC)
- I contacted Oversight team twice regarding my requests for removing from Wikipedia and both times I got answer that it "does not meet the Oversight criteria" (among other reasons). Also, they replied that "the Oversight policy does not cover vanishing as such information was self-disclosed by you". I wrote this just for you, for being better informed in possible future similar cases. — Preceding unsigned comment added by 31.223.130.127 (talk) 12:00, 2 September 2015 (UTC)
- Thank you for the update, I'll keep it in mind for any similar cases in the future. I'm sorry to hear that your request has been refused, but it's true that you've disclosed that personal information yourself, which does complicate the whole thing further. — Dsimic (talk | contribs) 14:35, 2 September 2015 (UTC)
Prefetch buffer
Could you have a look at Wikipedia talk:WikiProject Computing#Help with merge. Someone seems about to do a copy-and-paste merge of Prefetch buffer into DRAM. Copy-and-paste merges are nearly always a bad idea and in this case the AfD outcome of a "merge" looks like an unwise conclusion to me at best. —Ruud 16:15, 24 August 2015 (UTC)
- Hello! Thank you for bringing it to my attention, my humble opinion is now available in the above-linked discussion. Please keep in mind that I'm not an expert when it comes to various low-level implementation details of different DRAM technologies, but I've tried to research the whole thing as meticulously as it is possible to do something like that in a few hours. — Dsimic (talk | contribs) 05:03, 25 August 2015 (UTC)
Self-promotion in citations by Zhanghaohit
In reply to this revert. In general I agree with you, but please see the edits made by this user: Special:Contributions/Zhanghaohit. This is a single-purpose account only promoting their own publications, often adding multiple links to the same article. This is a textbook example of WP:REFSPAM and should not be tolerated. -- intgr [talk] 08:41, 26 August 2015 (UTC)
- Hello! Thank you for pointing it out, just had a look at the list of edits performed by Zhanghaohit and you're right, it seems like someone doing self-promotion. Now I'm having some serious doubts because the In-memory processing article clearly needs more references, and the troublesome paper is a really good and comprehensive high-level overview of various in-memory data processing technologies, which is also published by IEEE that serves as the definition of a reputable association. Perhaps we shouldn't sanction an example of reference spamming by deleting references that are actually good and beneficial to the articles? — Dsimic (talk | contribs) 09:52, 26 August 2015 (UTC)
- Well you've seen the evidence, I'm OK with keeping the reference if you vouch for it.
- The in-memory processing article has always seemed to me like it needs a bunch of WP:TNT, but I don't care enough to do it myself. -- intgr [talk] 10:08, 26 August 2015 (UTC)
- The troublesome reference is really good, and could serve as a very good starting point for someone to do the article rewrite, which is in dire need. Of course, one would need more references, but this one provides a very comprehensive high-level overview. — Dsimic (talk | contribs) 10:16, 26 August 2015 (UTC)
Device file discussion
Please can you go and check the Device file article again and remove the unbalanced tag you added? As I’ve explained (again) on the Talk page for that article, Linux really does behave the same as traditional UNIX; the only difference is that, by default, it only creates block devices for disks (just as FreeBSD only creates character devices). The only Linux-specific aspect other than that is that, because character device behaviour is genuinely useful for disks, the Linux kernel added an O_DIRECT flag that you can use to open one of its block devices in raw mode (i.e. as if it was a character device). Well, that and the existence of the raw driver, which lets you explicitly create character devices for the benefit of software that doesn’t know about O_DIRECT. I’ve added coverage of those facts to the article, as well as a remark about the use of the term "raw device" (e.g. in the Solaris manuals) to refer to character devices; I’m pretty certain this addresses your concern about balance. – Ajhoughton (talk) 16:12, 28 August 2015 (UTC)
- Hello! Thank you for reaching out; sure thing, I'll review your latest changes to the article and provide feedback as a reply in the article's talk page discussion. I'll be more than happy to see that {{Unbalanced}} tag go away from the Device file § Unix and Unix-like systems section. :) — Dsimic (talk | contribs) 23:13, 28 August 2015 (UTC)
Talkback (Android Gingerbread)
Message added 16:40, 30 August 2015 (UTC). You can remove this notice at any time by removing the {{Talkback}} or {{Tb}} template.
Jerod Lycett (talk) 16:40, 30 August 2015 (UTC)
- Hello! Thank you for bringing it to my attention, I've already replied (and once again :) on the article's talk page. — Dsimic (talk | contribs) 17:24, 30 August 2015 (UTC)
Have some krill!
.jpg)
|
Antarctic krill |
| Penguins eat krill! (and some fish and squids) |
- Hello, and thank you very much – I like eating all kinds of fish! :) I'm glad that you've noticed some of my edits on the Linux kernel article; this one, which you've probably noticed, was merely a small cleanup, but this one, for example, should bring some value to the article. :) — Dsimic (talk | contribs) 14:17, 31 August 2015 (UTC)
Subsequent edits and their nature
Erm, re edits like this [8]. The syntax of my edit [9] was generated - so I suggest you take your "fix" up with the edit icon bar developers. The stats indicate that [10] we edit many similar articles. In fact, your edits are often closely following mine to the extent that I'm starting to feel that your edits are following my edits a bit too closely (see WP:HOUND). Does that chime with you? Widefox; talk 12:59, 5 September 2015 (UTC)
- Hello back! No, I'm just using my watchlist, which is currently quite large at slightly over 3,350 pages, to monitor changes made to a large number of pages, and it seems that we have common pages on our watchlists. It's just a peer review, and—as I've said more than once—the only thing I truly care about is the content of articles, which also includes syntax and layout of the Wiki code. In other words, I'm by no means following you, I'm "following" my watchlist.
- When you say something like that and even throw in some report that investigates me, well, it makes me unconfortable and I feel slightly bad because of spending a lot of time reviewing edits performed by other editors. I guess that people should in fact say "thank you" to me for doing that. Also, let's step back and have a look at your edit on the Traffic policing redirect – even if it's somehow automatically generated, doesn't it reflect someone's sloppy work? I'm sure you'll, on a second though, agree with that and revert your revert. I'd appreciate it a lot. — Dsimic (talk | contribs) 17:52, 5 September 2015 (UTC)
- As I've said, take up "sloppy" with the devs, not me. WP:CIVIL slap! From what I can see, there's two or three editors that have remarked about your edits not being conducive to collaborative editing (e.g. "#Piped links", "#Piped links (cont.)") Instead of turning my/our feedback around, it could be time to WP:LISTEN, stop nit-picking over trivial whitespace issues, and take it on-board. OK? I'm in full agreement with User:Thumperward (#Piped_links) but your still and persistently at it, and subtle isn't getting through, so it's plainspeak now. If you still cling to the idea that it's me, or that somehow you're doing "peer review" (of whitespace?!) seek a third opinion. In fact, you're already on fourth/fifth. Looking at the editor interaction stats (whitespace issues and overlap of articles I do uncontroversial gnome-like-cleanup on) I'm waiting for an indication the message is acknowledged. Widefox; talk 20:26, 5 September 2015 (UTC)
- There will always be disagreements between editors, and that's perfectly fine. No, I will not stop "nit-picking", as you call it; if those issues are as minor as you describe them, why don't you let them go? Please don't get me wrong, but I'm not on your payroll so you can order me to do anything. Also, please try not to use the "slap" word in that context, that's uncivil. — Dsimic (talk | contribs) 20:34, 5 September 2015 (UTC)
- (ec) Alternatively, if you have no control over your editing behaviour, then I'd have to know and check your watchlist when editing to avoid them which doesn't seem practical (and no, none of my edits above are from my watchlist).
- When there's a seeming consensus about these type of edits (and don't get me wrong, this is a minority of edits) then yes, you kind of do have to take onboard, else it will get escalated. The next whitespace nit-pick will be, OK? Widefox; talk 20:45, 5 September 2015 (UTC)
- "Don't do this again. It is pointlessly antagonistic. There is nothing which makes an editor look less suitable for collaborative development than this sort of idiotic revert war. The rationale behind keeping the case is that if the link is somehow transformed such that the piping is no longer necessary (such as in "Interface" in your example, where the pipe trick means the piped text can be omitted entirely in the edit) it doesn't accidentally enter wrongly-cased text. If you've some control issues with your life that you need to work out, do it somewhere else. Argh, and this was going so well." <- this was Thumperward, the same issue I raised with you. Nobody is agreeing with you, you may choose to ignore consensus, but that's your choice. Widefox; talk 20:48, 5 September 2015 (UTC)
- (edit conflict) If you feel an urge to escalate this, please do it right away. There are absolutely no guidelines that promote less readable Wiki code, and all edits should be looked at from the viewpoint of improvements they bring, no matter if it's about the article content or about the formatting of Wiki code. Also, there are no guidelines about the piping of article links and capitalization, so it's up to each editor's preference. — Dsimic (talk | contribs) 20:56, 5 September 2015 (UTC)
- Regarding the capitalization of piped links, here's an excerpt from one of my earlier comments about the whole thing:
- As already explained in § Piped links discussion above, there isn't a single guideline that could turn it into something more than a personal preference; thus, no approach is either correct or incorrect. As a result, once they're placed, it would be the best simply not to change the case of piped links.
- As you can see, I've offered what seems to be the most reasonable way to deal with it, and since then I haven't changed the capitalization of any already existing piped link. However, if you really feel an urge to escalate this, please feel free to do it without waiting for anything. IMHO, it's the best to deal with any issues as soon as possible. — Dsimic (talk | contribs) 21:38, 5 September 2015 (UTC)
- Regarding the capitalization of piped links, here's an excerpt from one of my earlier comments about the whole thing:
That argument is logically flawed - it's contradictory/mutually exclusive: it can't be both a) a trivial editor preference AND b) sloppy. It can't be both a} irrelevant AND b) important (enough to fix). Pick one. If a) then why do it, if b) where's the consensus? There's consensus for the opposite of your style changes. Crucially, it's the gratuitous and/or bogus nit-picking that's disruptive to collaboration. If you feel you must compulsively make these changes to a large watchlist, after being told not to by several editors, yes, it's LISTEN / WP:IDHT. You're an experienced editor, you know how it works here. Widefox; talk 11:52, 6 September 2015 (UTC)
- You're totally mixing apples and oranges. I've called "sloppy" the formatting of Wiki code in Traffic policing redirect, not the capitalization of piped links. Moreover, as already described above, I haven't changed the capitalization of any already existing piped link since our earlier discussions in February 2015. Got it this time? Those are two distinct things. — Dsimic (talk | contribs) 13:03, 6 September 2015 (UTC)
- Again...for each of these separate things, they can't be both a) sloppy/worth fixing AND b) editor preference / minor. It's simple, as long as the message that these edits are still annoying at least one editor (and good that some edits have stopped). That's the message, received? Thumperward asked you if you have a control issue in your life, that's how it comes across to me too. Widefox; talk 09:07, 9 September 2015 (UTC)
- I would appreciate if you would stay away from mixing in allusions toward my personal life, at least because you don't know me. As a note, I would also have quite a few things to say about what your personal inclinations seem to be, but I don't see the point of that because we're here to make articles better, nothing more. Furthermore, if I may say, your attitude is also annoying me quite a lot, but I really don't see why should your feelings be more important than mine? Please, be reasonable. — Dsimic (talk | contribs) 20:58, 9 September 2015 (UTC)
- Furthermore, please have a look at this edit on the Template talk:Clear talk page, which I've just stumbled upon on my watchlist. Clearly, there are more editors who prefer the style of Wiki code formatting I've applied to the Traffic policing redirect, which you've reverted with no valid reasons and pointlessly turned into drama. See, I'm not the only one who prefers some whitespace that results in more readable Wiki code. — Dsimic (talk | contribs) 01:14, 10 September 2015 (UTC)
- Look, this is frustrating - you do good edits. But, these ones just irritate me (and others). Continuing to pedantically argue the merit of these optional/irrelevant level of "doesn't matter" indicates it won't stop. Whitespace etc i.e. trivia is not the point. Changing from one form to another for the sake of it, especially with a CIVIL "sloppy" attitude is. Fine once or twice, but widespread combined with a large watchlist that overlaps with my edits is an issue, yes. Collaboration is. This feedback is. Further, it doesn't ingratiate yourself to mark your own stuff reasonable, and others as sloppy. (and did you take sloppy up with the right people yet? - maybe there's even a technical reason why it doesn't insert whitespace - have you checked? it's WP:AGF). Widefox; talk 11:08, 10 September 2015 (UTC)
- Sorry, I really don't get what do you want from me, apart from twisting my arm into some kind of your own set of rules, which simply doesn't make sense. As a matter of fact, some of your edits also irritate me significantly, so what? Again, you haven't answered my question: why should your feelings be more important than mine? Moreover, I don't do so many of those "whitespace" edits (so the "widespread" label doesn't apply), but you're making a whole lot of drama out of those few. Collaboration isn't a one-man show by its definition; thus, if you promote and mention collaboration a lot, you should be the one to make steps toward it instead of saying "stop it" repeatedly. As we know, those steps boil down to finding compromising solutions, but so far you haven't offered a compromising solution, which makes you not truly oriented toward collaboration.
- To answer your question about possible technical reasons for such "sloppy" redirect code, even the WP:REDIR, H:R and WP:RCAT guidelines suggest the use of whitespace, and those guidelines surely have regulars who know all of the technical background. However, I'm willing to investigate further; could you, please, specify what actually generated that redirect code? — Dsimic (talk | contribs) 13:29, 10 September 2015 (UTC)
Punctuation cleanup
Thanks for the fix on the semi-colon. Missed that! 206.82.167.3 (talk) 20:39, 15 September 2015 (UTC)
- Hello! You're welcome, that small fix in the Transport layer § Analysis section was like some kind of a cherry on top. :) Thank you for improving the wording in the first place! — Dsimic (talk | contribs) 20:47, 15 September 2015 (UTC)
On BRD and picking
By the way, I'd appreciate if you would try not to pick on me on every possible occasion; what I did here was pretty much fine and according to the WP:BRD guideline.
Your first instinct, every single time someone disagrees with you, is to revert to your preferred version. Every single time, whether you made a change initially or not. In cases like this guideline, this gives you precisely the first-mover advantage that BRD is designed to avoid. Combined with your utter intransigence regarding the most petty nonsense (like this explicit linking that that Widefox is discussing in vain with you once again above) this means that pretty much any article you're watching becomes de facto under your stewardship and thus that editing it takes an order of magnitude longer. What I really wish is that, as with 99.9% of other editors on the site, the very first thing that I did not see every single time you were involved in a discussion was a notification saying "Your edit on X was reverted by Dsimic". Chris Cunningham (user:thumperward) (talk) 08:46, 19 September 2015 (UTC)
- Hello! Your statement about the reverts simply isn't true and it just reflects some kind of your fixation. Could you, please, just refrain from posting comments until they become oriented toward the content (as the WP:NPA guideline clearly says), and toward making Wikipedia better? Also, your statement about me rejecting the WP:NOTBROKEN guideline is totally wrong, and it made me feel uncomfortable because I've in fact put that guideline into practice numerous times. With all that in mind, I'd appreciate if you would try to improve your collaboration skills, and stay away from hounding me in the meantime. Thank you. — Dsimic (talk | contribs) 06:28, 21 September 2015 (UTC)
Intel HD and Iris Graphics
Hi Dsimic,
I found that my recent edit on Intel HD Graphics has been undone. I'd like to know which part do you consider redundant?
I added those info because the HD Graphics performance of the same silicon, say GT2, differs with and are constrained by different SKU TDPs. And Intel obviously gave branding numbers proportional to performance. Adding TDP info helps explain why the same silicon differs in branding.
For the lack of refs, maybe we can add a link to Intel's spec, though the relation to branding numbers may be not that obvious at first sight. Jsli (talk) 04:30, 23 September 2015 (UTC)
- Hello! Regarding my revert on the Intel HD and Iris Graphics article, I've referred to the content you've added as redundant primarily because it is unreferenced. On second thought, the part in which I've referred to potential changes in assignments between GPU models and SKUs doesn't apply because Broadwell shouldn't see the release of any new SKUs. However, we would really need references, and with them in place I'd be more than happy to see your additions reintroduced into the article.
- It's pretty much obvious that we have a general lack of references in the Intel HD and Iris Graphics article, which applies particularly to the lists of available GPU models in different CPU microarchitectures. With all that in mind, please, just provide references that clearly show those assignments between different GPU models and Broadwell variants, and it will be truly great to have your addition as part of the article. Hope you agree. — Dsimic (talk | contribs) 05:27, 23 September 2015 (UTC)
Unlock the O+USA
This is Materialtechnology can you unprotected the O+ USA? Please!!! Materialtechnology (talk) 01:37, 27 September 2015 (UTC)
- Hello! Unfortunately, I'm not really sure what are you referring to, but you'd need to contact one of the Wikipeda administrators regarding the page protection questions. I don't have the rights required for protecting and unprotecting pages. — Dsimic (talk | contribs) 15:36, 27 September 2015 (UTC)
Restored copyvio content
Could you clarify this edit of yours? It appears you restored without explanation material that Hullaballoo Wolfowitz claims is copyvio. I agree (based on google-search for some phrases) that there appears to be extensive copyvio, which seems to be par-for-the-course for the editors who contributed that content. DMacks (talk) 05:27, 27 September 2015 (UTC)
- Hello! A few seconds after restoring the content that Hullaballoo Wolfowitz marked as a copyright violation and deleted, I've figured out regrettably that my edit went in with no explanation. By the way, IMHO, Hullaballoo Wolfowitz should've also provided a slightly better explanation while deleting the content. To help with the situation, I've also copyedited the article content a bit, which should've turned it away from being a straight copy-and-paste from some source. However, if the list of features in Android Honeycomb § Features section is really a copyright violation, I'd suggest that we either rewrite the list or delete the whole section, but not the whole article content. Hope you agree. — Dsimic (talk | contribs) 16:07, 27 September 2015 (UTC)
- Thanks for the info (and sorry this one slipped past my notifications for so long). Turns out some of the other prose was copyvio as well. I ripped out the most obvious of it. What's left seems like rearranged phrases of other sources, not sure it's close-paraphrase enough to be deletable on that aspect. But also, the whole appears to be by a set of block-evading socks, so by process it's all instantly deletable unless you want to adopt the content that remains as your own--up to you. I'm also not sure the subject is notable enough to merit an article rather than being redirected back to the main versions page, but that's solely an editorial decision, at which point I step back because this subject-area an is not one with which I'm familiar. DMacks (talk) 04:02, 11 October 2015 (UTC)
- No worries about the delay. Let's be straight, quality of the article remained rather low since its inception, as an unfortunate result of not attracting other editors. Though, the subject is truly notable enough to warrant Android Honeycomb as a separate article, and IMHO we should leave it "dangling" around for a few months, hoping that it will attract more editors willing to expand current stubby version of the article. If it isn't expanded in a few months, what's left is to turn it back into a redirect to Android version history § Honeycomb. Hope you agree. — Dsimic (talk | contribs) 05:33, 11 October 2015 (UTC)
- Sounds like a good plan, certainly no urgency in my mind. DMacks (talk) 05:37, 11 October 2015 (UTC)
- Thanks. Let's hope that it will attract other editors. — Dsimic (talk | contribs) 05:41, 11 October 2015 (UTC)
Your GA nomination of Row hammer
Hi there, I'm pleased to inform you that I've begun reviewing the article Row hammer you nominated for GA-status according to the criteria. ![]() This process may take up to 7 days. Feel free to contact me with any questions or comments you might have during this period. Message delivered by Legobot, on behalf of Cirt -- Cirt (talk) 06:41, 27 September 2015 (UTC)
This process may take up to 7 days. Feel free to contact me with any questions or comments you might have during this period. Message delivered by Legobot, on behalf of Cirt -- Cirt (talk) 06:41, 27 September 2015 (UTC)
- Thank you very much, Cirt! I'm here for all questions, suggestions, improvements to the article, etc. — Dsimic (talk | contribs) 16:10, 27 September 2015 (UTC)
- The article Row hammer you nominated as a good article has been placed on hold
 . The article is close to meeting the good article criteria, but there are some minor changes or clarifications needing to be addressed. If these are fixed within 7 days, the article will pass; otherwise it may fail. See Talk:Row hammer for things which need to be addressed. Message delivered by Legobot, on behalf of Cirt -- Cirt (talk) 02:40, 28 September 2015 (UTC)
. The article is close to meeting the good article criteria, but there are some minor changes or clarifications needing to be addressed. If these are fixed within 7 days, the article will pass; otherwise it may fail. See Talk:Row hammer for things which need to be addressed. Message delivered by Legobot, on behalf of Cirt -- Cirt (talk) 02:40, 28 September 2015 (UTC)
- The article Row hammer you nominated as a good article has been placed on hold
- The article Row hammer you nominated as a good article has passed
 ; see Talk:Row hammer for comments about the article. Well done! If the article has not already been on the main page as an "In the news" or "Did you know" item, you can nominate it to appear in Did you know. Message delivered by Legobot, on behalf of Cirt -- Cirt (talk) 03:41, 28 September 2015 (UTC)
; see Talk:Row hammer for comments about the article. Well done! If the article has not already been on the main page as an "In the news" or "Did you know" item, you can nominate it to appear in Did you know. Message delivered by Legobot, on behalf of Cirt -- Cirt (talk) 03:41, 28 September 2015 (UTC)
- The article Row hammer you nominated as a good article has passed
Prefix or suffix?
You know, I though all web requests have a "/" prefix. Like in "/enwiki/w/index.php?title=User_talk:Dsimic&action=edit§ion=new" or "/wiki/Special:Watchlist". As long as we are taking about requests, IMHO, it is a prefix. But when we are talking about the whole URL, it becomes an infix or, if alone, a suffix. Fleet Command (talk) 03:43, 28 September 2015 (UTC)
- Hello! You're right, it all depends on what the slash character is considered to be part of. After thinking more about my edit on Wikipedia:Manual of Style/Computing, I'd say that another wording tweak makes it unambiguous and more readable. Hope you agree. By the way, instructions say that "https://" should stay as part of the displayed URL, but the {{URL}} template automatically hides that scheme as well – should we not include "https://" as an example in the instructions? — Dsimic (talk | contribs) 07:37, 28 September 2015 (UTC)
Row hammer and wording improvements
Third one down in "Notes and exceptions". And "dates back" to a date in the past is a extra inessential superfluous unrequired unneeded surplus tautalogical redundancy. ;P Belle (talk) 12:06, 28 September 2015 (UTC)
- Hello! First of all, thank you very much for going through the Row hammer article and doing all those wording improvements! That's exactly what the article needed, simply because it's very easy not to see obvious areas for improvement after one (it's clear who :) spends a lot of time looking at the same wording. :) Regarding my edit, yes, I know what the WP:NUMERAL guideline says, but IMHO it's that "up to one memory cell in every 1,700 cells" reads much better, while "one" and "1,700" are rather spaced away from each other. :) Speaking about "dates back", it's another case of something that somehow "reads better" with a slight wording redundancy... Hopefully you'll be willing to let those slip through, and I hope that you're satisfied with the overall wording improvements we've done together. :) — Dsimic (talk | contribs) 15:15, 28 September 2015 (UTC)
- No problem! I don't know if you know but it was nominated for DYK which is why I looked at it. I disagree with a few a your "reads better" changes but I'm not going stomp back in there and change them all back to my preferemces as mostly it is just that: preferences. (apart from one that really sets my teeth on edge which I'm going to change in a minute, but if you do revert it I'm not going to fight you over it; you are probably bigger and stronger than me, so I'd have fight dirty and my mum said nice girls shouldn't bite or pull hair). I think where you've had to explain in the edit summaries then the article could benefit from explanation too (e.g. environment, each of them). Belle (talk) 16:36, 28 September 2015 (UTC)
- I wasn't aware of the DYK nomination, but it's nice to see that happening, and your DYK review conclusion that "it's cited like there's a sale on in the cite shop" brought a big smile to my face. :) In addition, you're right that referring to it as "row hammer effect" might be a bit confusing, but that's what it pretty much is; renaming the article to "Row hammer effect" wouldn't make much sense, though. You're also right that the explanations I've provided in edit summaries might be useful if they found their way into the article, and I'll see how to incorporate some of them. Oh, by the way, nice guys (especially nice 220-pounders) don't fight with girls or anyone else for that matter. :) — Dsimic (talk | contribs) 22:04, 28 September 2015 (UTC)
Redundant commas... or not?
About this one and others. You reverted sometime ago also (Stagefright?). I was going to ask you. I generally put commas after years and the Android article does too. Then I see also like "A 2015 report, states..", an exception where the comma is postponed. Maybe in my case I was wrong. This isn't a major deal, just not good that I keep putting them in (out of (misplaced?) habit, and you having to take out..).
I'm not natively English speaking (and your name doesn't sound like either, but it seems your English is excellent/better than mine) but I'm not sure that is the issue. I noticed e.g. SciAm doesn't use commas ("In 2015 something.."), can't remember a counter-example except here at the moment. This is a "style guide issue", and maybe more appropriate for encyclopedias.. I looked up another random article and it does use commas after years but not consistently..
While I'm here, could you look over Julia (programming language). I didn't put in the banners.. maybe they are fair (or not)? Even, besides that, do you know of any specific WP rules for computer [programming languages]? comp.arch (talk) 18:36, 3 October 2015 (UTC)
- Hello! The comma I've removed in this edit is entirely redundant and pretty much grammatically wrong, which I'll try to explain in more detail and with some background. Let's start with a few examples that illustrate it further by showing additional three variants of the same sentence, of which two actually need a comma:
- Another 2015 survey found that 40% of full-time professional developers see Android as the "priority" target platform.
- In another 2015 survey, it was found that 40% of full-time professional developers see Android as the "priority" target platform.
- In another 2015 survey, 40% of full-time professional developers saw Android as the "priority" target platform.
- Android was seen as the "priority" target platform by 40% of full-time professional developers that took another 2015 survey.
- By the way, example #1 (which is the variant used in the Android (operating system) article) should be the best choice because it avoids unnecessary passive voice. Furthermore, putting a comma in "A 2015 report, states..." simply doesn't make sense because it's essentially all the same sentence, without the "introductory" part that would require to be separated using a comma. When it's about the commas after years or dates, there are no specific grammar rules for using commas in such constructions; instead, it's all about the correct structure of the sentence as a whole, which is rather well described in this grammar summary. As you've guessed it right, which the userboxes on my user page clearly show, I'm not a native English speaker, but I keep working hard on improving my knowledge of the English language. :)
- Just had a look at the Julia (programming language) article, and in my opinion the {{Advert}} tag does apply due to rather frequent use of adverbs such as "effective", "good", "powerful", "elegant", "significant", "many", etc.; fixing that would be rather easy. At the same time, the {{Overly detailed}} tag might apply to a certain extent because the article could benefit from some trimming; for example, the Julia (programming language) § Displaying assembly code section seems rather redundant, IMHO, and should be integrated into another section while ditching the example. Lastly, the {{Primary sources}} tag is debatable for technical articles, but almost the majority (haven't actually counted) of references used in the article are primary and the WP:PRIMARY guideline shows no mercy. :) — Dsimic (talk | contribs) 03:06, 4 October 2015 (UTC)
- Thanks for answering. comp.arch (talk) 09:50, 5 October 2015 (UTC)
- You're welcome. :) — Dsimic (talk | contribs) 16:16, 5 October 2015 (UTC)
DYK for Row hammer
| On 12 October 2015, Did you know was updated with a fact from the article Row hammer, which you recently created, substantially expanded, or brought to good article status. The fact was ... that the row hammer effect has been used in some privilege escalation computer security exploits? The nomination discussion and review may be seen at Template:Did you know nominations/Row hammer. You are welcome to check how many page hits the article got while on the front page (here's how, live views, daily totals), and it may be added to the statistics page if the total is over 5,000. Finally, if you know of an interesting fact from another recently created article, then please feel free to suggest it on the Did you know talk page. |
Gatoclass (talk) 03:03, 12 October 2015 (UTC)
Millicode information
I added some information to Talk:Computer program#Microcode Programs Should Be Removed in answer to your question about millicode, but that section could be a bit tl;dr, so here's what I posted there:
- See the reference for and the external link in the millicode article. If you're willing to drop some coins into the change booth at the IEEE paywall, there's also Millicode in an IBM zSeries processor from the IBM Journal of Research and Development.
There's probably other stuff out there, including IBM papers in the Journal of Research and Development, if you're willing to spend USD 31 per paper. (IBM used to provide access to IBM JR&D papers for free from their site, but they've outsourced that to the IEEE now, and just about everything the IEEE has is behind a paywall, although they do at least make the 802 standards available for free.)
And, yes, it's architecturally the same sort of thing as PALcode - machine code executed in a special mode, with instructions implemented using {PAL,milli}code not being executable in that mode, and with access to special processor-dependent instructions and registers available - although, as Rwessel noted, DEC had a specific set of instructions architected as "traps to PALcode" in Alpha, while "this is done in millicode" is an implementation detail. DEC also did page table walks in PALcode rather than hardware; there's probably no reason IBM couldn't do that in some particular S/390 and z/Architecture implementations, but I don't know whether they did or not.
The millicode for POWER/PowerPC/Power ISA is just low-level ISA-dependent and possibly processor-dependent subroutines provided by the OS in a way that lets you quickly call them and get the version appropriate for the machine on which you're running. OS X, at least on PowerPC, had the "commpage", which was a region of the virtual address space shared between the kernel and userland, at a fixed virtual address, containing some routines where the implementation was processor-dependent for performance reasons; I think the routines were at fixed virtual addresses, so the code didn't have to know where they were. I seem to remember that a notion like this went back at least to Multics, with the pl1_operators segment containing routines to implement some operations in code generated by the PL/I compiler. Guy Harris (talk) 22:38, 12 October 2015 (UTC)
- Hello! I'm so thankful for your explanation, not just for this one, but for the numerous detailed explanations you've provided over time. I really, really appreciate your work! The papers you've linked above provide a good overview of millicode, which your explanation takes further, and I've shomehow managed not to have a look at our millicode article before. With all that, I may be able to say that I've learned, to a certain extent, something I pretty much wasn't aware of. :) Thank you once again! — Dsimic (talk | contribs) 13:43, 13 October 2015 (UTC)
ASF disambiguation
I had thought to add Atmel Software Framework to the ASF disambiguation page: I previously tried to look up the acronym and found nothing that fit. This meaning is covered in the first paragraph of Atmel application note AT08569 [1]. I frequently use Wikipedia to decipher odd acronyms, and I thought others might benefit from this addition. My first try included a reference to the app note but I got an automated 'we don't do that here'. This is my very first attempted contribution, obviously I don't have a clue. Isn't it worth having another expansion of an acronym even if it's redlinked? 172.88.224.142 (talk) 15:31, 14 October 2015 (UTC)
- Hello! As already described in my edit sumary, placing redlinks on disambiguation pages isn't prohibited in general, but that subject doesn't seem to have the potential for becoming covered by a separate article, in which case adding a redlink would be fine. Please see the WP:DABNOT guideline for more information on what isn't to be included on disambiguation pages. I know, all those guidelines may seem overwhelming at first, but that's what it is, Wikipedia has grown over time and having numerous rules is unavoidable; otherwise, it would be rather chaotic.
- In this case, my suggestion would be to find an appropriate article, add a description of the Atmel Software Framework to it (with references and everything), and then add a piped link to the ASF disambiguation page. Upon closer examination, the Atmel § Microcontrollers section seems to be the right destination, which you may want to expand further; went ahead and readded the "Atmel Software Framework" entry to the ASF disambiguation page, now pointing to an article section, and with a more brief description. Hope you agree with that. — Dsimic (talk | contribs) 16:15, 14 October 2015 (UTC)
- I think that will do very nicely. I don't think I'm ready to edit articles yet (I haven't even decided whether I want to remain anonymous!) although I do have some definite ideas about the Atmel AVR instruction set article -- the tabular data has improved immeasurably since I first saw it a couple of years ago but it is not _quite_ there yet. Thank you for your help and encouragement. 172.88.224.142 (talk) 17:42, 14 October 2015 (UTC)
- Thanks. You're more than welcome to contribute to the articles, but please consider going through the Wikipedia's Manual of Style first, which is a very good style guide on its own, even when not applied strictly to Wikipedia articles. I know, even looking at the sheer volume of information presented in the guide (and it also branches into numerous separate subguides, which have their own pages) may be slightly discouraging, but IMHO it's well worth it. Improving one's writing skills can only be beneficial in the long run, and the contributions made here are to, hopefully, stay around forever and help many people. :) — Dsimic (talk | contribs) 17:58, 14 October 2015 (UTC)
References
A barnstar for you!
|
|
The Editor's Barnstar |
| Seeing your edits pop up in my watchlist regularly gives me a warm fuzzy feeling that Wikipedia keeps getting better. Thanks! -- intgr [talk] 08:11, 16 October 2015 (UTC) |
- Thank you very much, intgr! Receiving a barnstar from a fellow editor creates a warm and fuzzy feeling that my contributions, as well as the contributions from other regulars, don't go unnoticed. :) Let's keep making Wikipedia better! — Dsimic (talk | contribs) 08:25, 16 October 2015 (UTC)
Halloween cheer!


Hello Dsimic:
Thanks for all of your contributions to improve Wikipedia, and have a happy and enjoyable Halloween!
– Codename Lisa (talk) 23:09, 30 October 2015 (UTC)
- Thank you very much, Codename Lisa! — Dsimic (talk | contribs) 23:12, 30 October 2015 (UTC)
MDPI
Hello, Dragan -- Glenn here, and I've got a beaut of a situation!
As we well know, Wikipedia maintains a set of "catchphrases" -- e.g., "sock puppet", "drive-by edit", etc. -- which are invaluable in identifying and characterizing otherwise shadowy behaviors which may be of particular harm -- or, in some cases, of particular benefit -- to Wikipedia. With this context, my question to you is as follows: is there a catchphrase which refers to the practice of re-emphasizing or re-iterating or re-cycling negative aspects of a subject which have since been discredited, corrected, and/or ameliorated by the passage of time -- and this with the effect of keeping said subject under a perpetual but undeserved cloud?
My reason for asking this question is that I would like to have a rationale for doing some corrective editing to the article on scholarly publisher MDPI, wherein there seems to me to be too great an emphasis on the fact that MDPI was at one time included on a list of "potential, possible, or probable predatory scholarly open-access publishers" maintained by a single individual -- the famous "Beall's list" -- even though its justification for being on the list has been disputed, and even though it has since been intentionally removed from said list.
Full disclosure: I have a stake in this matter, inasumuch as an MDPI journal has just published one of my scholarly papers; but by the same token, I have some actual experience with MDPI as the basis for my input -- and that experience has been ultimately positive in the sense of confirming MDPI's scholarly integrity.
But not only that, Dragan, in respect to my credentials as an editor of the MDPI article -- I have been in the very den of the lion! In short, I have just concluded a brief but telling correspondence with Jeffrey Beall himself -- who, to his great credit, makes his email address readily available, and who responds quickly; and I cite here, by way of documenting some of the points previously alluded to, my inititiating missive:
- From: Glenn Smith <gsmith@space-machines.com>
- Sent: Sunday, November 15, 2015 9:16 PM
- To: Beall, Jeffrey <Jeffrey.Beall@ucdenver.edu>
- Subject: MDPI
- Dear Associate Professor Beall,
- I'm sure you'll find this email quite typical -- but in today's world of manufactured crisis, typical can be good!
- I've recently had an article published by the MDPI journal Arts ( http://www.mdpi.com/2076-0752/4/3/75 ), and the peer review process seemed quite thorough to me, i.e., in addition to a brief and laudatory review from one reader, I received a substantial and cogent set of comments from two other readers, and the latter of which I had to address before my paper was accepted for publication. This, I realize, is but a single case; but if it represents the current rule rather than the exception at MDPI, one might suppose that the publisher deserves to be removed from your list; and indeed, when I visited your web site this evening, it seems that this has already been accomplished. Can you concur -- and are there any related details worthy of note?
- Regards,
- G. W. (Glenn) Smith
I do not feel it appropriate to reproduce Professor Beall's brief but gracious reply; but its import was to confirm, without futher detail, that MDPI was indeed taken off of his list as of 27 October 2015; and this further implies to me that MDPI's former presence on this list should become a footnote, as opposed to a major topic, within the Wikipedia article.
So, Dragan, I need that magic Wikipedia catchphrase; and if it does already exist, you -- with your wonderful acquired knowledge of English -- could come up with one! Synchronist (talk) 05:04, 17 November 2015 (UTC)
- Hey, Glenn! Long time no hear, hope everything is fine on your side... Just went through your published article and it describes rather interesting aspects of the advances in technology and related effects on the society. Good job! For example, it's very interesting that "a 1965 U.S. Senate subcommittee predicted a 21st century work week of 14 hours", which obviously backfired big time. :) Speaking about the catchphrase, it would be all about updating the article according to the WP:RS guideline, so "re-sourcing" might be an appropriate one. :) — Dsimic (talk | contribs) 15:27, 17 November 2015 (UTC)
- Dear Dragan, thanks for your enthusiasm regarding my paper! I am actually having some amazing success just now getting published. A more recent paper -- "Art, Aliens, and the Machine" -- has just been accepted by Leonardo, the leading techno-art journal, and as soon as it goes online I will let you know. I would like to think, however, that my "success" is simply a function of being a herald of the great -- and, let us hope, positive -- transformations which humanity is now undergoing; and I have not given up the hope that the two of us might be able to join together in some related, collective effort! [NB: My recent scholarly activities have also involved "visionary Slavic astronautics"! Just say the word, and I will blast you some details via email!]
- Returning, however, to the question of the moment, you are correct in thinking that a rigorous and comprehensive application of the Wikipedia "reliable sources" guidelines could result in an edited version of the MDPI article which no longer attempts to cast a perpetual cloud over that publisher (after all, both Nature and Science have found it necessary to retract bogus papers!); but it could be best to take a more "step-by-step" approach. For example, the second paragraph of the introduction of the MDPI article brings up the fact that MDPI was once -- but is no longer! -- on the Beall "index". This is surely an example of "guilt by innuendo"; and so, if one were to "flag" this paragraph with one of the standard Wikipedia warning messages, what would that message be? Synchronist (talk) 05:08, 18 November 2015 (UTC)
- You're welcome, and I'm looking forward to reading more of your published articles! However, I'm quite suspicious regarding the chances for the modern society to escape from the increasingly escalating consumerism... It isn't only about the consumerism of technology and various products, but (which is much more frightening to me) about the consumerism of thoughts and resulting lack of true contributions to the humanity as a whole. Even the current job market shows alarming signs – there are numerous open high-tech jobs, but there are increasingly fewer people qualified and knowledgeable enough for actually doing those jobs.
- Speaking about the MDPI article and its lead section, the right maintenance templates might be
{{Disputed}}and{{Inadequate lead}}, placed in combination with starting a discussion on the article's talk page. However, IMHO doing the following steps, if that would be possible at the moment, should be better instead of simply tagging the article:- The MDPI § Inclusion in Beall's list section should be updated accordingly, providing adequate, reliable sources, which are mandatory, as we know.
- The second paragraph of the article's lead section should be edited and expanded to provide more details about the article as a whole, a part of which might be the fact that MDPI has been but is no longer included on the Jeffrey Beall's list.
- Hope you agree. — Dsimic (talk | contribs) 06:11, 18 November 2015 (UTC)
- This is encouraging! Someone else has already made the precise changes I had in mind for the MDPI article, and, in particular, removing the Beall's list reference from the intro, where it cast a shadow over the entire article!!! So there is a god! (Dragan -- check me out on this wavelength: gsmith@space-machines.com ) Synchronist (talk) 05:05, 23 November 2015 (UTC)
- Sounds great, and there's God for sure. :) — Dsimic (talk | contribs) 07:11, 23 November 2015 (UTC)
More coverage of erasure coding and distributed placement in RAID topic?
Hi Dsimic
Saw you contributing heavily to RAID topic. Just sat through another presentation where vendor claimed "RAID is dead" due to long rebuilds and need for higher fault resilience levels. I disagree...IMO RAID is a broad technical strategy that does not mandate XOR math, does not limit to 2 or 3 'parity' fragments, does not mandate rigid mapping of a Volume to specific disks, does not mandate 1:1 recovery of failed disks.
My question to you: Do you agree? Should the RAID topic be brought forward with coverage of modern fault-resilience techniques?
- use of erasure coding
- distributed placement algorithms
- parallel recovery from disk failure
A given vendor might choose not to use the term 'RAID' in the context of their object store, but that's a Marketing decision. I think the classic definition of RAID still applies.
Davis471 (talk) 15:20, 25 November 2015 (UTC) Mike Davis akropilot@gmail.com
- Hello! IMHO, RAID is far away from becoming dead technology, at least in broad terms. Separate RAID layers, such as those in hardware RAID controllers and layered software implementations, might be reaching their end-of-life stages, but integrated RAID approaches, such as those in Btrfs and ZFS file systems, are just becoming used more broadly. As of why RAID simply can't go belly up, it's all about the amount of existing software that has no clue what to do with distributed object-level storage: just think of various mail daemons, relational databases, operating systems themselves that simply need traditional storage, etc.
- Speaking about modern fault-resilience techniques, I'd say those might fit better in the Object storage article, for example, but having more information in the RAID article would also be a good thing. Hope you agree. — Dsimic (talk | contribs) 15:58, 25 November 2015 (UTC)
Regarding Haswell second branch unit
Hi Dsimic,
Please see the p25 of Haswell hotchips presentation, titled Haswell Execution Unit Overview. It said there is a "New Branch Unit" sharing with 4th ALU under port6. I think this new branch unit is a branch execution unit, not a branch prediction unit.
Henry Huang